人工智能机器学习深度学习 三者关系
Posted 你的莽莽没我的好吃
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了人工智能机器学习深度学习 三者关系相关的知识,希望对你有一定的参考价值。
目录
2.1、人工智能(ArtificiaI Intelligence)
1、AI ML DL关系
为了赋予计算机以人类的理解能力与逻辑思维,诞生了人工智能(Artificial Intelligence, Al)这一学科。在实现人工智能的众多算法中,机器学习是发展较为快速的一支。机器学习的思想是让机器自动地从大量的数据中学习出规律,并利用该规律对未知的数据做出预测。在机器学习的算法中,深度学习是特指利用深度神经网络的结构完成训练和预测的算法。
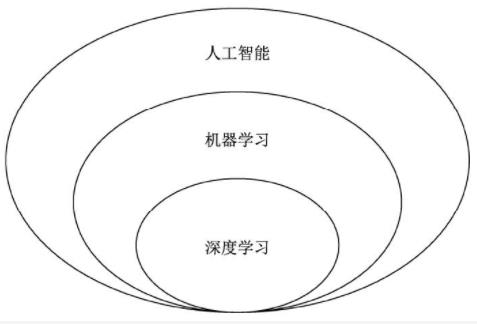
机器学习是实现人工智能的途径之一,而深度学习则是机器学习的算法之一。如果把人工智能比喻成人类的大脑,机器学习则是人类通过大量数据来认知学习的过程,而深度学习则是学习过程中非常高效的一种算法。
2、发展历程
2.1、人工智能(ArtificiaI Intelligence)
人工智能的概念最早来自于1956年的计算机达特茅斯会议,其本质是希望机器能够像人类的大脑一样思考,并作出反应。由于极具难度与吸引力,人工智能从诞生至今,吸引了无数的科学家与爱好者投入研究。搭载人工智能的载体可以是近年来火热的机器人、自动驾驶车辆,甚至是一个部署在云端的智能大脑。
根据人工智能实现的水平,我们可以进一步分为3种人工智能:
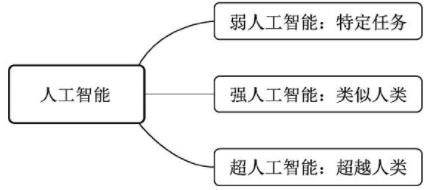
- 弱人工智能(Artificial Narrow Intelligence,ANI):擅长某个特定任务的智能。例如语言处理领域的谷歌翻译,让该系统去判断一张图片中是猫还是狗,就无能无力了。再比如垃圾邮件的自动分类、自动驾驶车辆、手机上的人脸识别等,当前的人工智能大多是弱人工智能。
- 强人工智能:在人工智能概念诞生之初,人们期望能够通过打造复杂的计算机,实现与人一样的复杂智能,这被称做强人工智能,也可以称之为通用人工智能(Artificial General Intelligence,AGI)。这种智能要求机器像人一样,听、说、读、写样样精通。目前的发展技术尚未达到通用人工智能的水平,但已经有众多研究机构展开了研究。
- 超人工智能(Artificial Super Intelligence,ASI):在强人工智能之上,是超人工智能,其定义是在几乎所有领域都比人类大脑聪明的智能,包括创新、社交、思维等。人工智能科学家Aaron Saenz曾有一个有趣的比喻,现在的弱人工智能就好比地球早期的氨基酸,可能突然之间就会产生生命。超人工智能不会永远停留在想象之中。
2.2、机器学习(Machine Learning)
机器学习是实现人工智能的重要途径,也是最早发展起来的人工智能算法。与传统的基于规则设计的算法不同,机器学习的关键在于从大量的数据中找出规律,自动地学习出算法所需的参数。
机器学习最早可见于1783年的贝叶斯定理中。贝叶斯定理是机器学习的一种,根据类似事件的历史数据得出发生的可能性。在1997年,IBM开发的深蓝(DeepBlue)象棋电脑程序击败了世界冠军。当然,最令人振奋的成就还当属2016年打败李世石的AlphaGo。
机器学习算法中最重要的就是数据,根据使用的数据形式,可以分为三大类:监督学习(Supervised Learning)、无监督学习(Unsupervised Learning)与强化学习(Reinforcement Learning)。
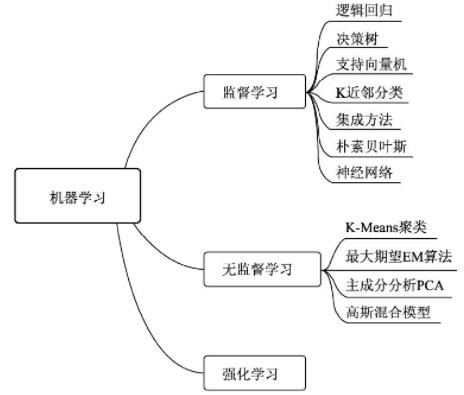
- 监督学习:通常包括训练与预测阶段。在训练时利用带有人工标注标签的数据对模型进行训练,在预测时则根据训练好的模型对输入进行预测。监督学习是相对成熟的机器学习算法。监督学习通常分为分类与回归两个问题,常见算法有决策树(Decision Tree,DT)、支持向量机(Support Vector Machine,SVM)和神经网络等。
- 无监督学习:输入的数据没有标签信息,也就无法对模型进行明确的惩罚。无监督学习常见的思路是采用某种形式的回报来激励模型做出一定的决策,常见的法有K-Means与主成分分析(Principall Component Analysis,PCA)。
- 强化学习:让模型在一定的环境中学习,每次行动会有对应的奖励,目标是使奖励最大化,被认为是走向通用人工智能的学习方法。常见的强化学习有基于价值、策略与模型3种方法。
2.3、深度学习(Deep Learning)
深度学习是机器学习的技术分支之一,主要是通过搭建深层的人工神经网络(Artificial Neural Network)来进行知识的学习,输入数据通常较为复杂、规模大、维度高。深度学习可以说是机器学习问世以来最大的突破之一。
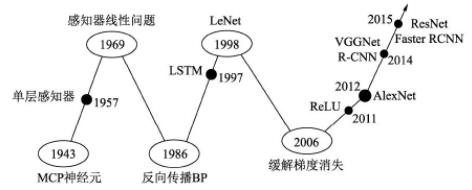
最早的神经网络可以追溯到1943年的MCP(McCulloch and Pitts)人工神经元网络,希望使用简单的加权求和与激活函数来模拟人类的神经元过程。在此基础上,1958年的感知器(Perception)模型使用了梯度下降算法来学习多维的训练数据,成功地实现了二分类问题,也掀起了深度学习的第一次热潮。下图代表了一个最简单的单层感知器,输入有3个量,通过简单的权重相加,再作用于一个激活函数,最后得到了输出y。
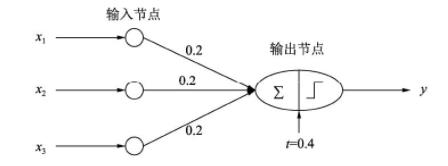
然而,1969年,Minsky证明了感知器仅仅是一种线性模型,对简单的亦或判断都无能为力,而生活中的大部分问题都是非线性的,这直接让学者研究神经网络的热情难以持续,造成了深度学习长达20年的停滞不前。1986年,深度学习领域“三驾马车”之一的Geoffrey Hinton创造性地将非线性的Sigmoid函数应用到了多层感知器中,并利用反向传播(Back propagation)算法进行模型学习,使得模型能够有效地处理非线性问题。1998年,“三驾马车”中的卷积神经网络之父Yann LeCun发明了卷积神经网络LeNet模型,可有效解决图像数字识别问题,被认为是卷积神经网络的鼻祖。
然而在此之后的多年时间里,深度学习并没有代表性的算法问世,并且神经网络存在两个致命问题:一是Sigmoid在函数两端具有饱和效应,会带来梯度消失问题;另一个是随着神经网络的加深,训练时参数容易陷入局部最优解。这两个弊端导致深度学习陷入了第二次低谷。在这段时间内,反倒是传统的机器学习算法,如支持向量机、随机森林等算法获得了快速的发展。
2006年,Hinton提出了利用无监督的初始化与有监督的微调缓解了局部最优解问题,再次挽救了深度学习,这一年也被称为深度学习元年。2011年诞生的ReLU激活函数有效地缓解了梯度消失现象。
真正让深度学习迎来爆式发展的当属2012年的AlexNet网络,其在lmageNet图像分类任务中以“碾压”第二名算法的姿态取得了冠军。深度学习从此一发不可收拾,VGGNet、ResNe等优秀的网络接连问世,并且在分类、物体检测、图像分割等领域渐渐地展现出深度学习的实力,大大超过了传统算法的水平。
当然,深度学习的发展离不开大数据、GPU及模型这3个因素,如图所示。
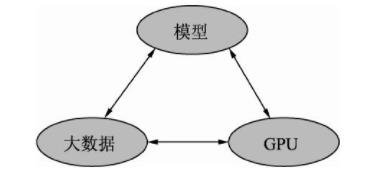
- 大数据:当前大部分的深度学习模型是有监督学习,依赖于数据的有效标注。例如,要做一个高性能的物体检测模型,通常需要使用上万甚至是几十万的标注数据。数据的积累也是一个公司深度学习能力雄厚的标志之一,没有数据,再优秀的模型也会面对无米之炊的尴尬。
- GPU:当前深度学习如此“火热”的一个很重要的原因就是硬件的发展,尤其是GPU为深度学习模型的快速训练提供了可能。深度学习模型通常有数以千万计的参数,存在大规模的并行计算,传统的以逻辑运算能力著称的CPU面对这种并行计算会异常缓慢,GPU以及CUDA计算库专注于数据的并行计算,为模型训练提供了强有力的工具。
- 模型:在大数据与GPU的强有力支撑下,无数研究学者的奇思妙想,催生出了VGGNet、ResNet和FPN等一系列优秀的深度学习模型,并且在学习任务的精度、速度等指标上取得了显著的进步。
根据网络结构的不同,深度学习模型可以分为:
- 卷积神经网络(Convolutional Neural Network,CNN)
- 循环神经网络(Recurrent Neural Network,RNN)
- 生成式对抗网络(Generative Adviserial Network,GAN)
以上是关于人工智能机器学习深度学习 三者关系的主要内容,如果未能解决你的问题,请参考以下文章