Mysql的count查询,如果没有结果返回NULL,怎么让他返回0
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Mysql的count查询,如果没有结果返回NULL,怎么让他返回0相关的知识,希望对你有一定的参考价值。
参考技术A count()函数正常情况没有数据,返回的就是0呀?有问题么或者你试试select ifnull(count(id),0) from tablename本回答被提问者采纳
MySQL里的COUNT
count(*)、count(1)、count(主键)、count(字段)的执行效率
在没有where条件的情况下
MyISAM引擎返回结果会比InnoDB快上很多,主要是因为MyISAM会单独记录了表的总行数,而InnoDB没有这么做。
为什么没有这么做呢?主要InnoDB支持了事务的原因,在事务中不同的版本上查询出来的结果是不一样的。例如表中总行数现有10条,事务A启动后未查询,这时启动事务B对表插入一条数据。这时候事务A查询表行数为10条,事务B查询得行数为11条。InnoDB默认使用了可重复读的隔离级别。
mysql中有个show table status的查询,这个查询结果中记录了表行数的字段Rows。查询执行速度很快,但这个结果不可以用,因为这个结果是mysql采样估算得来的,比较不准确。
对表数据为54万的数据进行查询比较,其中a字段未加索引可为空,d字段未加索引不可为空,b字段加了索引不可为空,c字段加了索引可为空。
执行结果耗时:
[SQL]
-- 1
select count(*) from cyj_test ;
受影响的行: 0
时间: 0.086ms
[SQL]
-- 2
select count(1) from cyj_test;
受影响的行: 0
时间: 0.083ms
[SQL]
-- 3
select count(id) from cyj_test;
受影响的行: 0
时间: 0.101ms
[SQL]
-- 4 未加索引可为空
select count(a) from cyj_test;
受影响的行: 0
时间: 0.635ms
[SQL]
-- 5 加了索引不可为空
select count(b) from cyj_test;
受影响的行: 0
时间: 0.101ms
[SQL]
-- 6 加了索引可为空
select count(c) from cyj_test;
受影响的行: 0
时间: 0.129ms
[SQL]
-- 7 未加索引不可为空
select count(d) from cyj_test;
受影响的行: 0
时间: 0.426ms根据执行时间可得执行效率为:count(*)≈count(1)>count(主键)≈>count(加了索引不可为空字段)>count(加了索引可为空字段)>count(未加了索引不可为空字段)>count(未加了索引可为空字段)
EXPLAIN结果
-- 1
EXPLAIN select count(*) from cyj_test ;| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | cyj_test | index | idex_b | 4 | 544598 | 100 | Using index |
-- 2
EXPLAIN select count(1) from cyj_test;| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | cyj_test | index | idex_b | 4 | 544598 | 100 | Using index |
-- 3
EXPLAIN select count(id) from cyj_test;| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | cyj_test | index | idex_b | 4 | 544598 | 100 | Using index |
-- 4 未加索引可为空
EXPLAIN select count(a) from cyj_test;| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | cyj_test | ALL | 544598 | 100 |
-- 5 加了索引不可为空
EXPLAIN select count(b) from cyj_test;| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | cyj_test | index | idex_b | 4 | 544598 | 100 | Using index |
-- 6 加了索引可为空
EXPLAIN select count(c) from cyj_test;| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | cyj_test | index | idex_c | 123 | 544598 | 100 | Using index |
-- 7 未加索引不可为空
EXPLAIN select count(d) from cyj_test;| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | cyj_test | ALL | 544598 | 100 |
EXPLAIN结果得知未加索引的会遍历全表扫描得到查询结果,没有走索引,所以4和7查询速度会比其他慢了很多。
count(*)、count(1)、count(id)、count(b)都走了index_b的索引,count(c)走了index_c的索引。这里你可能会有几个问题要问:
1、count(*)、count(1)、count(id)为什么不走主键索引而走了index_b呢?
因为mysql默认使用了InnoDB,索引是B+树的形式。这里主键索引的页子节点存的是数据,而普通索引树存的是主键值,所以主键索引肯定比普通索引树的大很多,优化器会使用找到的那棵最小的树来进行遍历,所以走了
index_b。
2、那为什么走了index_b而不是走了index_c呢?
从
EXPLAIN结果得知,index_b的key_len为4,index_c的key_len为123,key_len表示索引中使用的字节数,所以肯定使用index_b的数据量更小。
从EXPLAIN我们简单得知了没加索引会比加了索引的查询慢了很多,那么都加了索引的情况下会是怎么样的呢?其实是mysql对count()、count(1)、count(id)、count(b)、count(c)的判断各不相同导致的。注:取值和不取值会影响执行速度,因为取值会对数据行进度解析以得到想要的字段。
count(*)
InnoDB遍历整张表,但不取值,count(*)肯定不为空,按行累加就行了。
count(1)
InnoDB遍历整张表,但不取值,server层对于每一行数据返回1,判断1不可能空,按行累加。
count(id)
InnoDB遍历整张表,把每一行的id取出来返回给server层,server层判断不可能为空,按行累加。
count(不可为空字段)
InnoDB遍历整张表,把每一行的这个字段取出来返回给server层,server层判断不可能为空,按行累加。
count(可空字段)
InnoDB遍历整张表,把每一行的这个字段取出来返回给server层,server层判断是不是为空,不为空的按行累加。
count(判断 or null)
假设存在一张子任务表,表主要信息如下:
CREATE TABLE `app_task_child` (
`task_child_id` varchar(40) NOT NULL,
`status` int(11) NOT NULL DEFAULT '1' COMMENT '1.待提交;2.审核中;3.已提交;4.已归档;',
`task_id` varchar(40) DEFAULT NULL COMMENT '母任务',
PRIMARY KEY (`task_child_id`),
KEY `FK6m...` (`task_id`),
CONSTRAINT `FK6m...` FOREIGN KEY (`task_id`) REFERENCES `app_task` (`task_id`),
) ENGINE=InnoDB DEFAULT CHARSET=utf8;现在有一个需求:统计出各任务下的子任务数、已归档数、审核中数的数据。
SELECT
t.task_id AS taskId,
count(t.task_child_id) AS taskChildNum,
count(t.STATUS = 4) AS ongoingNum,
count(t.STATUS = 2) AS archiveNum
FROM
app_task_child t
GROUP BY
t.task_id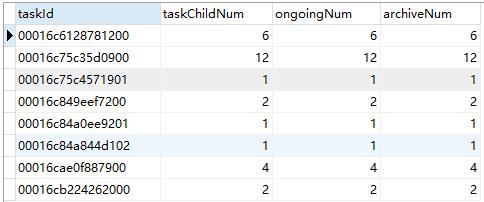
上面的SQL会查询出图一的数据来,这数据一看就知道不对,已归档数和审核中的数量肯定错了。文章上面大概有说到一个意思:count计算的是除了NULL值,其他数据都会加1,例如0或false也都是会加数量1。
t.STATUS = ?判断为false或true,所以count总为加1,导致结果总跟子任务数是一样的。那么就需要想办法当为false时把结果置为NULL。例如有下面两种方法都能得到正确的结果:
-- 方法一
SELECT SQL_NO_CACHE
t.task_id AS taskId,
count(t.task_child_id) AS taskChildNum,
count(IF(t. STATUS = 4, true, NULL)) AS ongoingNum,
count(IF(t. STATUS = 2, true, NULL)) AS archiveNum
FROM
app_task_child t
GROUP BY
t.task_id-- 方法二
SELECT
t.task_id AS taskId,
count(t.task_child_id) AS taskChildNum,
count(t.STATUS = 4 or NULL) AS ongoingNum,
count(t.STATUS = 2 or NULL) AS archiveNum
FROM
app_task_child t
GROUP BY
t.task_id方法一的不难理解,这里不进行说明。
方法二(判断 or NULL)可以理解为当判断为0时,会走or后面的表达式,当判断为1时,不走or后面的表达式。判断为1的直接count为1,判断为0时进行NULL的表达式判断,而且0 or NULL为NULL。
在mysql中的or和and判断不像java那样,更像是JavaScript这种弱类型语言的判断,可以把NULL直接进行判断。例如下图中的判断结果
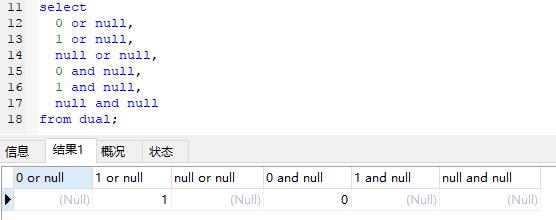
count(判断 or null)性能怎么样?
对面上的表进行加status索引。
ALTER TABLE `app_task_child`
ADD INDEX `index_status` (`status`) USING BTREE ;执行sql
-- 写法一
EXPLAIN SELECT
t.task_id AS taskId,
count(t.task_child_id) AS taskChildNum,
count(t.STATUS = 2 or null) AS archiveNum
FROM
app_task_child t
GROUP BY
t.task_id;结果为:
| ... | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|
| ... | index | FK6m... | FK6m... | 123 | 39 | 100 |
执行sql
-- 写法二
EXPLAIN SELECT
t.task_id AS taskId,
count(t.task_child_id) AS taskChildNum,
count(*) AS archiveNum
FROM
app_task_child t
where t.status = 2
GROUP BY
t.task_id;结果为:
| ... | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|
| ... | ref | FK6m...,index_status | index_status | 123 | const | 1 | 100 | Using index condition; Using temporary; Using filesort |
就只单单从type字段一个为ref一个为index就可得知写法二性能完爆写法一(可以参考别人的文章)
。那么为什么上面不用写法二呢?实际开发中统计的往往不只统计一个num,可能会统计八九个。所以如果使用写法二,需要写八九个SQL去执行,而写法一只需要一条SQL搞定。还有就是这时写法二花费在数据库连接上的损耗加起来往往是比写法一性能更差些。
如果不在status字段上加索引,EXPLAIN比较出来的结果也是方法二性能稍微好一点,这点大家可以自己试一下
以上是关于Mysql的count查询,如果没有结果返回NULL,怎么让他返回0的主要内容,如果未能解决你的问题,请参考以下文章
mysql 如何实现 count 超过1000条记录 就返回 1000