无需kubectl!快速使用Prometheus监控Etcd
Posted RancherLabs
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了无需kubectl!快速使用Prometheus监控Etcd相关的知识,希望对你有一定的参考价值。
在本文中,我们将安装一个Etcd集群并使用Prometheus和Grafana配置监控,以上这些操作我们都通过Rancher进行。
我们将看到在不需要依赖的情况下充分利用Rancher的应用商店实现这一目标是如此容易。在本文中,我们将不需要:
- 为运行kubectl专门配置交互框,并指向Kubernetes集群
- kubectl的使用知识,因为我们可以使用Rancher UI完成这一切
- 安装/配置 Helm binary
Demo的前期准备
你将需要:
- 一个Google云平台的账号(免费的即可)。任意其他云也可以。
- Rancher v2.4.7(撰写本文时的最新版本)
- 运行在GKE(版本为1.16.3-gke.1)上的Kubernetes集群(在EKS或AKS上运行也可以)
启动一个Rancher实例
首先,启动你的Rancher实例。你可以访问以下链接查看快速启动指南:
https://www.rancher.cn/quick-start/
使用Rancher部署一个GKE集群
使用Rancher来设置和配置一个Kubernetes集群,你可以查看相关文档:
https://docs.rancher.cn/docs/rancher2/cluster-provisioning/production/_index/
部署etcd、Prometheus和Grafana
我们可以利用Rancher的应用商店来安装所有的软件。应用商店是Helm chart的集合,它可以让用户能够轻松地重复部署这些应用程序。
当我们的集群启动并运行后,让我们选择为其创建的Default项目,在Apps选项卡中,点击【Launch】。
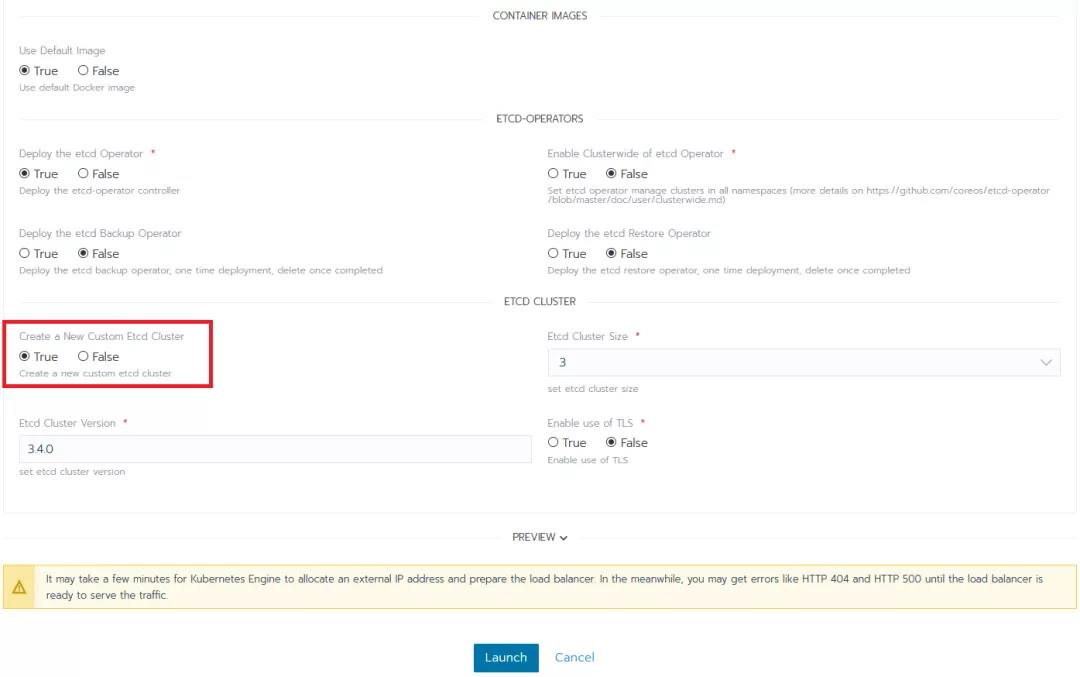
我们要安装的第一个应用是etcd-operator。保留它预先填充的所有默认值,并确保你也启用了etcd集群的创建(为了demo的简单性,我们取消选择etcd Backup Operator和etcd Restore Operator)。
Operator的作用是观察、分析和行动。它使用Kubernetes API来观察当前集群的状态。如果运行状态与所需状态之间有任何差异,它就会发现并修复它们。
例如,假设我们正在运行一个有三个成员的etcd集群。如果发生了一些事情,其中一个成员倒下了,Operator会观察到这一点。它根据所需的状态做一个差异,然后根据差异恢复丢失的成员。于是,我们在没有人为干预的情况下拥有了一个健康的集群。
要安装Prometheus和Grafana,请激活Rancher中集成的集群监控支持。从 【全局】视图中,选择你要配置的集群,并选择【工具】→【监控】以启用它。为了允许对Grafana的更改持久化,请确保为Grafana和Prometheus启用持久化存储。如果你没有设置任何持久化存储,可以了解一下Longhorn,这是Kubernetes的云端分布式块存储。

当一切都在安装时,你可以探索一些选项卡。检查工作负载(Pods、Deployments、DaemonSet)或创建的服务的进度。
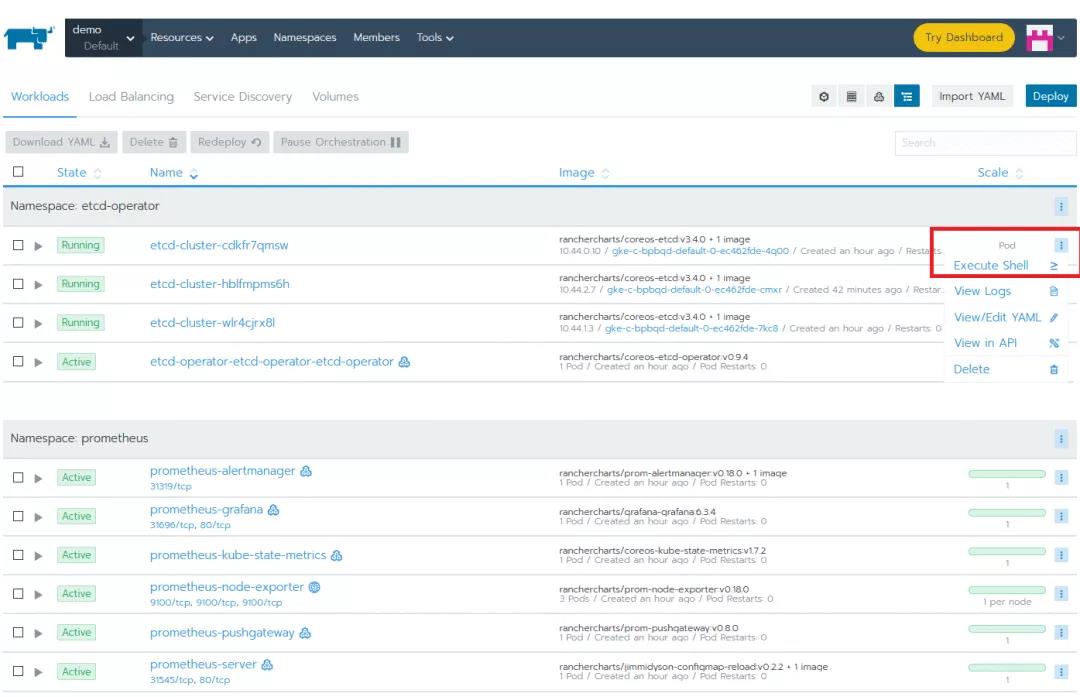
让我们连接到一个etcd Pod,以便使用一些基本的etcdctl命令(更多细节可以查阅之前的文章)。选择一个Pod,点击它的垂直省略号(3个竖点)菜单按钮,然后选择Execute Shell。

配置Prometheus以及Grafana
监控 etcd 集群的最佳和最简单的方法之一是使用 Prometheus 和 Grafana。让我们登录到Grafana——在集群概览中点击任意Grafana图标即可登录。

Grafana已经预先配置了Prometheus作为数据源,包含几个可视化集群状态的dashboard。
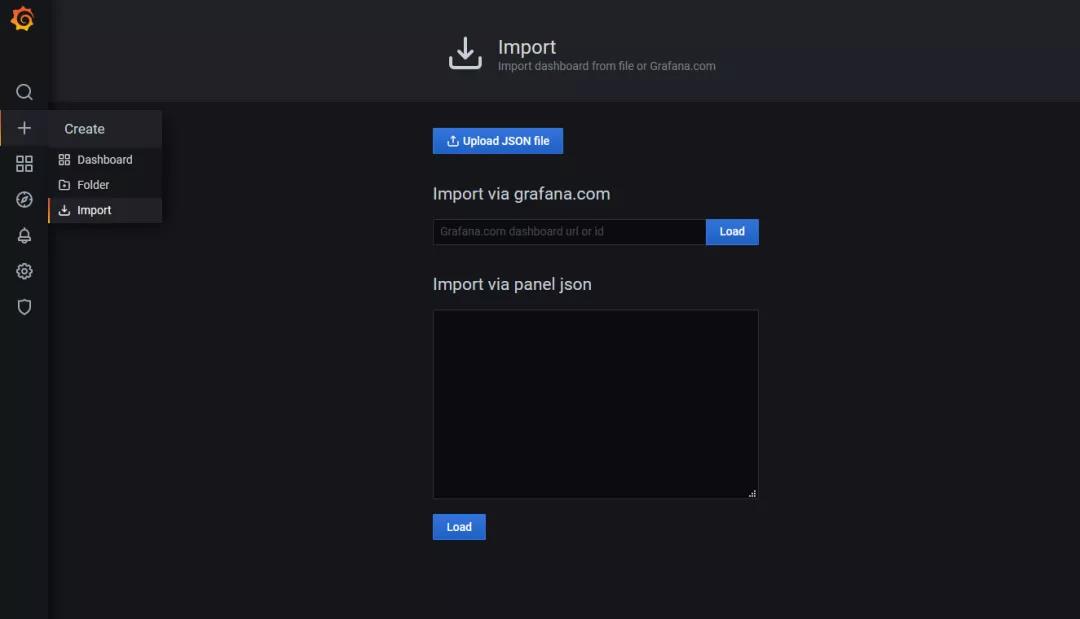
登录Grafana为etcd添加一个仪表盘。默认的用户名和密码都是 “admin”(第一次登录时,会提示你更改)。然后用id3070导入默认的etcd仪表盘模板。点击加载,然后剩下的步骤就是选择Prometheus数据源。

我们已经成功导入了dashboard,我们可以看到各种图表,但是没有数据显示。为什么呢?我们已经运行了Prometheus,并且Grafana也与之集成。可问题是我们没有告诉Prometheus去收集与我们etcd集群相关的目标。
让我们回到Rancher中去解决这个问题。进入系统项目,点击【资源】标签下的导入YAML。然后将以下资源导入到cattle-prometheus命名空间中:
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
labels:
source: rancher-monitoring
name: etcd
namespace: cattle-prometheus
spec:
endpoints:
- port: client
namespaceSelector:
matchNames:
- etcd-operator
selector:
matchLabels:
app: etcd
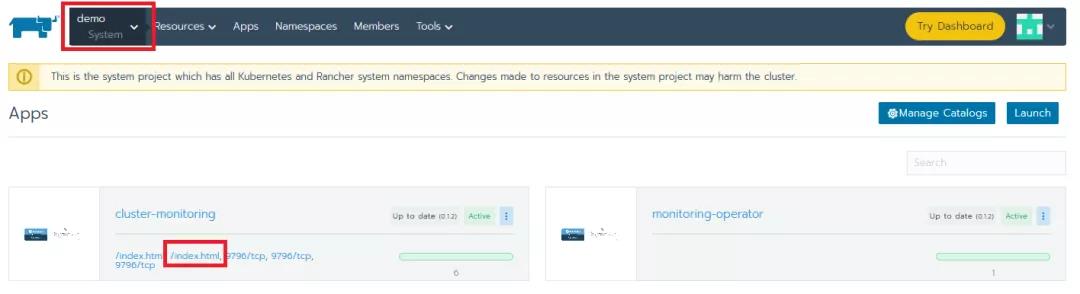
我们如何验证我们的新配置是有效的,并且确保Prometheus正在执行它的工作呢?我们需要对其进行检查,请点击系统项目的Apps选项卡,并点击cluster-monitoring应用程序中的第二个/index/.html链接。
这将打开Prometheus web UI界面。在界面中,进入Graphs并手动执行一些查询,如果有数据显示,那么就说明我们的设置已经完成。

我们需要做的最后一件事是检查Grafana并且查看我们有相关的数据图表。
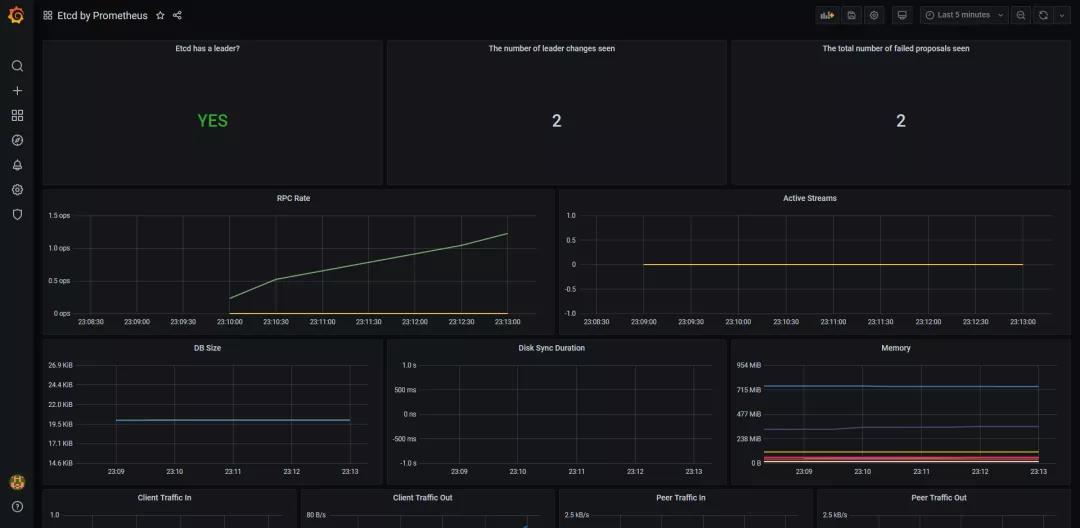
卸载应用程序和集群
要清理我们在本文中使用的资源,我们只需要在全局层级中,选择我们的集群并点击【Delete】。
通过这样做,除了为Prometheus创建的持久化存储外,所有的东西都将被删除。我们需要从我们的云提供商控制台来处理这个问题。
当然,我们可以只从Rancher中执行清理,但步骤略有不同。
- disable monitoring:在全局层级,导航到集群,选择工具→监控并点击【Disable】按钮。
- 移除持久化存储:进入 “系统项目"→"资源"→"工作负载"→"卷”;选择你的卷并单击 “删除”。
- 删除集群:在全局层级选择集群并删除它。
总 结
在这个demo中,我们看到了如何使用Rancher安装Etcd(使用etcd-operator),Prometheus和Grafana。所有的集成都是开箱即用的:我们只需要添加一些东西就可以完成所有的配置。Rancher还提供了所有所需的可视性,在必要的情况下,可以方便地进行故障排除。
以上是关于无需kubectl!快速使用Prometheus监控Etcd的主要内容,如果未能解决你的问题,请参考以下文章