机器学习笔记一. 特征工程
Posted Gettler•Main
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习笔记一. 特征工程相关的知识,希望对你有一定的参考价值。
sklearn 库
加载数据集
- 小数据集
sk.datasets.load_iris();
- 大数据集
sk.datasets.fetch_20newsgroups()
数据集返回值
datasets.base.Bunch(继承自字 典类型)
使用数据集
# 数据集使用
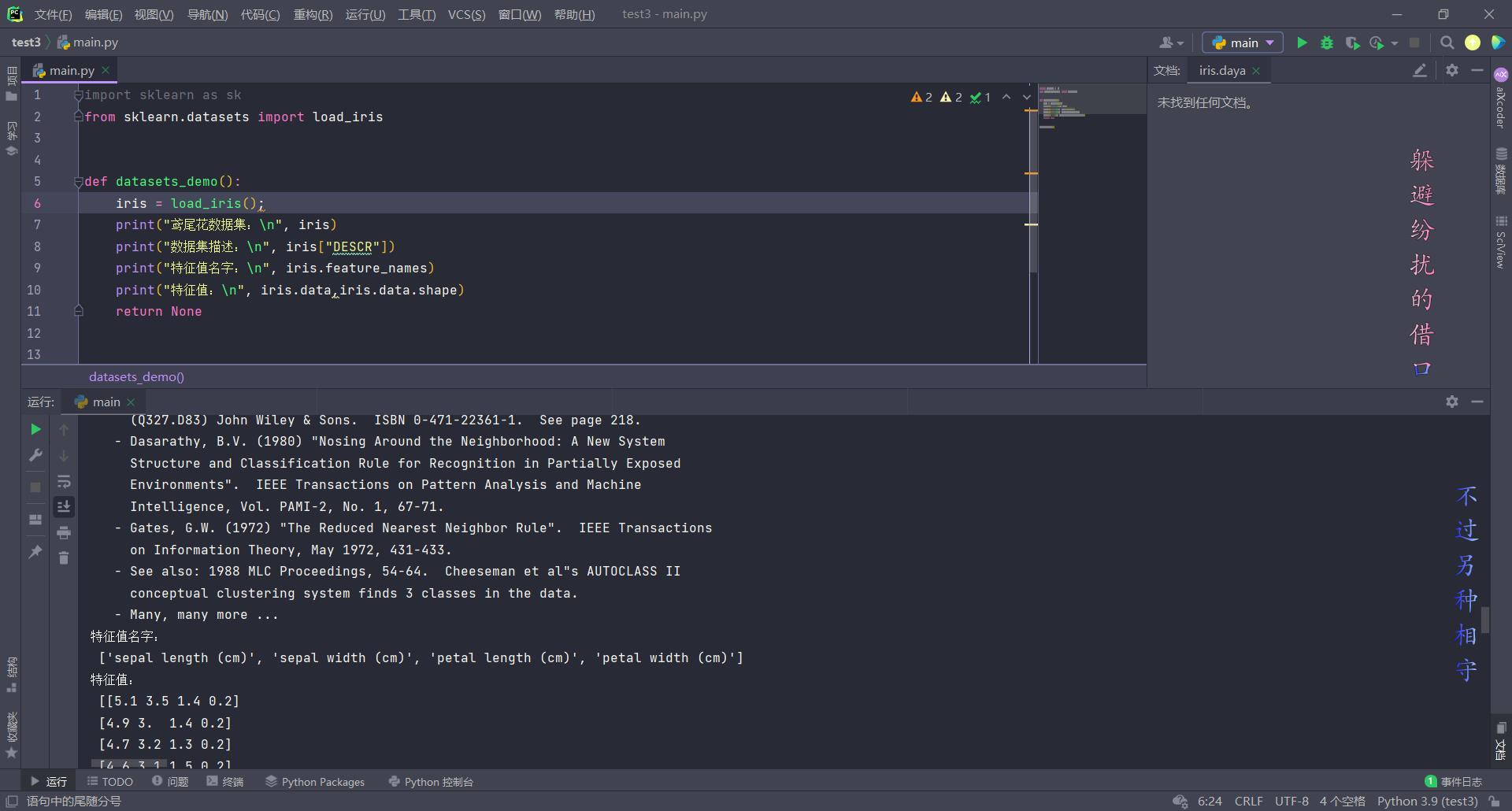
def datasets_demo():
iris = load_iris();
print("鸢尾花数据集:\\n", iris)
print("数据集描述:\\n", iris["DESCR"])
print("特征值名字:\\n", iris.feature_names)
print("特征值:\\n", iris.data, iris.data.shape)
# 数据集划分
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2, random_state=22)
print("特征值:\\n", x_train, x_train.shape)
return None
特征工程
特征抽取
特征提取API
sklearn.feature_extration
字典特征提取
sklearn.feature_extration.DictVectorizer()
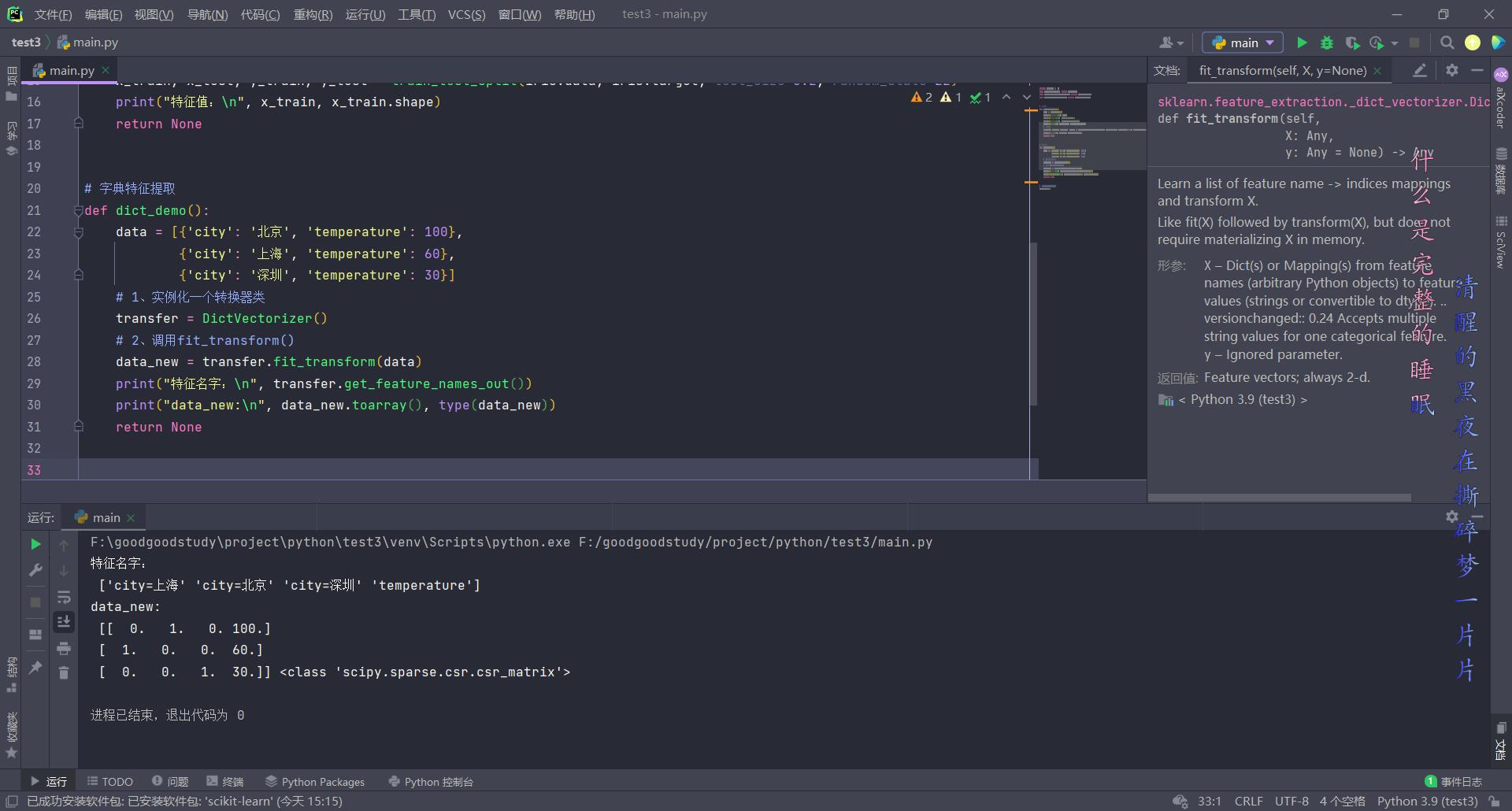
# 字典特征提取
def dict_demo():
data = ['city': '北京', 'temperature': 100, 'city': '上海', 'temperature': 60, 'city': '深圳', 'temperature': 30]
# 1、实例化一个转换器类
transfer = DictVectorizer()
# 2、调用fit_transform()
data_new = transfer.fit_transform(data)
print("特征名字:\\n", transfer.get_feature_names_out())
print("data_new:\\n", data_new.toarray(), type(data_new))
return None
文本特征提取
CountVectorizer
统计每个样本特征此出现的个数
英文文本特征提取:
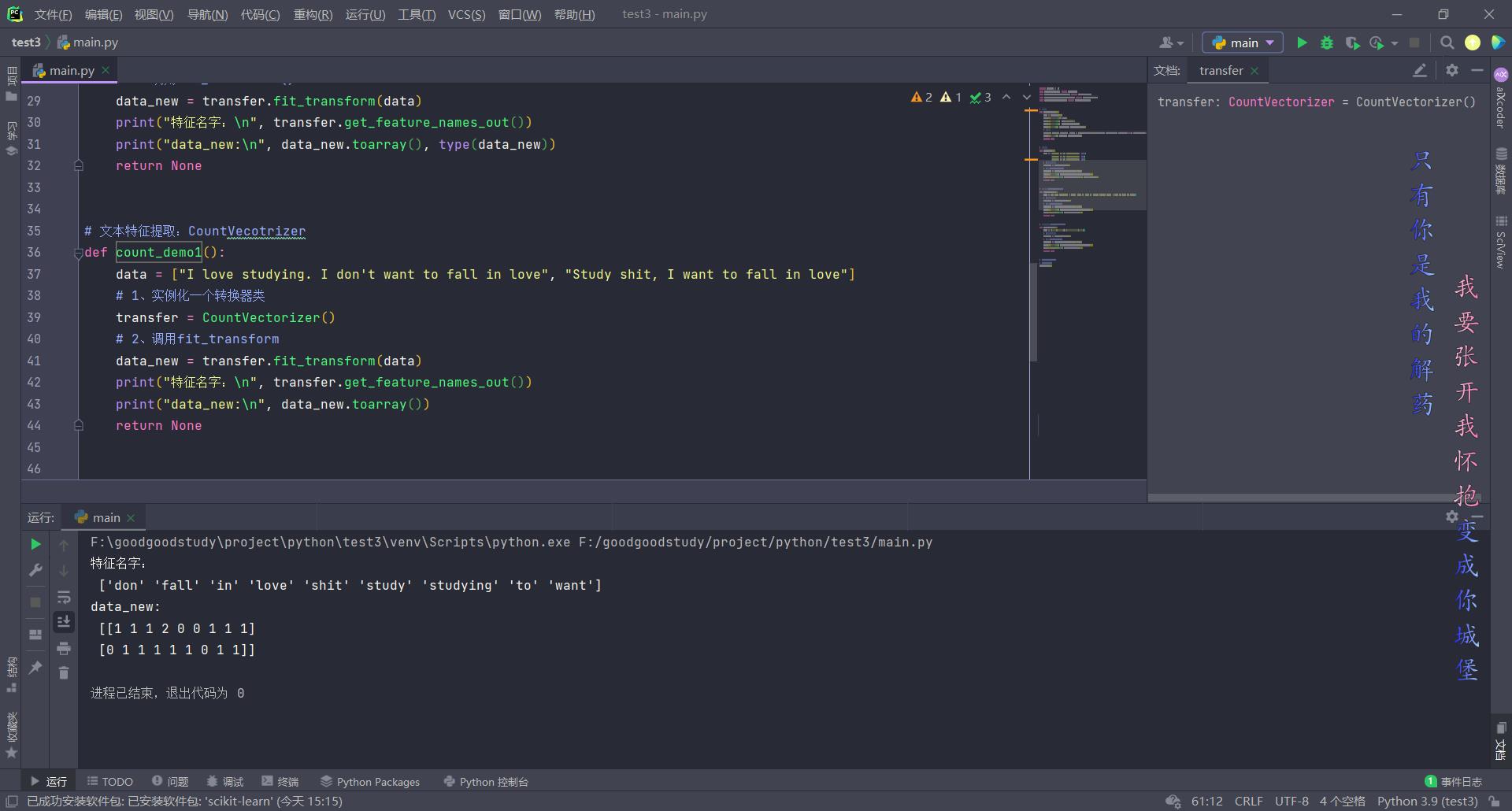
# 文本特征提取:CountVecotrizer
def count_demo1():
data = ["I love studying. I don't want to fall in love", "Study shit, I want to fall in love"]
# 1、实例化一个转换器类
transfer = CountVectorizer()
# 2、调用fit_transform
data_new = transfer.fit_transform(data)
print("特征名字:\\n", transfer.get_feature_names_out())
print("data_new:\\n", data_new.toarray())
return None
中文文本特征提取:
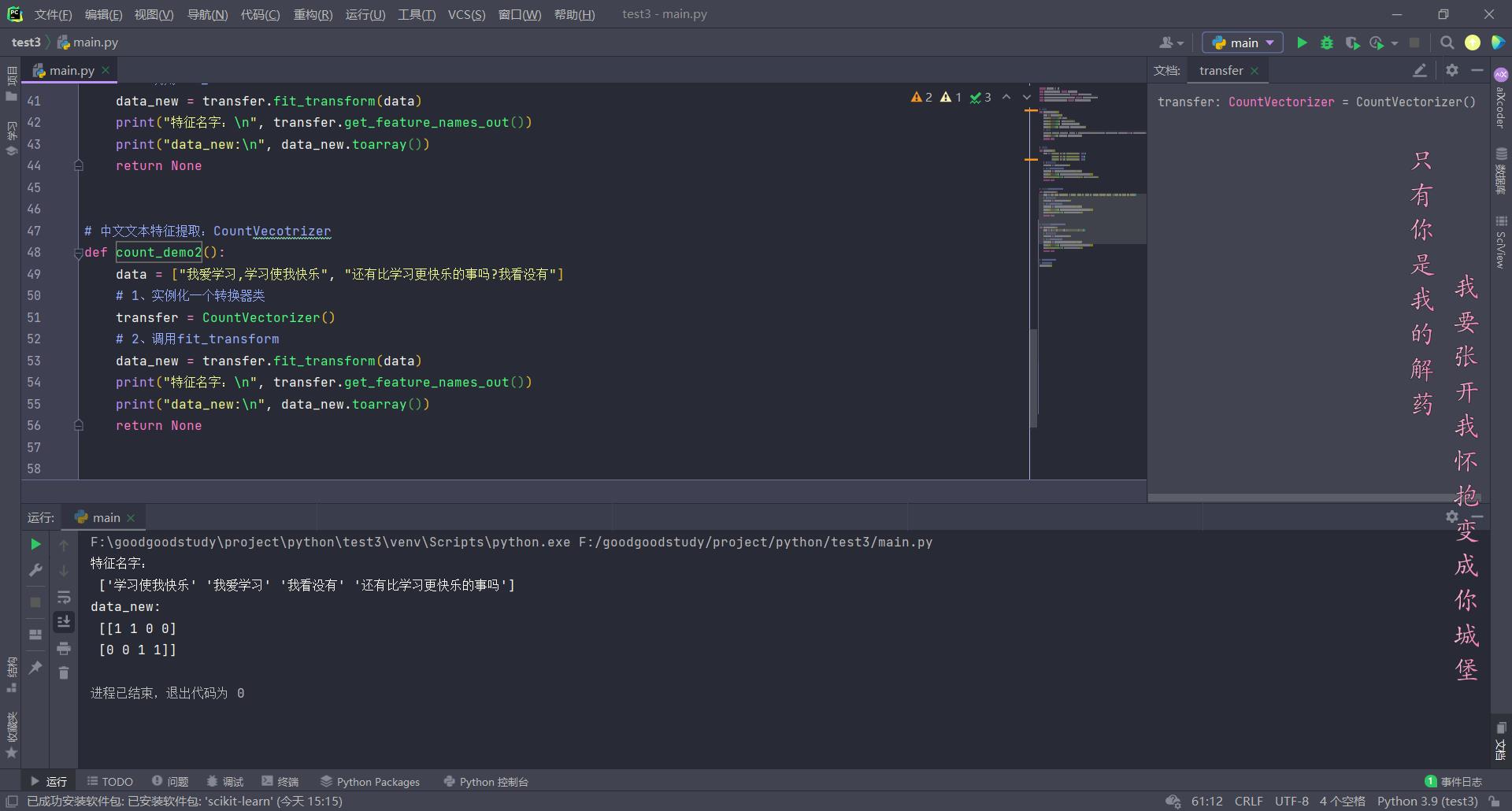
# 中文文本特征提取:CountVecotrizer
def count_demo2():
data = ["我爱学习,学习使我快乐", "还有比学习更快乐的事吗?我看没有"]
# 1、实例化一个转换器类
transfer = CountVectorizer()
# 2、调用fit_transform
data_new = transfer.fit_transform(data)
print("特征名字:\\n", transfer.get_feature_names_out())
print("data_new:\\n", data_new.toarray())
return None
中文文本调用jieba库分词后特征提取:
def cut_word(text):
return " ".join(list(jieba.cut(text)))
# 中文文本特征提取,自动分词
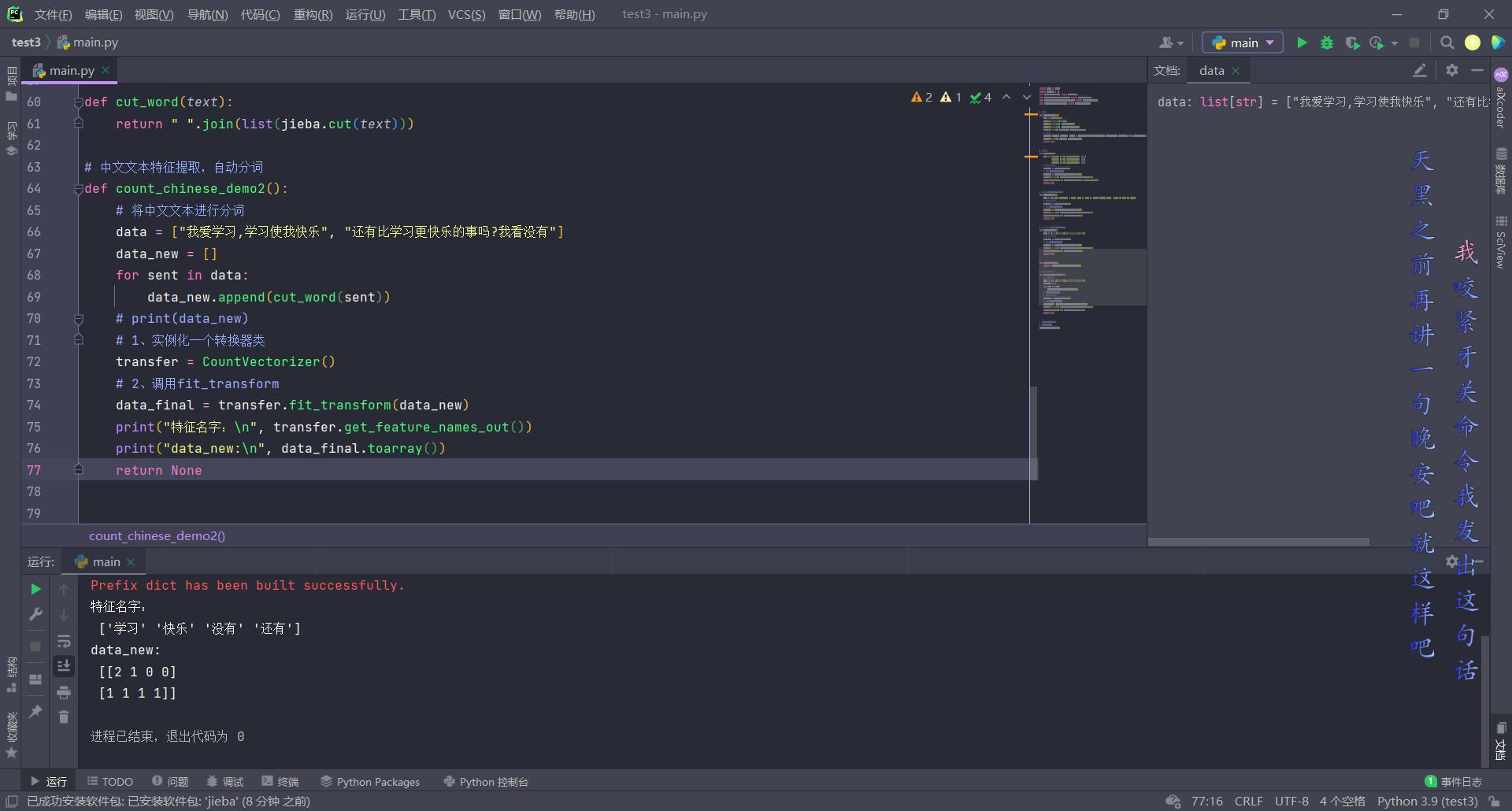
def count_chinese_demo2():
# 将中文文本进行分词
data = ["我爱学习,学习使我快乐", "还有比学习更快乐的事吗?我看没有"]
data_new = []
for sent in data:
data_new.append(cut_word(sent))
# print(data_new)
# 1、实例化一个转换器类
transfer = CountVectorizer()
# 2、调用fit_transform
data_final = transfer.fit_transform(data_new)
print("特征名字:\\n", transfer.get_feature_names_out())
print("data_new:\\n", data_final.toarray())
return None
TfidfVectorizer
TF-IDF 重要程度
TF —— 词频
IDF —— 逆向文档频率
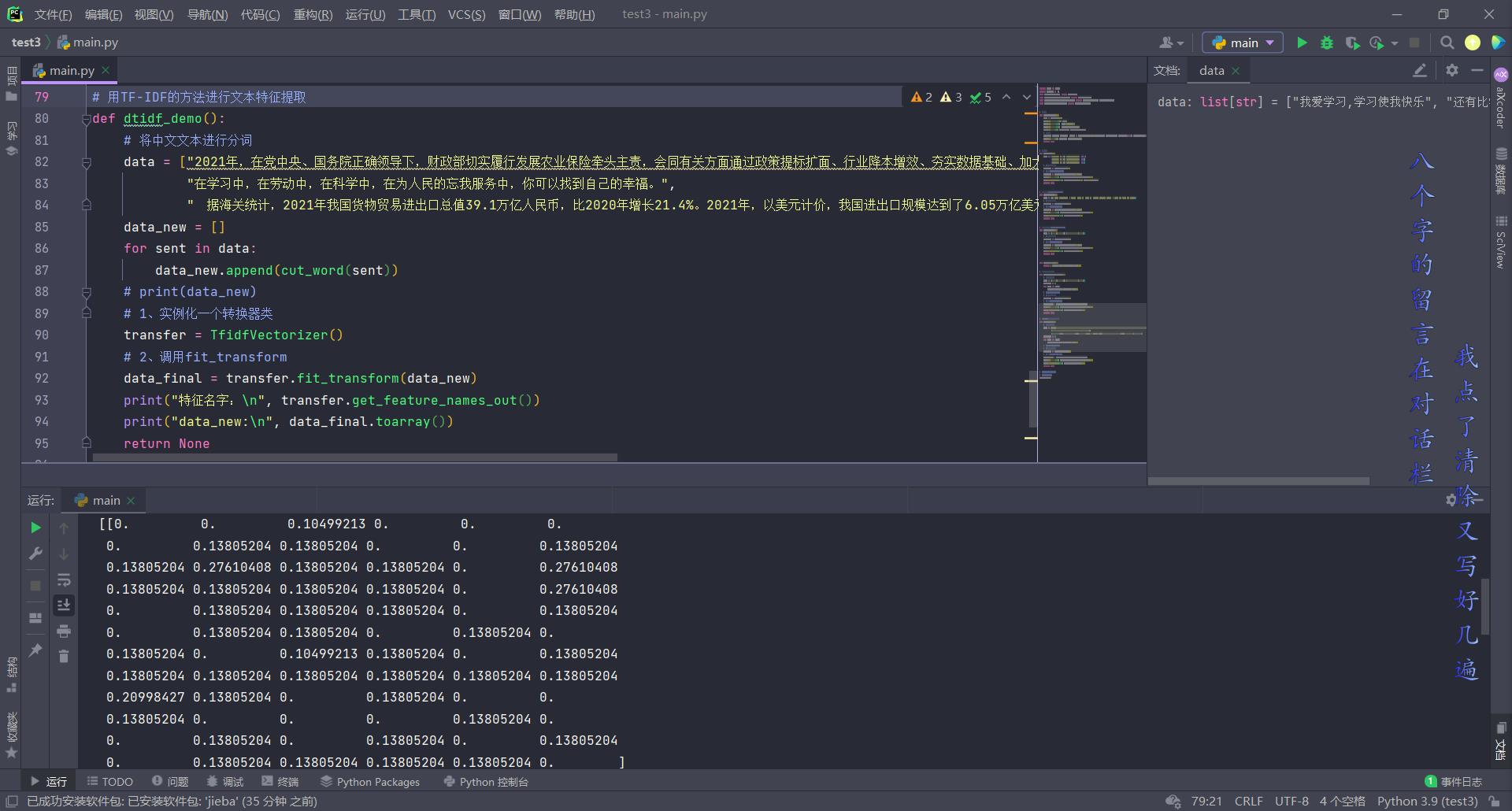
# 用TF-IDF的方法进行文本特征提取
def dtidf_demo():
# 将中文文本进行分词
data = ["2021年,在党中央、国务院正确领导下,财政部切实履行发展农业保险牵头主责,会同有关方面通过政策提标扩面、行业降本增效、夯实数据基础、加大宣传力度,推动我国农业保险持续快速发展,引导金融保险资源服务“三农”,服务保障国家粮食安全作用进一步凸显。",
"在学习中,在劳动中,在科学中,在为人民的忘我服务中,你可以找到自己的幸福。",
" 据海关统计,2021年我国货物贸易进出口总值39.1万亿人民币,比2020年增长21.4%。2021年,以美元计价,我国进出口规模达到了6.05万亿美元,首次突破6万亿美元关口。"]
data_new = []
for sent in data:
data_new.append(cut_word(sent))
# print(data_new)
# 1、实例化一个转换器类
transfer = TfidfVectorizer()
# 2、调用fit_transform
data_final = transfer.fit_transform(data_new)
print("特征名字:\\n", transfer.get_feature_names_out())
print("data_new:\\n", data_final.toarray())
return None
特征预处理
归一化
通过对原始数据进行变换把数据映射到(默认为[0,1])之间
通过最大值最小值映射,鲁棒性较差
# 归一化
def minmax_demo():
# 1、获取数据
data = pd.read_csv("data.txt")
data = data.iloc[:, :3]
print("data:\\n", data)
# 2、实例化一个转换器类
transfer = MinMaxScaler(feature_range=[2, 3])
# 3、调用fit_transform
data_new = transfer.fit_transform(data)
print("data_new:\\n", data_new)
return None

标准化
通过对原始数据进行变换把数据变换到均值为0,标准差为1的范围内
# 标准化
def stand_demo():
# 1、获取数据
data = pd.read_csv("data.txt")
data = data.iloc[:, :3]
print("data:\\n", data)
# 2、实例化一个转换器类
transfer = StandardScaler()
# 3、调用fit_transform
data_new = transfer.fit_transform(data)
print("data_new:\\n", data_new)
return None

特征降维
特征选择
Filter 过滤式
-
方差选择法:低方差特征过滤
-
相关系数:特征与特征之间的相关程度
- 皮尔逊相关系数:0.9942
- 特征之间相关性较高
- 选其一
- 加权求和
- 主成分分析
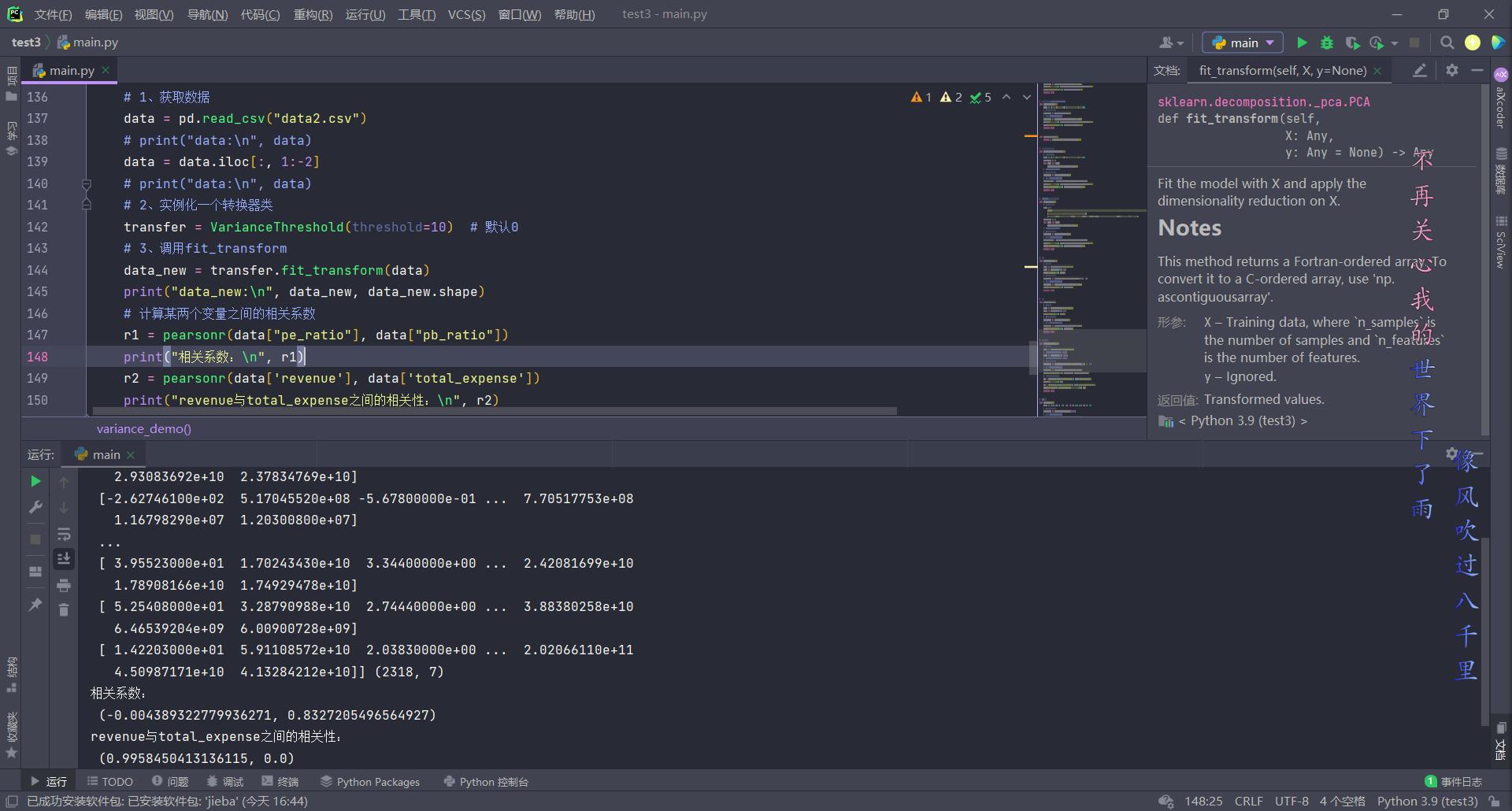
# 过滤低方差特征
def variance_demo():
# 1、获取数据
data = pd.read_csv("data2.csv")
# print("data:\\n", data)
data = data.iloc[:, 1:-2]
# print("data:\\n", data)
# 2、实例化一个转换器类
transfer = VarianceThreshold(threshold=10) # 默认0
# 3、调用fit_transform
data_new = transfer.fit_transform(data)
print("data_new:\\n", data_new, data_new.shape)
# 计算某两个变量之间的相关系数
r1 = pearsonr(data["pe_ratio"], data["pb_ratio"])
print("相关系数:\\n", r1)
r2 = pearsonr(data['revenue'], data['total_expense'])
print("revenue与total_expense之间的相关性:\\n", r2)
return None
Embedded 嵌入式
主成分分析 PCA
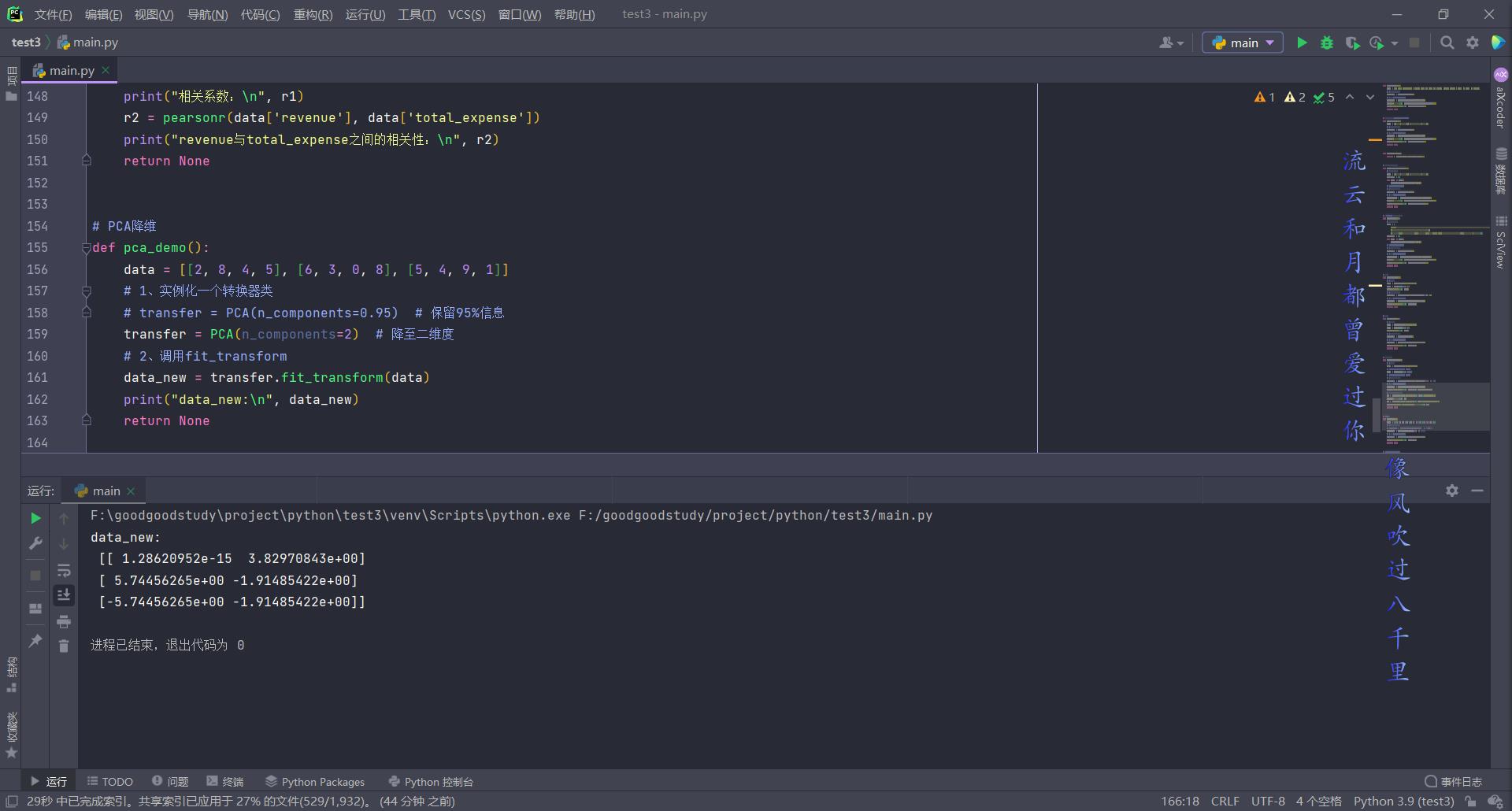
# PCA降维
def pca_demo():
data = [[2, 8, 4, 5], [6, 3, 0, 8], [5, 4, 9, 1]]
# 1、实例化一个转换器类
# transfer = PCA(n_components=0.95) # 保留95%信息
transfer = PCA(n_components=2) # 降至二维度
# 2、调用fit_transform
data_new = transfer.fit_transform(data)
print("data_new:\\n", data_new)
return None
以上是关于机器学习笔记一. 特征工程的主要内容,如果未能解决你的问题,请参考以下文章