使用python抓取百度搜索结果时不成功,怎么回事?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了使用python抓取百度搜索结果时不成功,怎么回事?相关的知识,希望对你有一定的参考价值。
如题,运行后显示为“百度安全验证的页面”!我又用了自建opener和更换UA的方式运行,同样显示这个页面?请问是什么原因?该如何解决?请各位老师给予解答,谢谢!!!
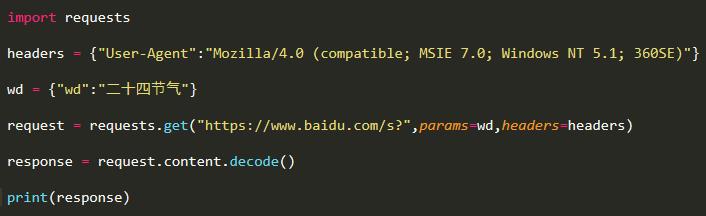
百度搜索有专门的接口,使用相应的API接口调用吧。你这直接调用它的主页,需要解决很多问题的。
这段代码访问的是百度主页,这里头不仅仅只是表面上的这些参数在起作用,还有cookie,session等在起作用,百度会通过这些信息对搜索信息进行整理,用于生成大数据集(比如哪个区域的人偏爱查询哪些词之类的),你的机子没有这些信息,调用百度主页进行搜索就会有问题。
请参照以下代码
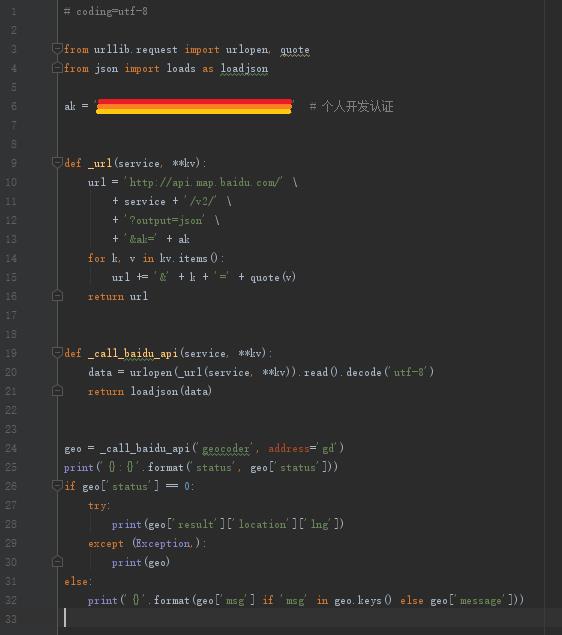
起调百度地图API
参考技术A 异步加载(Ajax)动态渲染的网页,可能还要调用js函数去解密返回结果。如果用模拟浏览器(selemium库)获取渲染后的网页源码,难度会低很多。 参考技术B 网络不给力是安全验证了,我也在学,不过问题我已经解决,你要根据你正常浏览器里的 header 添加,如果实在不会,那就把出现的 所有 header 内容加进去,下面是我测试写的代码,我这边是可以采集的,50多页完全没问题,不会出现网络不给力,自己参考下import urllib.request
import re
keywords = 'python爬虫'
keywords = urllib.request.quote(keywords)
pages = 0 #页码数
pat_res = [] #定义集合,接收采集标题
fh = open('spider\\title.txt','a') #打开文件,以追加方式
for i,j in enumerate(range(0,50)):
url = 'https://www.baidu.com/s?wd=' + keywords + '&pn='+str(pages)+'&oq=' + keywords + '&ie=utf-8&usm=2&rsv_idx=1&rsv_pq=e4f7528300143ded&rsv_t=f9e5fE0a3Gy7yaLQX6JFJhnR6I1jYnAfL2t5SCcGSoJSAr3LogHutYZxP%2FY'
opener = urllib.request.build_opener()
Bdpagetype = ('Bdpagetype', '2')
Bdqid = ('Bdqid', '0xe4fd4d4f003005ff')
Cache_Control = ('Cache-Control', 'private')
Ckpacknum = ('Ckpacknum', '2')
Ckrndstr = ('Ckrndstr', 'f003005ff')
Connection = ('Connection', 'Keep-Alive')
Content_Encoding = ('Content-Encoding', 'gzip')
Content_Type = ('Content-Type', 'text/html;charset=utf-8')
Strict_Transport_Security = ('Strict-Transport-Security', 'max-age=172800')
Traceid = ('Traceid', '1576546102028799668216500429611456267775')
Transfer_Encoding = ('Transfer-Encoding', 'chunked')
Vary = ('Vary', 'Accept-Encoding')
X_Ua_Compatible = ('X-Ua-Compatible', 'IE=Edge,chrome=1')
Accept = ('Accept',
'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9')
Referer = ('Referer', 'https://www.baidu.com')
Sec_Fetch_Mode = ('Sec-Fetch-Mode', 'navigate')
Sec_Fetch_Site = ('Sec-Fetch-Site', 'same-origin')
Sec_Fetch_User = ('Sec-Fetch-User', '?1')
Upgrade_Insecure_Requests = ('Upgrade-Insecure-Requests', '1')
User_Agent = ('User-Agent',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.79 Safari/537.36 Edg/79.0.309.51')
opener.addheaders = [Bdpagetype]
opener.addheaders = [Bdqid]
opener.addheaders = [Cache_Control]
opener.addheaders = [Ckpacknum]
opener.addheaders = [Ckrndstr]
opener.addheaders = [Connection]
opener.addheaders = [Content_Encoding]
opener.addheaders = [Content_Type]
opener.addheaders = [Strict_Transport_Security]
opener.addheaders = [Traceid]
opener.addheaders = [Transfer_Encoding]
opener.addheaders = [Vary]
opener.addheaders = [X_Ua_Compatible]
opener.addheaders = [Accept]
opener.addheaders = [Referer]
opener.addheaders = [Sec_Fetch_Mode]
opener.addheaders = [Sec_Fetch_Site]
opener.addheaders = [Sec_Fetch_User]
opener.addheaders = [Upgrade_Insecure_Requests]
opener.addheaders = [User_Agent]
print('正在爬第:'+str(i)+'页')
data = opener.open(url)
print('当前地址:'+str(data.geturl()))
code = data.read().decode('utf-8')
pat = 'data-tools=\'"title":"(.*?)"' #提取标题正则
print('成功获取数据,等待入库')
res_temp = re.compile(pat).findall(code)
pat_res += res_temp
print('添加入库成功')
pages = pages+10
print('采集完毕,等待写出文件...')
for w,j in enumerate(pat_res):
fh.write(str(pat_res[w])+'\n')
print('写入文件完毕!')
fh.close() 参考技术C 重搜索一下,提取下验证码试一下 参考技术D 把https改成http试试
Python+Selenium+PhantomJs爬虫 怎么抓取弹出新标签页的内容
参考技术A 在工程中新建一个Python Package(包),右键点击src, New>PydevPackage,选择源文件路径及输入包名: 在_init_.py,输入print (“Hello World”),按F9即可看到输出结果,说明开发环境安装成功!本回答被提问者采纳以上是关于使用python抓取百度搜索结果时不成功,怎么回事?的主要内容,如果未能解决你的问题,请参考以下文章
现在手机打开百度搜索就是此URL非法指向百度IP 怎么回事 求解决 怎么办呐