『数据结构与算法』之时间复杂度与空间复杂度,看这一篇就够啦
Posted 快乐的小何~
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了『数据结构与算法』之时间复杂度与空间复杂度,看这一篇就够啦相关的知识,希望对你有一定的参考价值。
⭐️大一新生小何,还在学习当中,欢迎交流指正~


前言
复杂度分析是数据结构和算法中最重要的知识点,毫不夸张的说,这就是数据结构与算法学习的核心所在。你学会了它你就入的了门,你学不会它,你就永远不知道门儿在哪。学习数据结构与算法的第一课,一定要选复杂度分析,所以,在我看来,这是数据结构与算法中最重要的知识点,且不接受任何反驳
一、复杂度分析
它的出现是想着花更少的时间和更少的存储来解决问题
为了“更少的时间和更少的存储”,复杂度分析为此而生。
简单来说,就是你需要提前写好算法代码和编好测试数据,然后在计算机上跑,通过最后得出的运行时间判断算法时效的高低,这里的运行时间就是我们日常的时间
事后统计法太依赖计算机的软件和硬件等性能。代码在 不同处理器运算速度不同,更不用说不同的操作系统、不同的编程语言等软件方面,就算是在同一台电脑上,用的所有的东西都一样,内存的占用或者是 CPU 的使用率也会造成运行时间的差异
可以看出,我们需要一个不依赖于性能和规模等外力影响就可以估算算法效率、判断算法优劣的度量指标,而复杂度分析天生就是干这个的,这也是为什么我们要学习并必须学会复杂度分析!
二、时间复杂度
1.大o表示法
时间复杂度,也就是指算法的运行时间
大 O 表示法,表示的是算法有多快。(也读作big O)
这个多快,不是说算法代码真正的运行时间,而是代表着一种趋势,一种随着数据集的规模增大,算法代码运行时间变化的一种趋势。用O表示时间复杂度,一般记作 O(f(n))。
有T(n) = O(f(n)),其中 f(n) 是算法代码执行的总步数,也叫操作数。

n 作为数据集大小,它可以取 1,10,100,1000 或者更大更大更大的数,到这你就会发现一件很有意思的事儿,那就是当数据集越来越大时,你会发现代码中的某些部分“失效”了。
当 n = 1000 时,1 + 2n = 2001,当 n = 10000 时,1 + 2n = 20001,当这个 n 持续增大时,常数 1 和系数 2 对于最后的结果越来越没存在感,即对趋势的变化影响不大。所以不要低阶项,只要高阶项,而且忽略高阶项上的系数。
所以对于我们这段代码样例,最终的 T(n) = O(n)。
2.时间复杂度分析
首先看一个例子
O(n)
for(i=0; i<n; i++)
j = i;
j++;
由公式,f(n)表示每行代码执行次数之和,与O成正比例关系,可以知道这段代码的时间复杂度为O(n)。此外,如果n无限大的时候,T(n) = time(1+2n)中的常量1就没有意义了,倍数2也意义不大。因此直接简化为T(n) = O(n) 就可以了。
这里列举一些常见的时间复杂度
| 时间复杂度 | 阶 | f(n) 举例 |
| 常数复杂度 | O(1) | 1 |
| 对数复杂度 | O(logn) | logn + 1 |
| 线性复杂度 | O(n) | n + 1 |
| 线性对数复杂度 | O(nlogn) | nlogn + 1 |
| k 次复杂度 | O(n²)、O(n³)、.... | n² + n +1 |
| 指数复杂度 | O(2^n) | 2^n + 1 |
| 阶乘复杂度 | O(n!) | n! + 1 |
上表的时间复杂度由上往下依次增加
这里选取一些常见的进行讲解
O(1)
O(1) 是常数时间复杂度。
在这你要先明白一个概念,不是只执行 1 次的代码的时间复杂度记为 O(1),只要你是常数,像 O(2)、O(3) ... O(100000) 在复杂度的表示上都是 O(1)。
n = 10000
xiaohe = n / 2
print(xiaohe)比如像上面这段代码,它运行了 3 次,但是它的时间复杂度记为 O(1),而不是 O(3)。
因为无论 n 等于多少,对于它们每行代码来说还是只是执行了一次,代码的执行时间不随 n 的变化而变化。
O(logn)
O(logn) 是对数时间复杂度。首先我们来看一段代码:
int i;
while(i<n)
i=i*2
上面的代码翻译一下就是初始化 i = 1, 乘上多少个 2 以后会 ≥ n。

假设需要 x 个,那么相当于求:
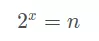
即
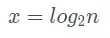
所以上述代码的时间复杂度应该为 O(log2n)。
但是对于对数复杂度来说,不管你是以 2、3 为底,还是以 10 为底,通通记作 O(logn),这是为什么呢?
这就要从对数的换底公式说起了
。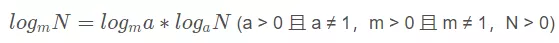
根据换底公式,log2n 可以写成:
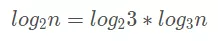
而对于时间复杂度来说:
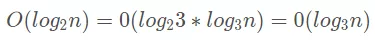
所以在对数时间复杂度中我们就忽略了底,直接用 O(logn) 来表示对数时间复杂度。
O(nlogn)
直接对上面的代码进行修改
for(hhh=1; hhh<n; hhh++)
i = 1;
while(i<n)
i = i * 2;
其实很好懂,线性对数阶O(nlogN)就是将复杂度为O(logn)的代码循环n遍,复杂度即n*O(logN)
,也就是 O(nlogn)啦
O(n^2)
这个就很好理解啦,即把O(n)的代码再循环一遍,这段代码是两层循环嵌套啦
for(i=0;j<n;i++)
for(j=0;j<n;j++)
m=j;
m++;
它的时间复杂度就是 O(n*n),即 O(n²)
同理,O(n^3)就相当于三层循环
最好情况时间复杂度
最好情况就是在最理想的情况下,代码的时间复杂度。
典例:冒泡排序
如果将数组里的这些数从小到大排序,
首先,列举一般情况
视频笔记
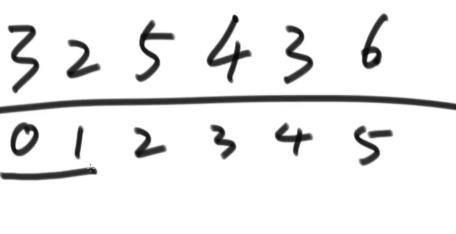
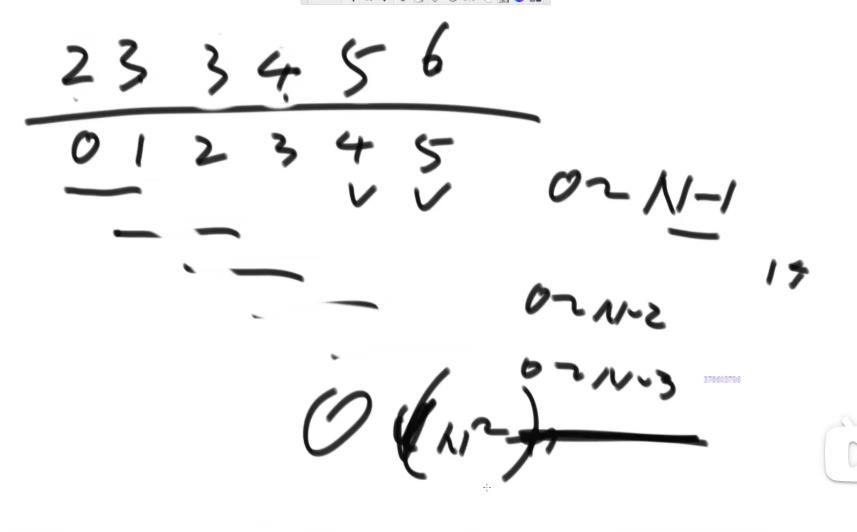
最好的情况:

这个时候对应的时间复杂度 O(1) 就是这段代码的最好情况时间复杂度。
最坏情况时间复杂度
最坏情况就是在最差的情况下,代码的时间复杂度。
最坏的情况:

还是从小到大排列
这个时候对应的时间复杂度 O(n) 是这段代码的最坏情况时间复杂度。
平均情况时间复杂度
大多数情况下,代码的执行情况都是介于最好情况和最坏情况之间,所以又出现了平均情况时间复杂度,
最好情况,反应最理想的情况,怎么可能天上天天掉馅饼,没啥参考价值。
平均情况,这倒是能反映算法的全面情况,但是一般“全面”,就和什么都没说一样,也没啥参考价值。
最坏情况,干啥事情都要考虑最坏的结果,因为最坏的结果提供了一种保障,触底的保障,保障代码的运行时间这个就是最差的,不会有比它还差的。
所以,不需要纠结各种情况,算时间复杂度就算最坏的那个时间复杂度即可。
三、空间复杂度
1.空间复杂度分析
其实,空间复杂度相较于时间复杂度来说,需要掌握的内容不多,它反映的也是一种趋势,只不过这种趋势是代码运行过程中临时变量占用的内存空间。
空间复杂度记作 S(n),表示形式与时间复杂度一致。
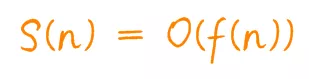
程序执行所需要的临时空间不随着某个变量n的大小而变化,即此算法空间复杂度为一个常量,可以表示为 O(1)
来段j简单的代码
int m=1,n=1;
int s;
s=m+n;
由于代码中的量不随数据变化,很直观反映出其空间复杂度为 S(n)=O(1)
2.常见空间复杂度
O(1)、O(n)、O(n²)是常见的空间复杂度
O(1)如上
O(n)
如果是个一维数组,传入数据n个,那么一维数组的空间复杂度就是O(N),
对于递归来说,递归的深度就是空间复杂度的最大值,深度如果是n,那么空间复杂度就是O(N)
O(n²)
如果是个二维数组,同理啦,传入数据n个,那么二维数组的空间复杂度就是O(N)。
当然啦,可以参考这个图
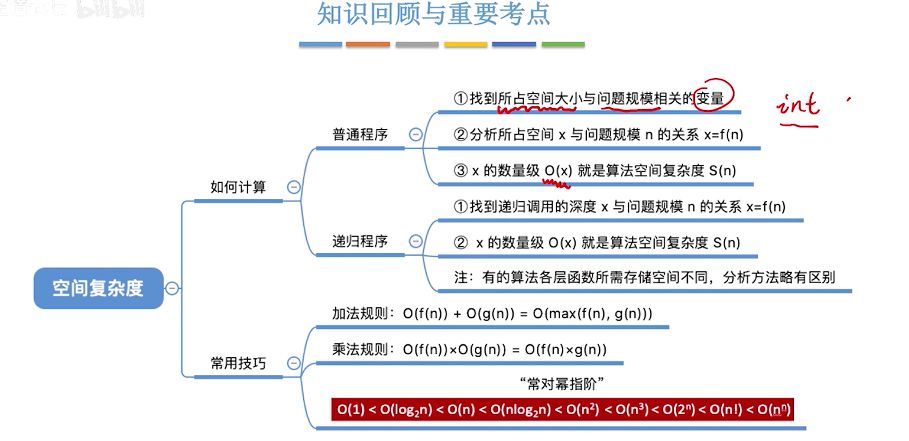
总结

- 本文部分参考了知乎上的资料和左程云大神的视频,希望对大家有帮助
- 图片部分用的是 风口浪尖上的猪 的哈哈,强烈推荐大家去看他在知乎上的精彩回答
- 如果有什么疑问或者错误啦,希望大家在评论区提出呀,谢谢!
- 一起加油鸭冲冲冲~
以上是关于『数据结构与算法』之时间复杂度与空间复杂度,看这一篇就够啦的主要内容,如果未能解决你的问题,请参考以下文章