hadoop之MR核心shuffle
Posted 柳小葱
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了hadoop之MR核心shuffle相关的知识,希望对你有一定的参考价值。
🍊首先祝福的大家端午节快乐!别人划龙舟,我写博客,也算是参加端午节的活动!废话不多说,今天我们来介绍一下MapReduce的核心思想!对以前内容感兴趣的小伙伴可以查看下面的内容:
- 链接: Spark之处理布尔、数值和字符串类型的数据.
- 链接: Spark之Dataframe基本操作.
- 链接: Spark之处理布尔、数值和字符串类型的数据.
- 链接: Spark之核心架构.
🍈今天我来学习hadoop中最重要的内容——MapReduce的过程,我们将介绍Map,Reduce,shuffle等详细内容。
目录
1.MapReduce原理
MapReduce是hadoop的核心,主要分为Map和Reduce阶段。Map阶段也叫做MapTask,Reduce也叫做ReduceTask。
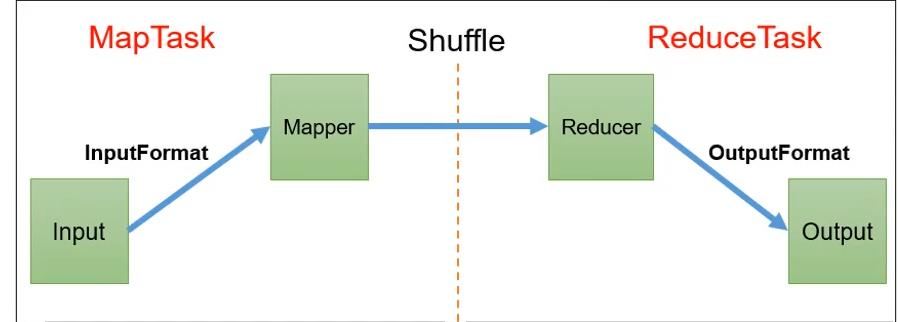
这里我们放上一张完整的mapreduce的流程图,每个步骤的编号代表执行的顺序,我们这里只列出了一个maptask的执行流程,其他maptask流程一样。细节部分后面会进行讲解。
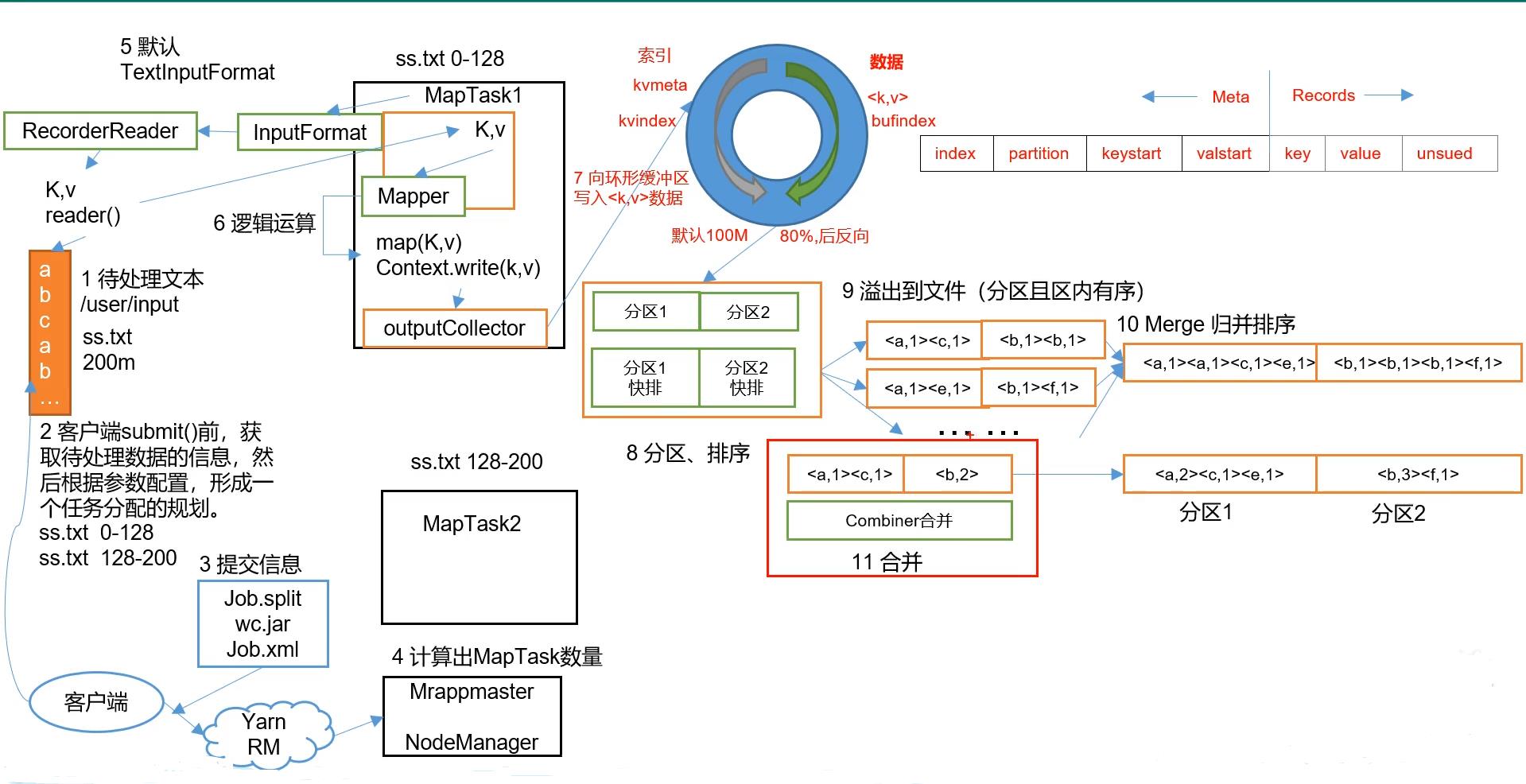
我们这里先给大家展示一下mapreduce的大致过程!细节我们接下来说。
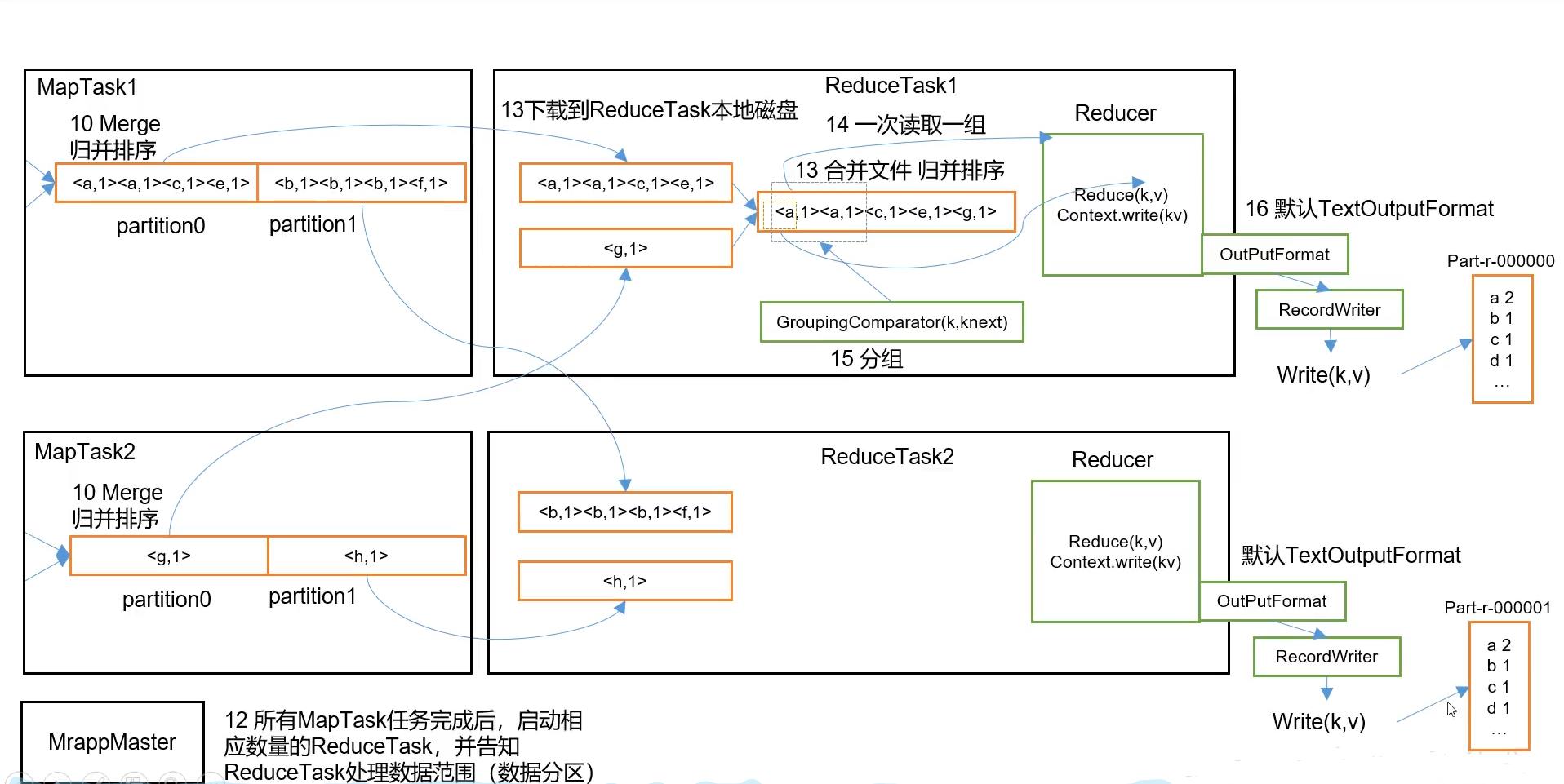
这张图接上面,因为太长了,写不下。
2.Map阶段的处理
2.1 inputFormat 数据输入
在上图中我们可以看见map阶段有个inputFormat的过程,这个过程主要是将输入的数据转化为<key,value>形式的数据。
2.1.1 切片与MapTask并行度决定机制
MapTask的并行度是由MapTask的数量决定的,我们知道,MapTask的运行是互不相关的,它们是并行运算的,所以MapTask的并行度决定Map阶段的任务处理并发度,进而影响整个Job的处理速度。
- 数据块block:是HDFS物理上把数据分成一块一块,数据块是HDFS的存储数据单位。
- 数据切片:数据切片只是在逻辑上对输入进行分片,并不会在磁盘上将其切分为片进行存储,数据切片切片是MR程序计算输入数据的单位,一个切片会对应启动一个MapTask。
数据块与数据切片的区别如下:
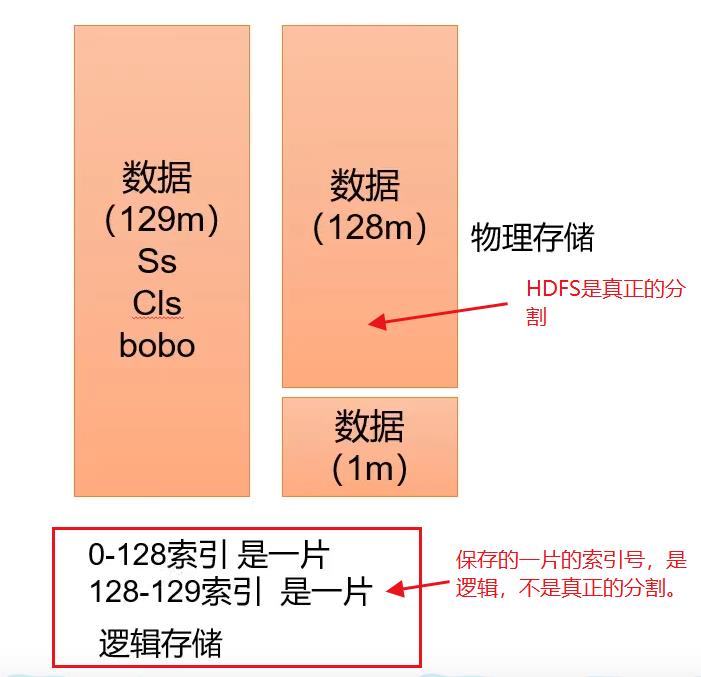
注意事项:
我们这里用下图来说明:
- 一般情况下数据块大小为多少,切片大小就为多少,这样可以使数据切片在在一个数据块block中,方便处理,提高效率。
- 有多少个数据切片,就有多少个MapTask数量
- 切片只针对单个文件,不针对整体数据集。
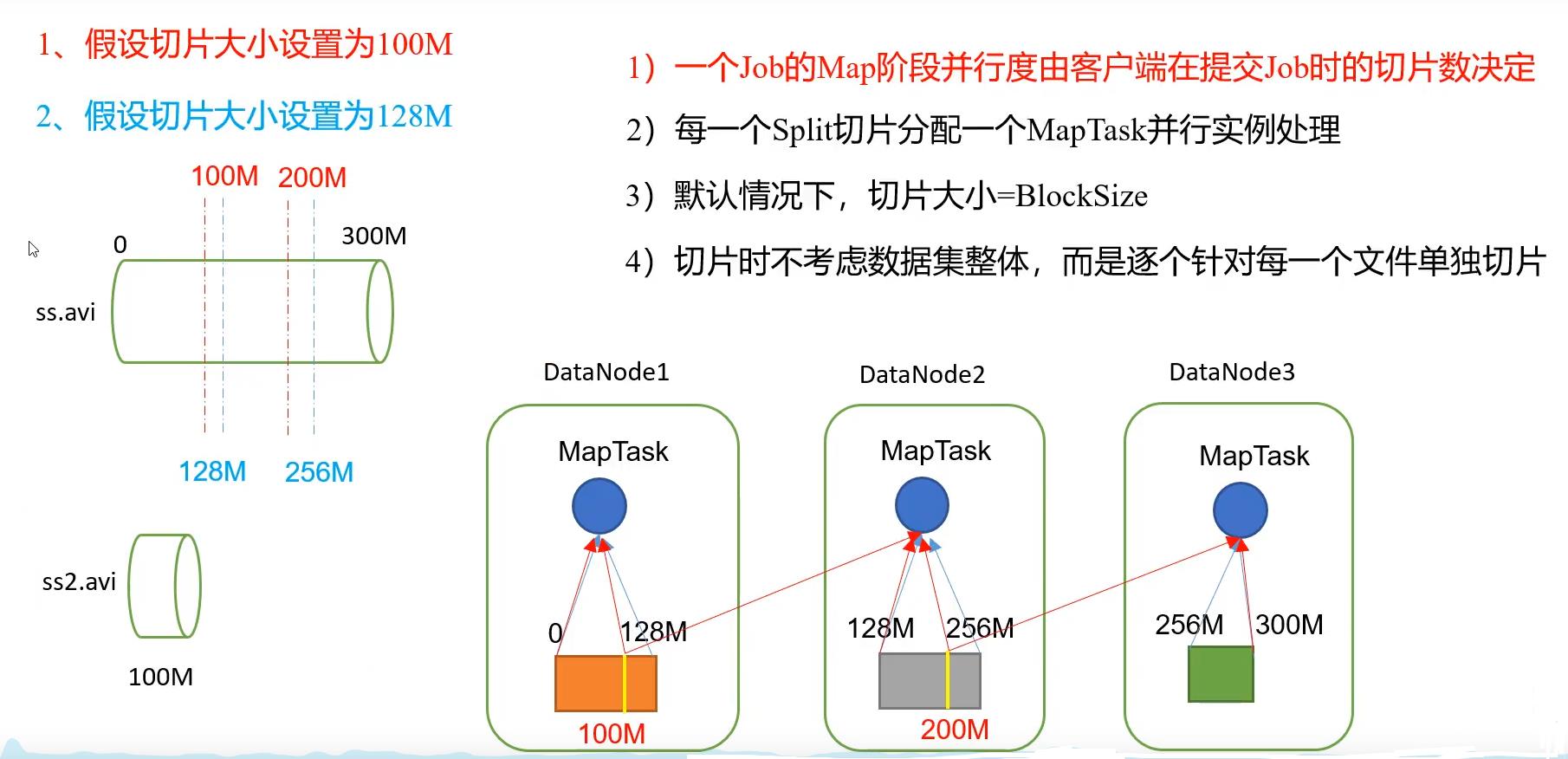
FileinputFormat切片源码解析

大家重点可以看下红色的部分。
说到FileinputFormat,其实它下面有很继承的子类:TextInputFormat、KeyValueTextInputFormat、NLineInputformat、CombineTextInputFormat和自定义InputForamt等。
3.Shuffle过程
Shuffle的中文意思就是洗牌,而mapreudce中Shuffle就是指:Map方法之后,Reduce方法之前的数据处理过程。
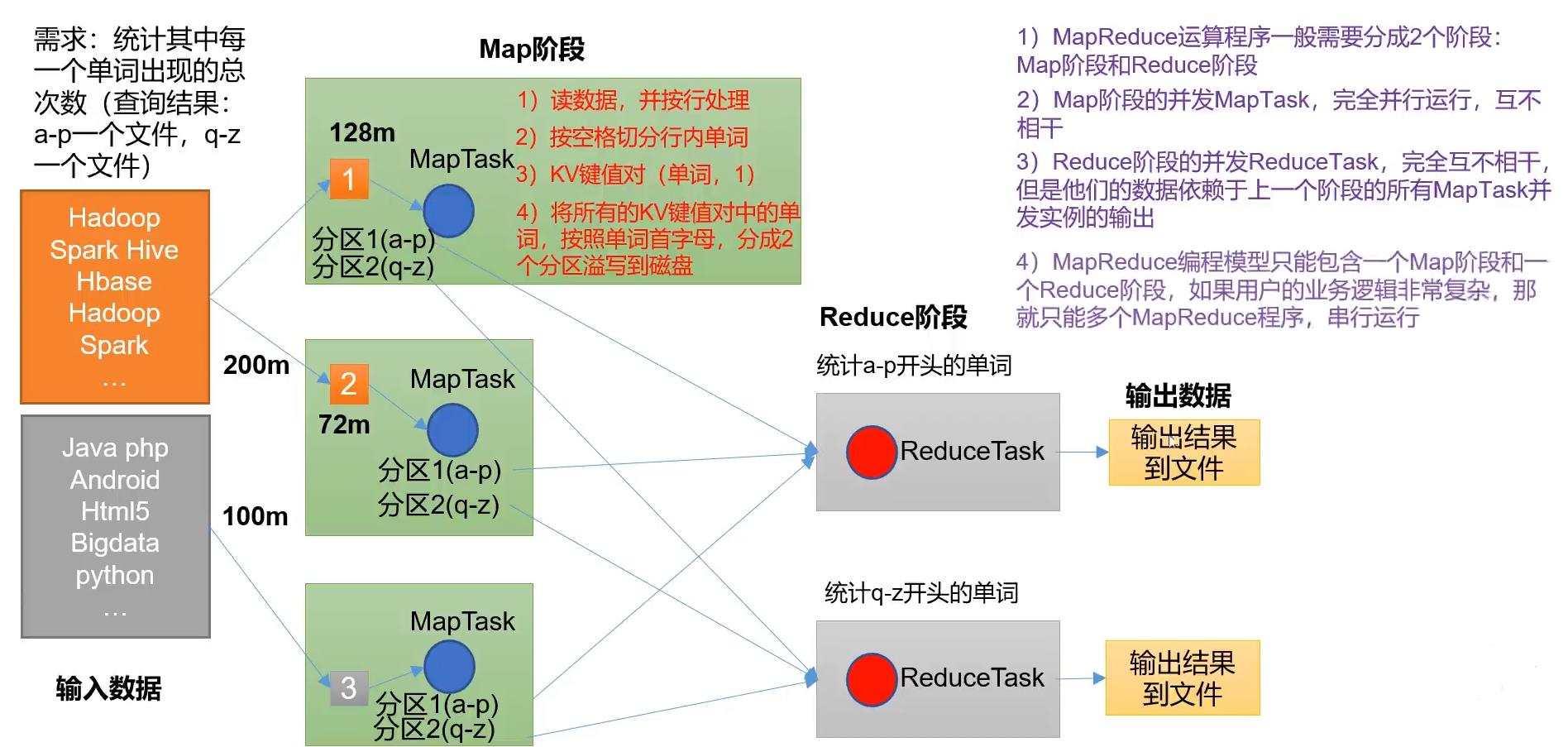
用一个wordcount来举例子。

接下来我们来详细看一下这个过程:
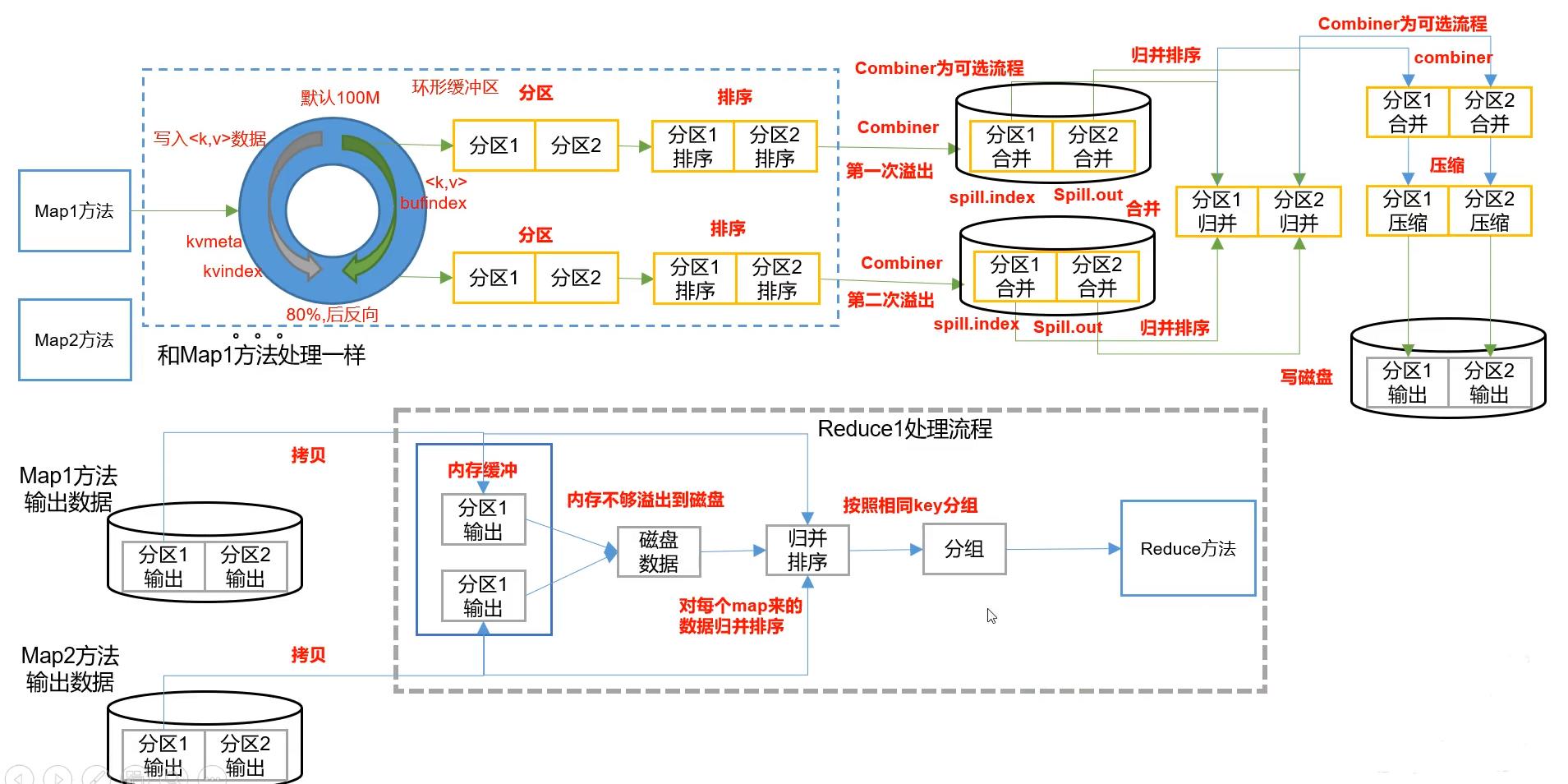
map的shuffle
- map1方法之后将<key,value>传入环形缓冲区,进行分区操作。
- 区内需要进行排序,排序的手段是快排,按照key的索引排序
- 将区内的数据进行合并(combiner操作,是一个可选的操作)
- 将环形缓冲区多次溢出的分区结果进行归并排序,形成一个大的有序的分区。
- 大的分区也可以进行combiner操作(可选),最后进行压缩。可以加快map将数据传送给reduce的效率
- 最后将分区数据写入磁盘,等待reduce的拉取
需要注意上图只展示了一个map1的数据处理过程,还有map2、mp3等等。
reduce的shuffle
- 根据分区结果拉取指定数据,拉取数据首先是放在内存里面,如果内存不够的话,会写到磁盘上
- 对每个map来的分区数据进行归并排序
- 按照相同的Key值进行分组
- 分组后进入对应的reduce方法中
3.1 shuffle过程中的partitioner
map的shuffle进行分区操作,默认方式主要采取的是哈希分区,就是就是key的hashcode的值与reduceTask的任务进行取余,当然自己也可以重写partitioner方法。
有以下几点需要注意:
- 如果reduceTask的数量>getpartition的结果数,则会产生多个空的输出文件。
- 如果1<reduceTask的数量<getpartition的结果数,则会有一部分分区数据无处安放,会报错。
- 如果reduceTask的数量等于1,则不管你mapTask设置多少分区文件,都只交给这一个reduceTask,也就会只产生一个结果文件。
3.2 shuffle过程中的排序
maptask和reducetask均会对数据按照keyj进行排序。该操作属于Hadoop的默认行为,任何应用程序中的数据均会被排序,而不管逻辑上是否需要。
- 对于maptask,它会将处理的结果暂时放到环形缓冲区,当环形缓冲区使用率达到一定阈值后,再对环形缓冲区进行一次快速排序(内存中),并将这些游有序数据溢写到磁盘上,当数据处理完毕后,他会对磁盘上所有的文件进行归并排序。
- 对于reducetask,它从每一个maptask上远程拷贝相应的数据文件,如果文件大小超过一定阈值,则溢写到磁盘,否则存储在内存中。如果磁盘上的文件数目达到一定的阈值,则进行一次归并排序以生成一个更大的文件;如果内存中文件大小或者数目超过一定阈值,则进行一次合并后将数据溢写到磁盘上,当所有的数据拷贝完毕后,reducetask统一对内存和磁盘的所有数据进行一次归并排序。
- 部分排序:mapreduce根据输入记录的键值对数据集排序。保证输出的每个文件内部有序。
- 全排序:最终输出的结果只有一个文件,且文件内部有序,实现方式知识设置一个reduceTask,但该方法在处理大型文件时效率极低,因为一台机器处理所有文件,完全失去了mapreduce所提供的并行架构的优势。
- 辅助排序:用的较少
参考资料
参考了全网较为热门的MR过程,总结出来。
《尚硅谷的hadoop3.0实战》
《大数据hadoop实战》
《hadoop实战指南》
以上是关于hadoop之MR核心shuffle的主要内容,如果未能解决你的问题,请参考以下文章