40 | insert语句的锁为什么这么多?
Posted 久违の欢喜
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了40 | insert语句的锁为什么这么多?相关的知识,希望对你有一定的参考价值。
mysql45讲
实践篇
40 | insert语句的锁为什么这么多?
insert … select 语句
CREATE TABLE `t` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`c` int(11) DEFAULT NULL,
`d` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `c` (`c`)
) ENGINE=InnoDB;
insert into t values(null, 1,1);
insert into t values(null, 2,2);
insert into t values(null, 3,3);
insert into t values(null, 4,4);
create table t2 like t

如果 session B 先执行,由于这个语句对表 t 主键索引加了 (-∞,1]这个 next-key lock,会在语句执行完成后,才允许 session A 的 insert 语句执行。
但如果没有锁的话,就可能出现 session B 的 insert 语句先执行,但是后写入 binlog 的情况。于是,在 binlog_format=statement 的情况下,binlog 里面就记录了这样的语句序列:
insert into t values(-1,-1,-1);
insert into t2(c,d) select c,d from t;
这个语句到了备库执行,就会把 id=-1 这一行也写到表 t2 中,出现主备不一致。
insert 循环写入
示例 1:
insert into t2(c,d) (select c+1, d from t force index(c) order by c desc limit 1);
这个语句的加锁范围是表 t 索引 c 上的 (3,4]和 (4,supremum]这两个 next-key lock,以及主键索引上 id=4 这一行。
执行流程是从表 t 中按照索引 c 倒序,扫描第一行,拿到结果写入到表 t2 中,因此整条语句的扫描行数是 1。

示例 2:
insert into t(c,d) (select c+1, d from t force index(c) order by c desc limit 1);


explain 结果里的 rows=1 是因为受到了 limit 1 的影响。
执行这个语句前后查看 Innodb_rows_read 的结果。
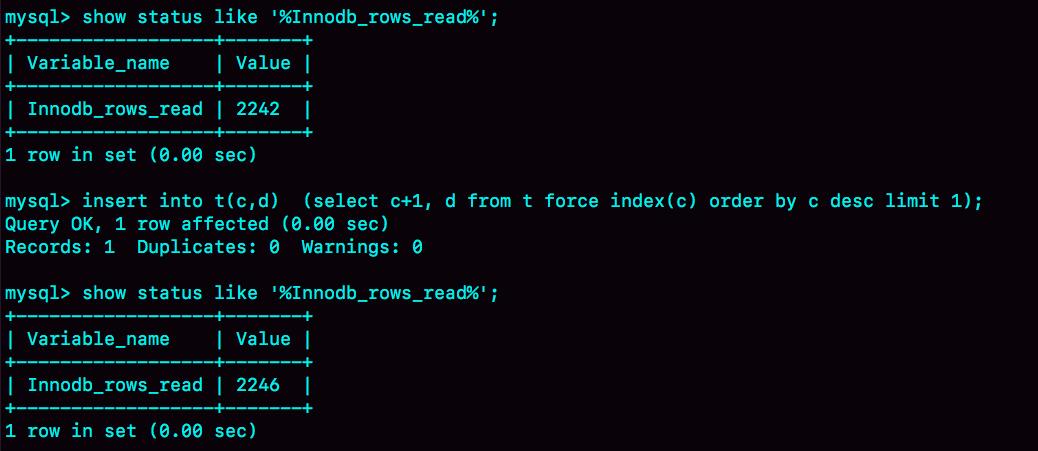
这个语句执行前后,Innodb_rows_read 的值增加了 4。因为默认临时表使用 Memory 引擎,所以这 4 行查的都是表 t,也就是说对表 t 做了全表扫描。
示例 2 的执行流程如下:
- 创建临时表,表里有两个字段 c 和 d;
- 按照索引 c 扫描表 t,依次取 c=4、3、2、1,然后回表,读到 c 和 d 的值写入临时表。这时,Rows_examined=4;
- 由于语义里面有 limit 1,所以只取了临时表的第一行,再插入到表 t 中。这时,Rows_examined 的值加 1,变成了 5。
这个语句会导致在表 t 上做全表扫描,并且会给索引 c 上的所有间隙都加上共享的 next-key lock。所以,这个语句执行期间,其他事务不能在这个表上插入数据。
这个语句的执行需要临时表,是因为这类一边遍历数据,一边更新数据的情况,如果读出来的数据直接写回原表,就可能在遍历过程中,读到刚刚插入的记录,新插入的记录如果参与计算逻辑,就跟语义不符。
由于这个语句没有在子查询中就直接使用 limit 1,从而导致了这个语句的执行需要遍历整个表 t。
可以考虑使用内存临时表来做这个优化。使用内存临时表优化时,语句序列的写法如下:
create temporary table temp_t(c int,d int) engine=memory;
insert into temp_t (select c+1, d from t force index(c) order by c desc limit 1);
insert into t select * from temp_t;
drop table temp_t;
insert 唯一键冲突

session A 执行的 insert 语句,发生唯一键冲突的时候,并不只是简单地报错返回,还在冲突的索引上加了锁。 一个 next-key lock 就是由它右边界的值定义的。这时候,session A 持有索引 c 上的 (5,10]共享 next-key lock(读锁),从作用上来看,这样做可以避免这一行被别的事务删掉。
如果冲突的是主键索引,就加记录锁,唯一索引才加 next-key lock。MySQL 8.0.16 及之后修改了这个bug,这两类索引冲突加的都是 next-key lock。
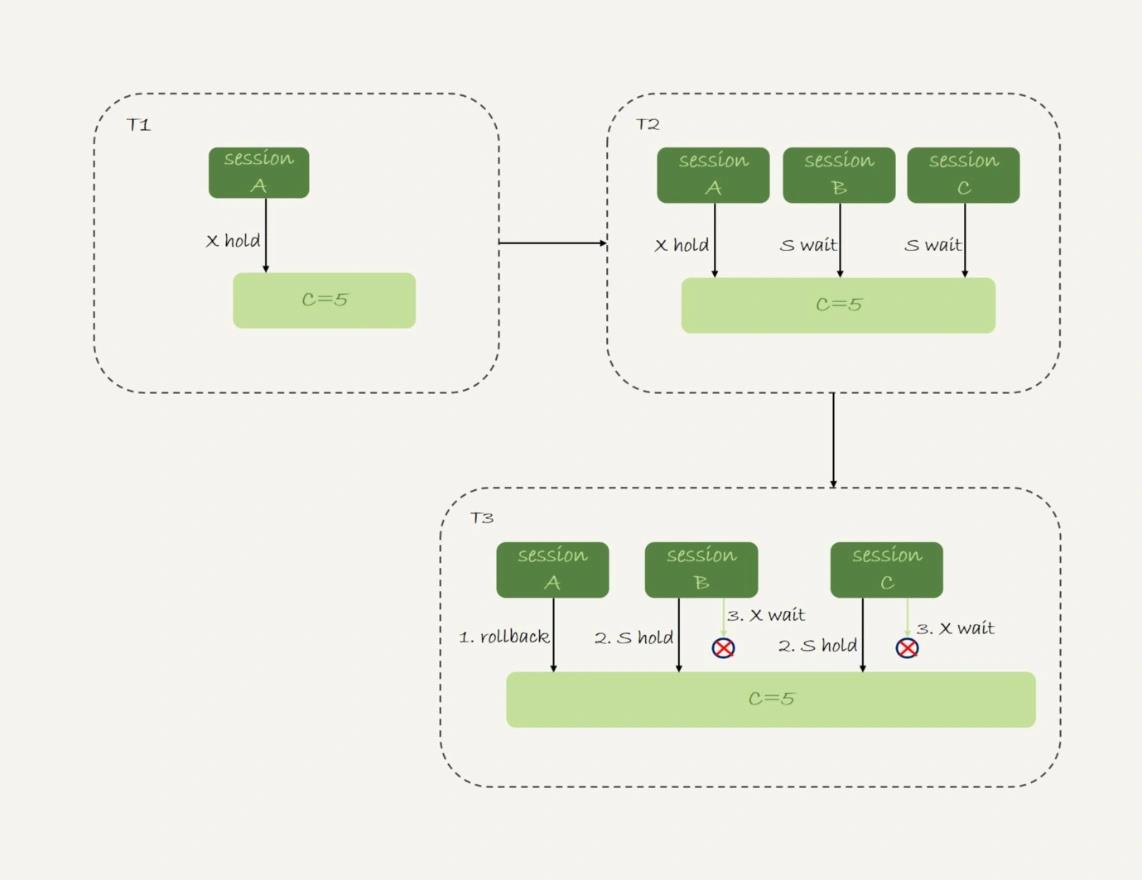
经典的死锁场景

死锁产生的逻辑如下:
- 在 T1 时刻,启动 session A,并执行 insert 语句,此时在索引 c 的 c=5 上加了记录锁。注意,这个索引是唯一索引,因此退化为记录锁;
- 在 T2 时刻,session B 要执行相同的 insert 语句,发现了唯一键冲突,加上读锁;同样地,session C 也在索引 c 上,c=5 这一个记录上,加了读锁;
- T3 时刻,session A 回滚。这时候,session B 和 session C 都试图继续执行插入操作,都要加上写锁。两个 session 都要等待对方的行锁,所以就出现了死锁。
上面这个例子是主键冲突后直接报错,如果是改写成以下语句:
insert into t values(11,10,10) on duplicate key update d=100;
就会给索引 c 上 (5,10] 加一个排他的 next-key lock(写锁)。
insert into … on duplicate key update 这个语义的逻辑是,插入一行数据,如果碰到唯一键约束,就执行后面的更新语句。
注意,如果有多个列违反了唯一性约束,就会按照索引的顺序,修改跟第一个索引冲突的行。
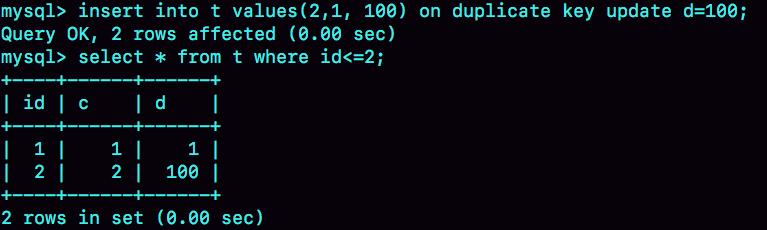
实际上,真正更新的只有一行,只是在代码实现上,insert 和 update 都认为自己成功了,update 计数加了 1, insert 计数也加了 1。
以上是关于40 | insert语句的锁为什么这么多?的主要内容,如果未能解决你的问题,请参考以下文章