spark outer join push down filter rule(spark 外连接中的下推规则)
Posted 鸿乃江边鸟
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了spark outer join push down filter rule(spark 外连接中的下推规则)相关的知识,希望对你有一定的参考价值。
背景
对于spark的不同的join操作来说,有些谓词是能下推,是有谓词是不能下推的,今天我们实地操作一番,从现象和源码级别分析一下,这到底是怎么回事。
版本&环境
spark 3.2.0
macbook pro
理论基础
1. 参考hive OuterJoinBehavior
我们解释一下几个名词:
- Preserved Row table (留存表)
在join操作中返回所有行的表 - Null Supplying table (补空表)
在join操作中,对于不匹配的行,补bull的表 - During Join predicate (join中谓词)
在join中on 语句中的谓词,例如:在 R1 join R2 on R1.x = 5,R1.x = 5 我们称之为 join中谓词 - After Join predicate (join后谓词)
在join中,位于where中的谓词
2. join type
根据当前spark版本,我们把join类型分为以下多种类型,也就是我们进行验证的各种join类型
- inner
- outer | full | fullouter
- leftouter | left
- rightouter | right
- leftsemi | semi
- leftanti | anti
- cross
因为 fullouter join和inner join以及leftsemi/anti join 在join中谓词和join后谓词是没有区别的,所以我们不探讨
ross join 没有on操作这么一说,所以我们也不探讨
注意:理论只是理论,在实际应用中会做一些优化,这和理论是有区别
3.sql解析
对于spark来说,任何一个sql的解析都会经过以下几个阶段:
Unresolved Logical Plan -> Analyzer Logical Plan -> Optimzer Logical Plan -> SparkPlan -> ExecutedPlan
先说结论
| outer join | 留存表 | 补空表 |
|---|---|---|
| join中谓词 | 不下推 | 下推 |
| join后谓词 | 下推 | 下推 |
实践分析
运行以下代码:
def main(args: Array[String]): Unit =
val spark = SparkSession
.builder()
.appName("delta-merge")
.config("spark.master", "local[1]")
.config("spark.app.name", "demo")
.config("spark.sql.adaptive.autoBroadcastJoinThreshold", -1)
.config("spark.sql.autoBroadcastJoinThreshold", -1)
.config(SQLConf.PLAN_CHANGE_LOG_LEVEL.key, "warn")
.getOrCreate()
spark.sparkContext.setLogLevel("info")
import spark.implicits._
val df1 = Seq(
(BigDecimal("11"), 1),
(BigDecimal("22"), 2),
(BigDecimal("33"), 3)).toDF("decNum1", "intNum1")
df1.write
.mode(SaveMode.Overwrite)
.parquet("df1.parquet")
val df2 = Seq(
(BigDecimal("1111"), 1),
(BigDecimal("2222"), 2),
(BigDecimal("4444"), 4)).toDF("decNum2", "intNum2")
df2.write
.mode(SaveMode.Overwrite)
.parquet("df2.parquet")
spark.sql("select null > 2").show(2)
val dfP1 = spark.read.parquet("df1.parquet")
val dfP2 = spark.read.parquet("df2.parquet")
dfP1.createOrReplaceTempView("tbl1")
dfP2.createOrReplaceTempView("tbl2")
val dfResult = spark.sql("select * from tbl1 join tbl2 on intNum1 == intNum2 where intNum1 > 1")
dfResult.show(40, false)
dfResult.explain("extended")
println("==========")
dfResult.queryExecution.tracker.rules map
case (key, value: RuleSummary) if (value.numEffectiveInvocations > 0) =>
println(s"$key, $value")
case (_, _) =>
Thread.sleep(10000000L)
spark.sql.adaptive.autoBroadcastJoinThreshold 和spark.sql.autoBroadcastJoinThreshold设置为-1
是为了把SMJ(sort merge join)转换为BHJ(broastcast hash join)给禁掉,这样就能看到我们想要的结果。
SQLConf.PLAN_CHANGE_LOG_LEVEL.key和sparkcontext的log级别进行调整
是为了能够打印出sql所经历的逻辑计划优化规则以及物理规则,这样我们就很清楚的知道该条sql被洗礼的过程。
df3.explain(“extended”) 是为了更加清晰直观的打印出各个阶段的计划,方便追踪。
df3.queryExecution.tracker.rules 是为了打印出sql在逻辑计划阶段所经历的解析以及优化规则,排序不分先后,因为后端是用java.util.HashMap存储的。
- leftouter-join中谓词-留存表
运行
val dfResult = spark.sql("select * from tbl1 left outer join tbl2 on intNum1 == intNum2 and intNum1 > 1")
ResolveRelations规则只是用catalog元数据解析出parquet表,如下:
=== Applying Rule org.apache.spark.sql.catalyst.analysis.Analyzer$ResolveRelations ===
'Project [*] 'Project [*]
+- 'Join LeftOuter, (('intNum1 = 'intNum2) AND ('intNum1 > 1)) +- 'Join LeftOuter, (('intNum1 = 'intNum2) AND ('intNum1 > 1))
! :- 'UnresolvedRelation [tbl1], [], false :- SubqueryAlias tbl1
! +- 'UnresolvedRelation [tbl2], [], false : +- View (`tbl1`, [decNum1#33,intNum1#34])
! : +- Relation [decNum1#33,intNum1#34] parquet
! +- SubqueryAlias tbl2
! +- View (`tbl2`, [decNum2#37,intNum2#38])
! +- Relation [decNum2#37,intNum2#38] parquet
PushDownPredicates规则有所变化,只是变化了一下on中两个条件的位置,如下:
=== Applying Rule org.apache.spark.sql.catalyst.optimizer.PushDownPredicates ===
!Join LeftOuter, ((intNum1#34 = intNum2#38) AND (intNum1#34 > 1)) Join LeftOuter, ((intNum1#34 > 1) AND (intNum1#34 = intNum2#38))
:- Relation [decNum1#33,intNum1#34] parquet :- Relation [decNum1#33,intNum1#34] parquet
+- Relation [decNum2#37,intNum2#38] parquet +- Relation [decNum2#37,intNum2#38] parquet
InferFiltersFromConstraints做了谓词下推,但是下推的是补空表,而不是保留表,如下:
=== Applying Rule org.apache.spark.sql.catalyst.optimizer.InferFiltersFromConstraints ===
Join LeftOuter, ((intNum1#34 > 1) AND (intNum1#34 = intNum2#38)) Join LeftOuter, ((intNum1#34 > 1) AND (intNum1#34 = intNum2#38))
:- Relation [decNum1#33,intNum1#34] parquet :- Relation [decNum1#33,intNum1#34] parquet
!+- Relation [decNum2#37,intNum2#38] parquet +- Filter ((intNum2#38 > 1) AND isnotnull(intNum2#38))
! +- Relation [decNum2#37,intNum2#38] parquet
其实从源码上我们也可以看到其实现,如下:
case LeftOuter | LeftAnti =>
val allConstraints = getAllConstraints(left, right, conditionOpt)
val newRight = inferNewFilter(right, allConstraints)
join.copy(right = newRight)
结果:
|decNum1 |intNum1|decNum2 |intNum2|
+---------------------+-------+-----------------------+-------+
|11.000000000000000000|1 |null |null |
|22.000000000000000000|2 |2222.000000000000000000|2 |
|33.000000000000000000|3 |null |null |
+---------------------+-------+-----------------------+-------+
对应的物理计划:
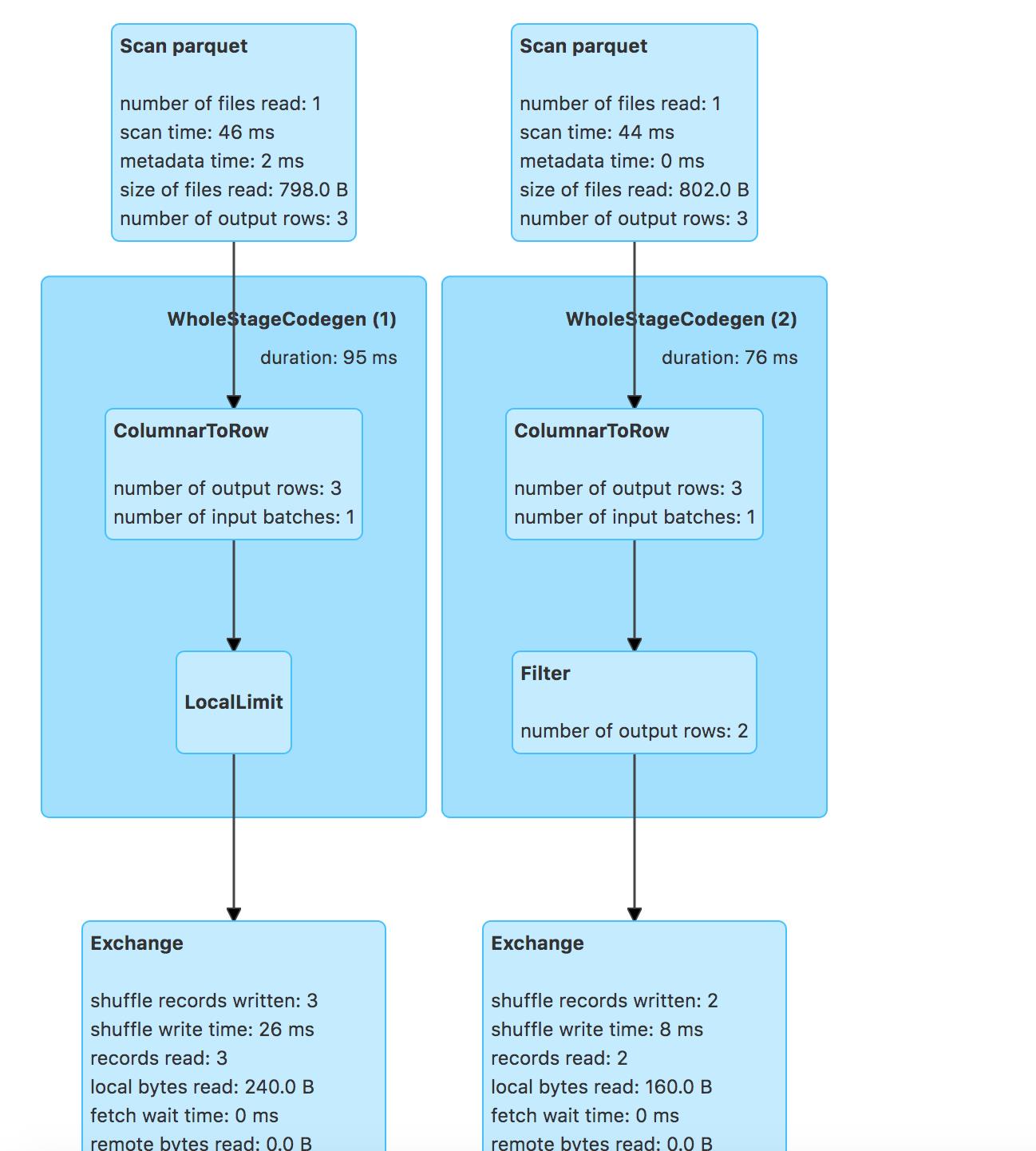
- leftouter-join中谓词-补空表
运行
val dfResult = spark.sql("select * from tbl1 left outer join tbl2 on intNum1 == intNum2 and intNum2 > 1")
这个时候PushDownPredicates规则又有所变化,直接把谓词下推下去了,如下:
=== Applying Rule org.apache.spark.sql.catalyst.optimizer.PushDownPredicates ===
!Join LeftOuter, ((intNum1#34 = intNum2#38) AND (intNum2#38 > 1)) Join LeftOuter, (intNum1#34 = intNum2#38)
:- Relation [decNum1#33,intNum1#34] parquet :- Relation [decNum1#33,intNum1#34] parquet
!+- Relation [decNum2#37,intNum2#38] parquet +- Filter (intNum2#38 > 1)
! +- Relation [decNum2#37,intNum2#38] parquet
源码实现部分参考如下:
case LeftOuter | LeftAnti | ExistenceJoin(_) =>
// push down the right side only join filter for right sub query
val newLeft = left
val newRight = rightJoinConditions.
reduceLeftOption(And).map(Filter(_, right)).getOrElse(right)
val newJoinCond = (leftJoinConditions ++ commonJoinCondition).reduceLeftOption(And)
Join(newLeft, newRight, joinType, newJoinCond, hint)
InferFiltersFromConstraints的规则,也就只是加了isnotnull(intNum2#38)判断,如下:
=== Applying Rule org.apache.spark.sql.catalyst.optimizer.InferFiltersFromConstraints ===
Join LeftOuter, (intNum1#34 = intNum2#38) Join LeftOuter, (intNum1#34 = intNum2#38)
:- Relation [decNum1#33,intNum1#34] parquet :- Relation [decNum1#33,intNum1#34] parquet
!+- Filter (intNum2#38 > 1) +- Filter (isnotnull(intNum2#38) AND (intNum2#38 > 1))
+- Relation [decNum2#37,intNum2#38] parquet +- Relation [decNum2#37,intNum2#38] parquet
结果:
+---------------------+-------+-----------------------+-------+
|decNum1 |intNum1|decNum2 |intNum2|
+---------------------+-------+-----------------------+-------+
|11.000000000000000000|1 |null |null |
|22.000000000000000000|2 |2222.000000000000000000|2 |
|33.000000000000000000|3 |null |null |
+---------------------+-------+-----------------------+-------+
对应的物理计划:
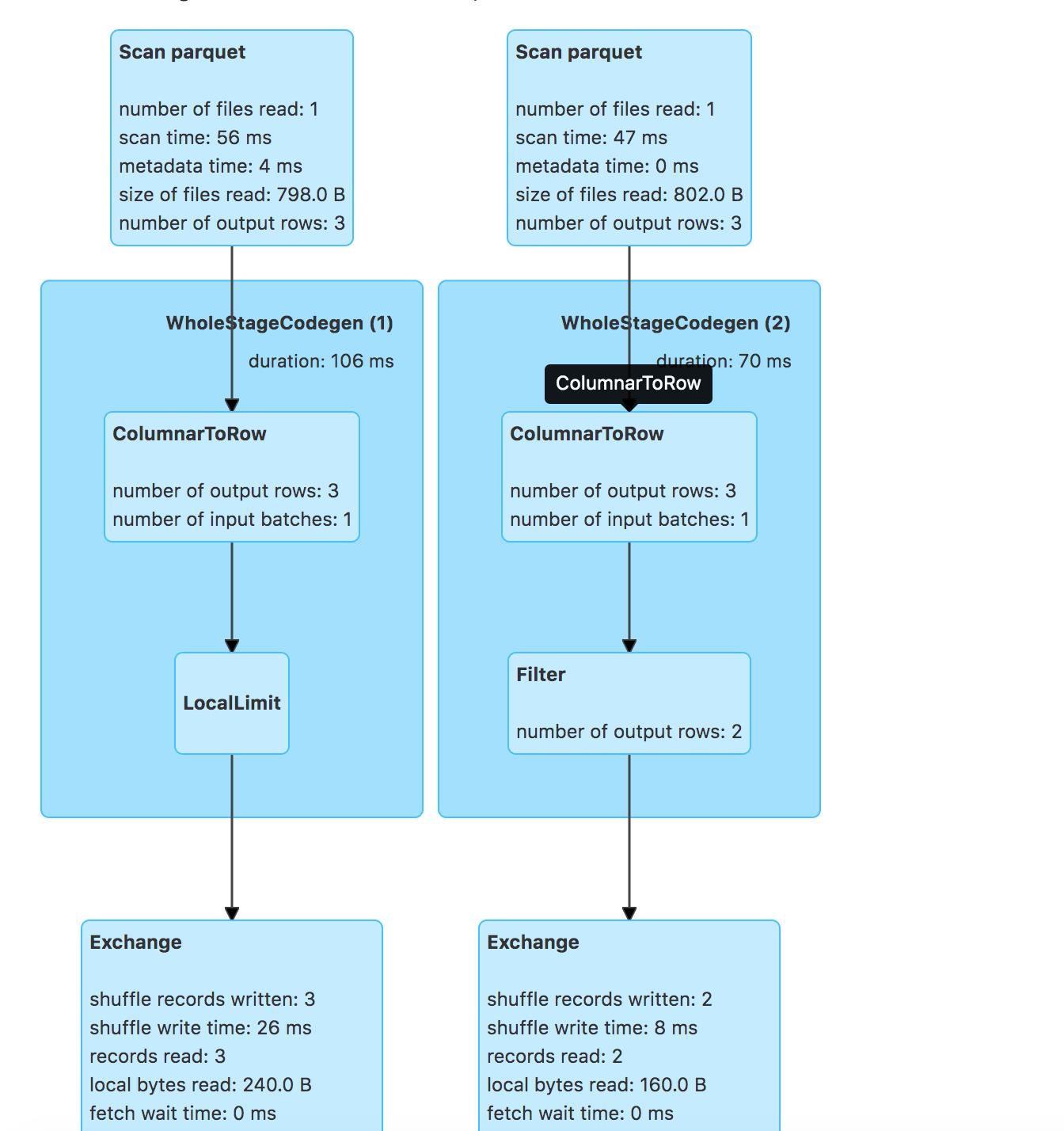
- leftouter-join后谓词-留存表
运行
val dfResult = spark.sql("select * from tbl1 left outer join tbl2 on intNum1 == intNum2 where intNum1 > 1")
PushDownPredicates规则把filter进行了下推,如下:
=== Applying Rule org.apache.spark.sql.catalyst.optimizer.PushDownPredicates ===
!Filter (intNum1#34 > 1) Join LeftOuter, (intNum1#34 = intNum2#38)
!+- Join LeftOuter, (intNum1#34 = intNum2#38) :- Filter (intNum1#34 > 1)
! :- Relation [decNum1#33,intNum1#34] parquet : +- Relation [decNum1#33,intNum1#34] parquet
! +- Relation [decNum2#37,intNum2#38] parquet +- Relation [decNum2#37,intNum2#38] parquet
InferFiltersFromConstraints规则把谓词进行了推导,补空表也进行了下推,如下:
=== Applying Rule org.apache.spark.sql.catalyst.optimizer.InferFiltersFromConstraints ===
Join LeftOuter, (intNum1#34 = intNum2#38) Join LeftOuter, (intNum1#34 = intNum2#38)
!:- Filter (intNum1#34 > 1) :- Filter (isnotnull(intNum1#34) AND (intNum1#34 > 1))
: +- Relation [decNum1#33,intNum1#34] parquet : +- Relation [decNum1#33,intNum1#34] parquet
!+- Relation [decNum2#37,intNum2#38] parquet +- Filter ((intNum2#38 > 1) AND isnotnull(intNum2#38))
! +- Relation [decNum2#37,intNum2#38] parquet
运行结果如下:
+---------------------+-------+-----------------------+-------+
|decNum1 |intNum1|decNum2 |intNum2|
+---------------------+-------+-----------------------+-------+
|22.000000000000000000|2 |2222.000000000000000000|2 |
|33.000000000000000000|3 |null |null |
+---------------------+-------+-----------------------+-------+
对应的物理计划:
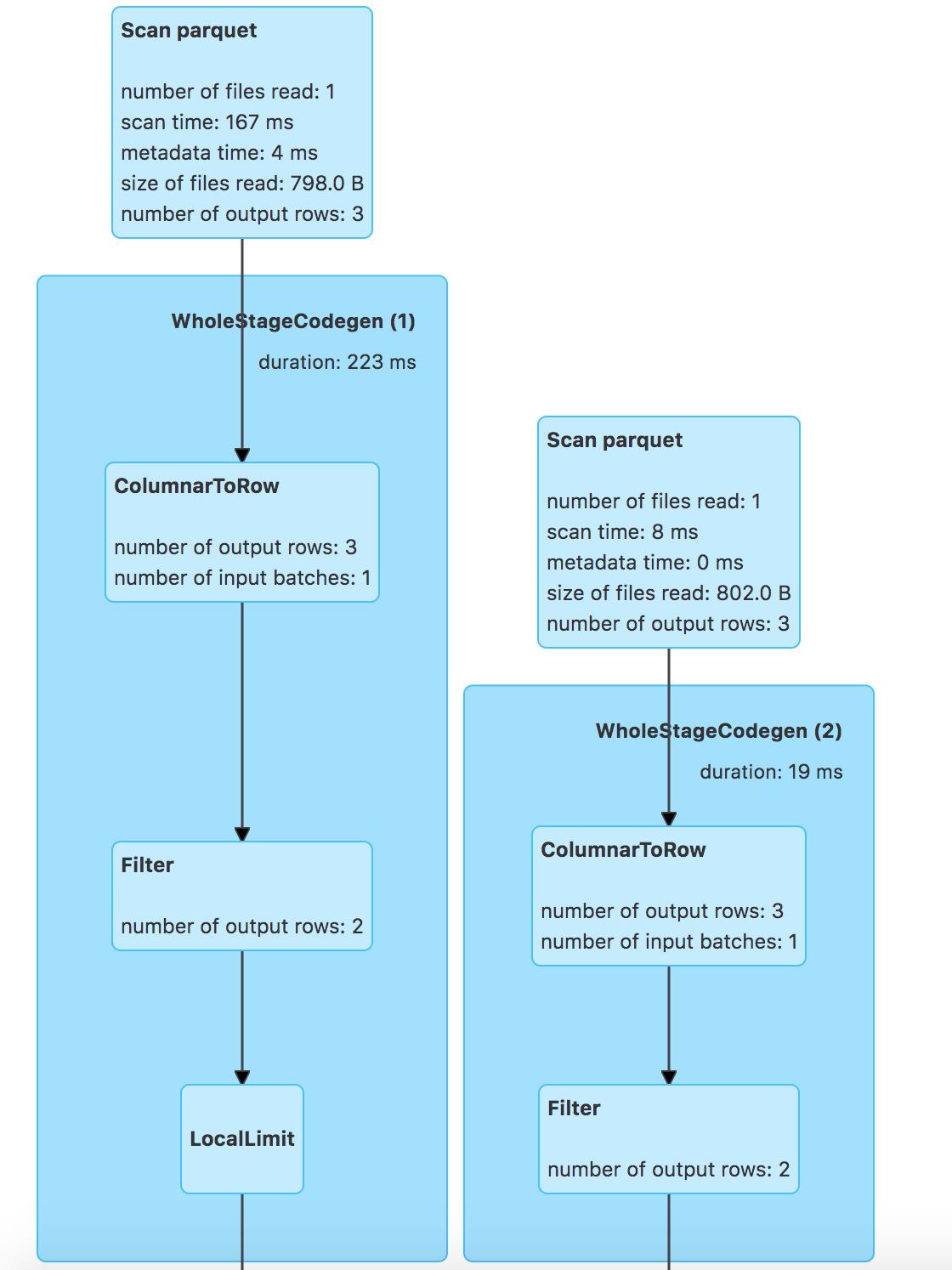
- leftouter-join后谓词-补空表
运行:
val dfResult = spark.sql("select * from tbl1 left outer join tbl2 on intNum1 == intNum2 where intNum2 > 1")
但是多了一条EliminateOuterJoin规则,这个规则会把left join操作,变换为inner join,如下:
=== Applying Rule org.apache.spark.sql.catalyst.optimizer.EliminateOuterJoin ===
Filter (intNum2#38 > 1) Filter (intNum2#38 > 1)
!+- Join LeftOuter, (intNum1#34 = intNum2#38) +- Join Inner, (intNum1#34 = intNum2#38)
:- Relation [decNum1#33,intNum1#34] parquet :- Relation [decNum1#33,intNum1#34] parquet
+- Relation [decNum2#37,intNum2#38] parquet +- Relation [decNum2#37,intNum2#38] parquet
PushDownPredicates规则和InferFiltersFromConstraints分析和leftouter-join后谓词-留存表 一样,只不过join类型变成了inner join(由于EliminateOuterJoin变换的),也是会进行下推.
结果如下:
+---------------------+-------+-----------------------+-------+
|decNum1 |intNum1|decNum2 |intNum2|
+---------------------+-------+-----------------------+-------+
|22.000000000000000000|2 |2222.000000000000000000|2 |
+---------------------+-------+-----------------------+-------+
对应的物理计划:
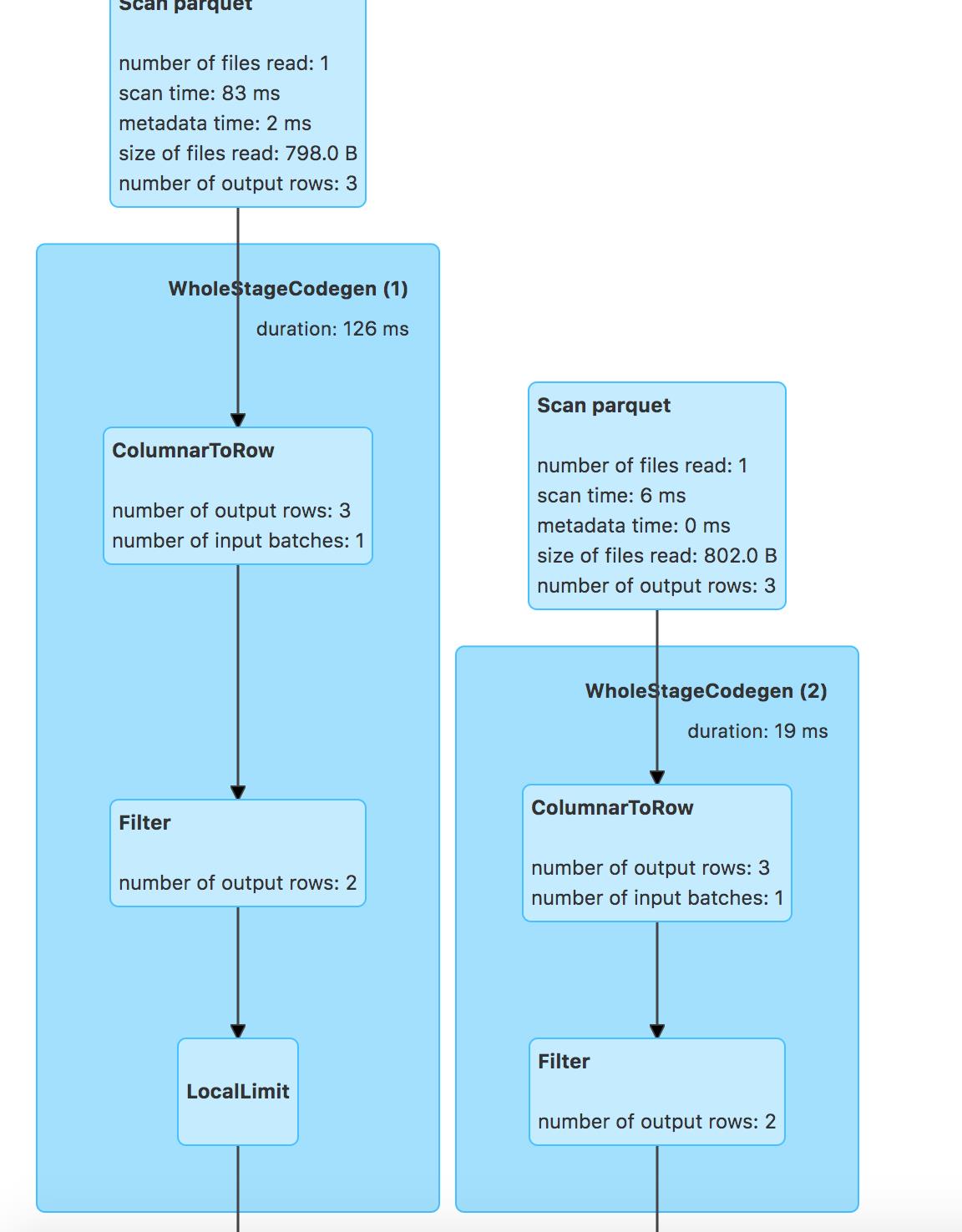
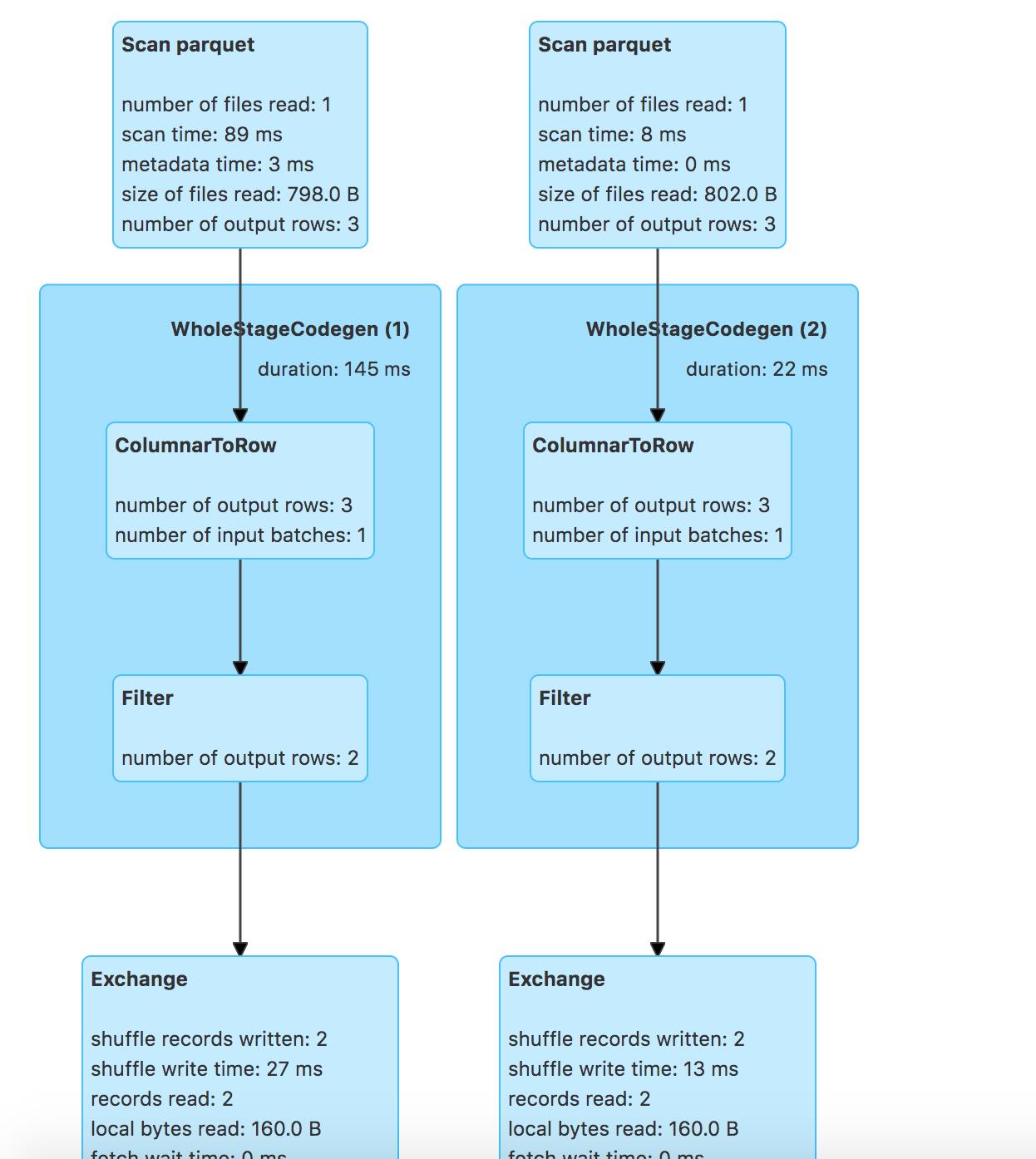
- rightouter join中谓词-留存表
运行:
val dfResult = spark.sql("select * from tbl1 right outer join tbl2 on intNum1 == intNum2 and intNum2 > 1")
PushDownPredicates规则只是把join条件的位置进行了变化,如下:
=== Applying Rule org.apache.spark.sql.catalyst.optimizer.PushDownPredicates ===
!Join RightOuter, ((intNum1#34 = intNum2#38) AND (intNum2#38 > 1)) Join RightOuter, ((intNum2#38 > 1) AND (intNum1#34 = intNum2#38))
:- Relation [decNum1#33,intNum1#34] parquet :- Relation [decNum1#33,intNum1#34] parquet
+- Relation [decNum2#37,intNum2#38] parquet +- Relation [decNum2#37,intNum2#38] parquet
而InferFiltersFromConstraints会衍生出下推,如:
=== Applying Rule org.apache.spark.sql.catalyst.optimizer.InferFiltersFromConstraints ===
Join RightOuter, ((intNum2#38 > 1) AND (intNum1#34 = intNum2#38)) Join RightOuter, ((intNum2#38 > 1) AND (intNum1#34 = intNum2#38))
!:- Relation [decNum1#33,intNum1#34] parquet :- Filter ((intNum1#34 > 1) AND isnotnull(intNum1#34))
!+- Relation [decNum2#37,intNum2#38] parquet : +- Relation [decNum1#33,intNum1#34] parquet
! +- Relation [decNum2#37,intNum2#38] parquet
结果:
+---------------------+-------+-----------------------+-------+
|decNum1 |intNum1|decNum2 |intNum2|
+---------------------+-------+-----------------------+-------+
|null |null |1111.000000000000000000|1 |
|22.000000000000000000|2 |2222.000000000000000000|2 |
|null |null |4444.000000000000000000|4 |
+---------------------+-------+-----------------------+-------+
对应的物理计划:
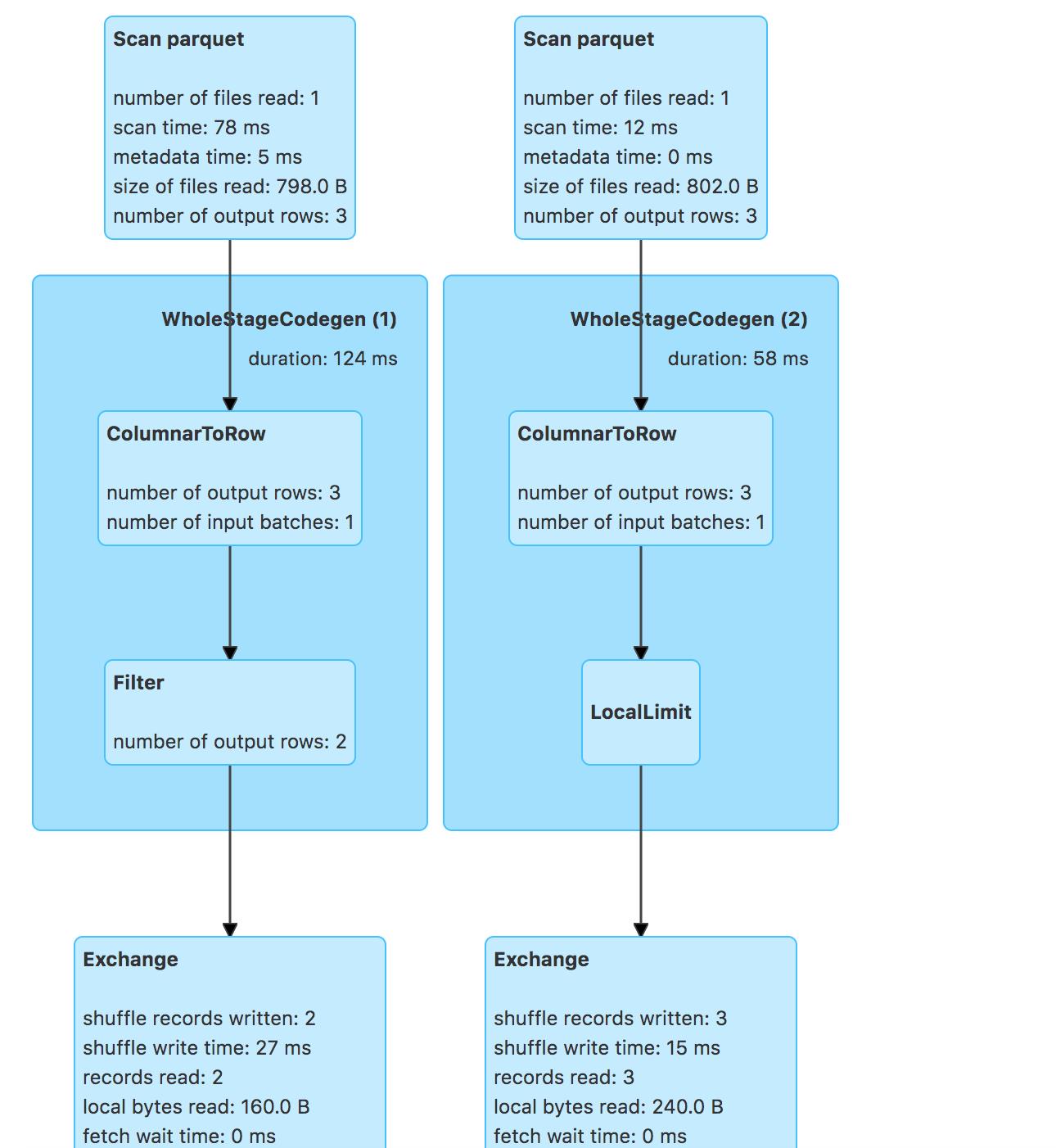
- rightouter join中谓词-补空表
运行:
val dfResult = spark.sql("select * from tbl1 right outer join tbl2 on intNum1 == intNum2 and intNum1 > 1")
PushDownPredicates规则会把补空表进行下推,如:
=== Applying Rule org.apache.spark.sql.catalyst.optimizer.PushDownPredicates ===
!Join RightOuter, ((intNum1#34 = intNum2#38) AND (intNum1#34 > 1)) Join RightOuter, (intNum1#34 = intNum2#38)
!:- Relation [decNum1#33,intNum1#34] parquet :- Filter (intNum1#34 > 1)
!+- Relation [decNum2#37,intNum2#38] parquet : +- Relation [decNum1#33,intNum1#34] parquet
! +- Relation [decNum2#37,intNum2#38] parquet
InferFiltersFromConstraints规则,会添加isnull的判断:
=== Applying Rule org.apache.spark.sql.catalyst.optimizer.InferFiltersFromConstraints ===
Join RightOuter, (intNum1#34 = intNum2#38) Join RightOuter, (intNum1#34 = intNum2#38)
!:- Filter (intNum1#34 > 1) :- Filter (isnotnull(intNum1#34) AND (intNum1#34 > 1))
: +- Relation [decNum1#33,intNum1#34] parquet : +- Relation [decNum1#33,intNum1#34] parquet
+- Relation [decNum2#37,intNum2#38] parquet +- Relation [decNum2#37,intNum2#38] parquet
结果:
+---------------------+-------+-----------------------+-------+
|decNum1 |intNum1|decNum2 |intNum2|
+---------------------+-------+-----------------------+-------+
|null |null |1111.000000000000000000|1 |
|22.000000000000000000|2 |2222.000000000000000000|2 |
|null |null |4444.000000000000000000|4 |
+---------------------+-------+-----------------------+-------+
对应的物理计划:
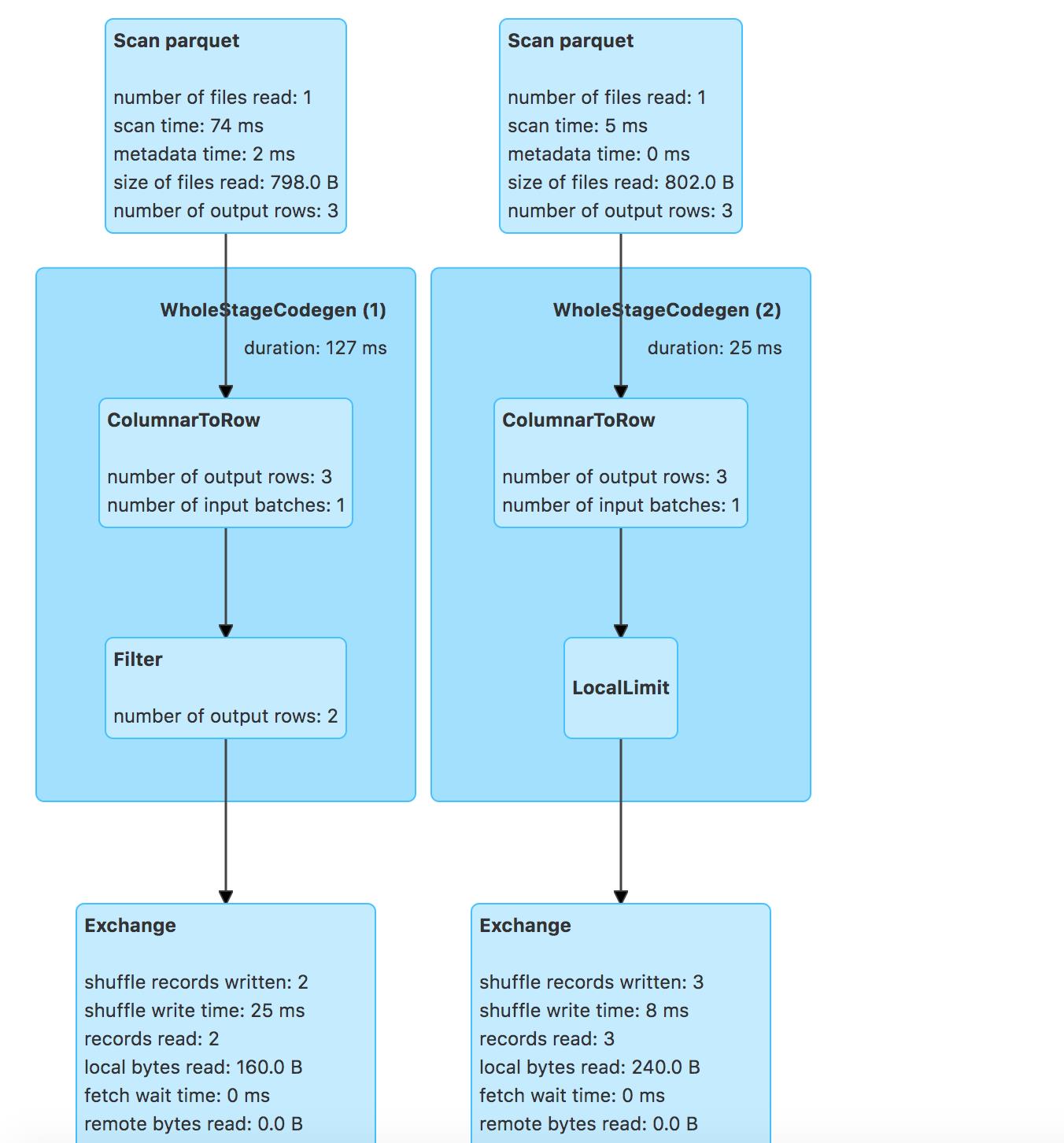
- rightouter join后谓词-留存表
运行:
val dfResult = spark.sql("select * from tbl1 right outer join tbl2 on intNum1 == intNum2 where intNum2 > 1")
PushDownPredicates规则会把留存表的谓词下推到join之后,如下:
=== Applying Rule org.apache.spark.sql.catalyst.optimizer.PushDownPredicates ===
!Filter (intNum2#38 > 1) Join RightOuter, (intNum1#34 = intNum2#38)
!+- Join RightOuter, (intNum1#34 = intNum2#38) :- Relation [decNum1#33,intNum1#34] parquet
! :- Relation [decNum1#33,intNum1#34] parquet +- Filter (intNum2#38 > 1)
+- Relation [decNum2#37,intNum2#38] parquet +- Relation [decNum2#37,intNum2#38] parquet
InferFiltersFromConstraints则会进行衍生,如下:
=== Applying Rule org.apache.spark.sql.catalyst.optimizer.InferFiltersFromConstraints ===
Join RightOuter, (intNum1#34 = intNum2#38) Join RightOuter, (intNum1#34 = intNum2#38)
!:- Relation [decNum1#33,intNum1#34] parquet :- Filter ((intNum1#34 > 1) AND isnotnull(intNum1#34))
!+- Filter (intNum2#38 > 1) : +- Relation [decNum1#33,intNum1#34] parquet
! +- Relation [decNum2#37,intNum2#38] parquet +- Filter (isnotnull(intNum2#38) AND (intNum2#38 > 1))
! +- Relation [decNum2#37,intNum2#38] parquet
结果:
+---------------------+-------+-----------------------+-------+
|decNum1 |intNum1|decNum2 |intNum2|
+---------------------+-------+-----------------------+-------+
|22.000000000000000000|2 |2222.000000000000000000|2 |
|null |null |4444.000000000000000000|4 |
+---------------------+-------+-----------------------+-------+
对应的物理计划:
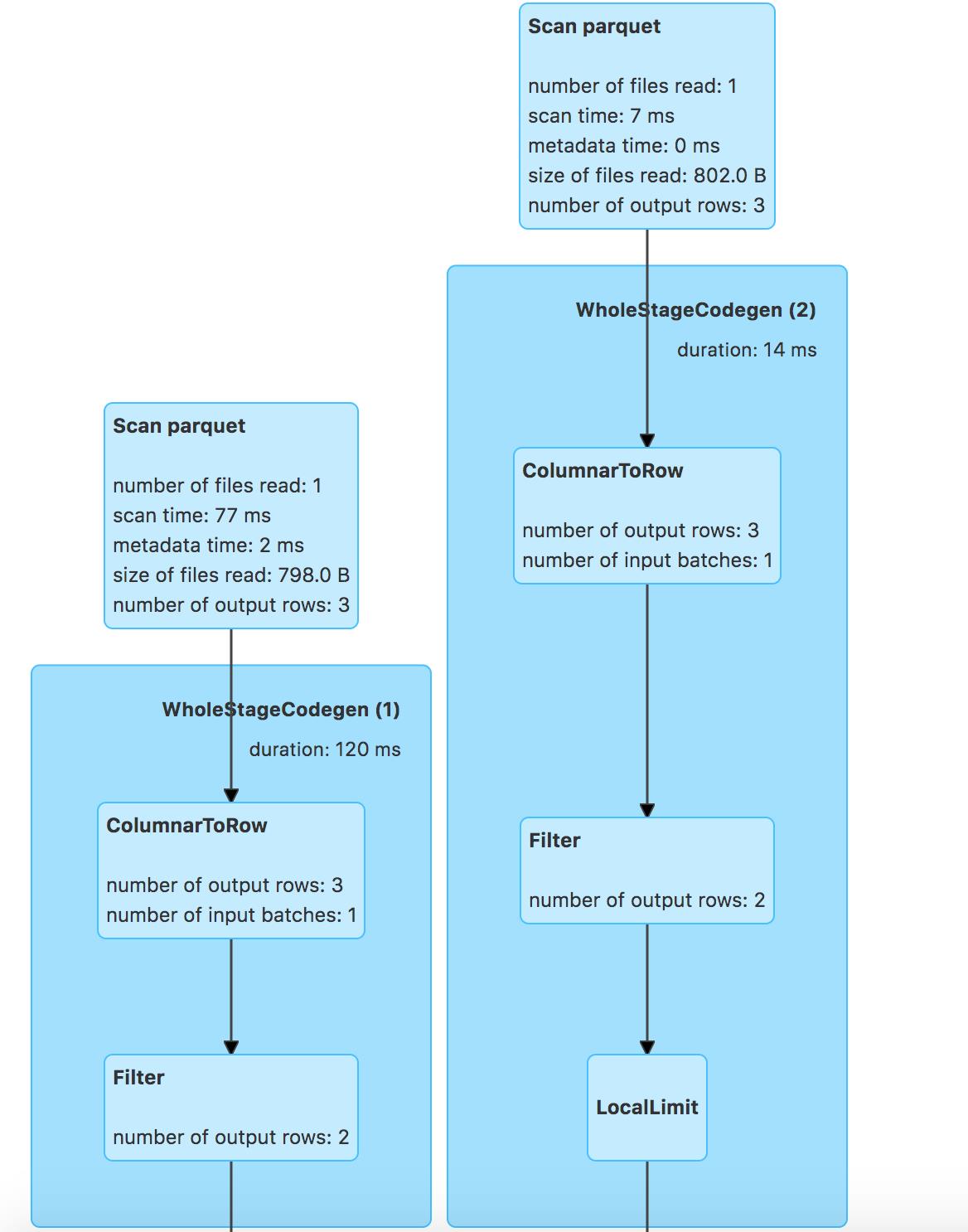
- rightouter join后谓词-补空表
运行:
val dfResult = spark.sql("select * from tbl1 right outer join tbl2 on intNum1 == intNum2 where intNum1 > 1")
EliminateOuterJoin的规则和PushDownPredicates以及InferFiltersFromConstraints的分析和 leftouter-join后谓词-补空表一样,此处不再累赘
结果:
+---------------------+-------+-----------------------+-------+
|decNum1 |intNum1|decNum2 |intNum2|
+---------------------+-------+-----------------------+-------+
|22.000000000000000000|2 |2222.000000000000000000|2 |
+---------------------+-------+-----------------------+-------+
对应的物理计划:
结论
| left join | 留存表 | 补空表 |
|---|---|---|
| join中谓词 | 不下推 | 下推 |
| join后谓词 | 下推 | 下推 |
| right join | 留存表 | 补空表 |
|---|---|---|
| join中谓词 | 不下推 | 下推 |
| join后谓词 | 下推 | 下推 |
合并一下就是
| outer join | 留存表 | 补空表 |
|---|---|---|
| join中谓词 | 不下推 | 下推 |
| join后谓词 | 下推 | 下推 |
对比之下,其实 理论上说的 join后谓词 补空表不下推和实践中得出来的下推还是有区别(不同点用黑体进行了区分),也就印证了那句话,实践中会对理论做优化,也和Paxos原理类似。
其实这区别的来源是spark增加了EliminateOuterJoin规则
以上是关于spark outer join push down filter rule(spark 外连接中的下推规则)的主要内容,如果未能解决你的问题,请参考以下文章