比特币非法地址交易识别
Posted nlp_qidian
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了比特币非法地址交易识别相关的知识,希望对你有一定的参考价值。
项目背景:
一个非法的比特币交易地址会进行很多次非法的交易。将一个非法的地址的交易行为可以刻画为一个有向或者无向的网络。那么对这个网络的特性,结构进行识别。来判别这个交易地址是不是一个非法的交易地址。
模型图:
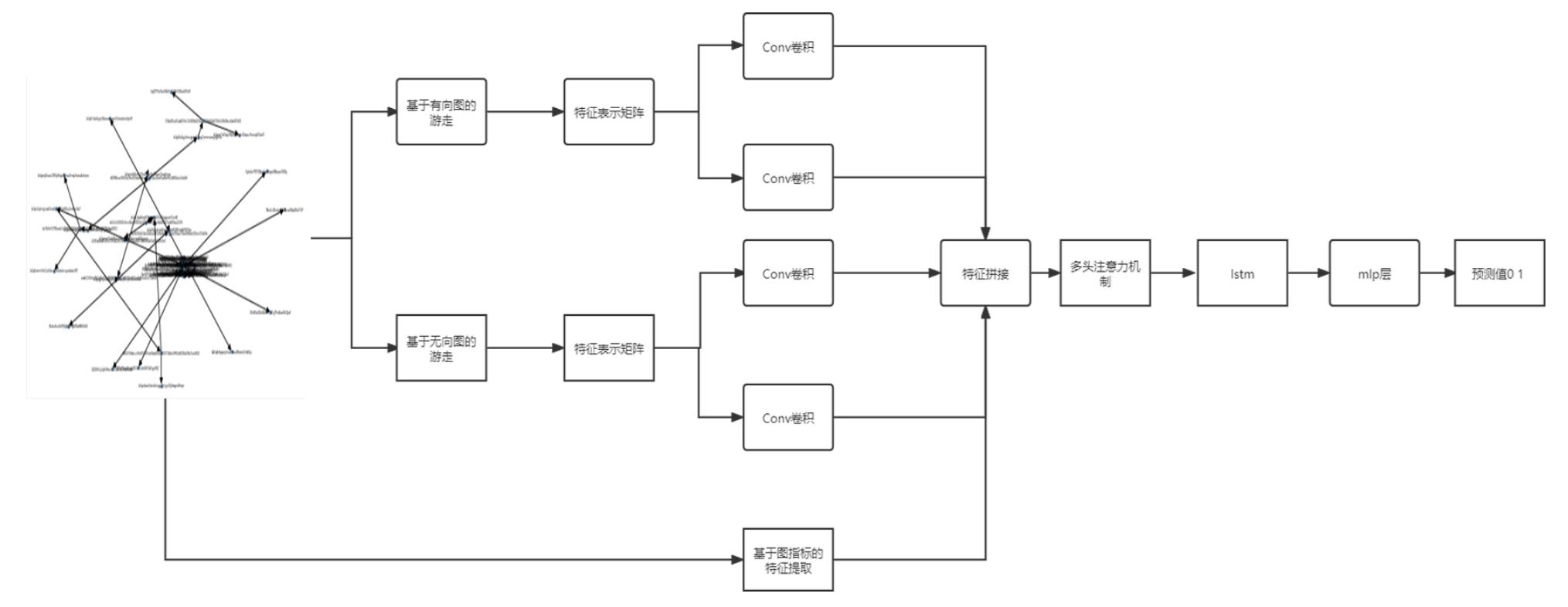
基于有向图和无向图进行随机游走操作,然后根据路径的信息进行特征添加,进行多分支卷积。
根据原始数据简历有向图和无向图,扑捉到图中的信息流向和图整个的结构分布。体现图的结构和信息流向特征。
主要代码:
import pandas as pd
import numpy as np
import random
import re,os
from collections import Counter
import networkx as nx
from keras_preprocessing import sequence
edges=pd.read_csv('train_data/train_data/address5/edges.csv')
nodes_addr=pd.read_csv('train_data/train_data/address5/nodes_addr.csv')
nodes_tx=pd.read_csv('train_data/train_data/address5/nodes_tx.csv')
# in_tx 处理 成 01 的方式
type_string_01=[]
for i in edges["type:string"]:
if i=="in_tx":
type_string_01.append(0)
else:
type_string_01.append(1)
edges["type:string"]=type_string_01
# 为属性值建立数组用于边权重索引属性值索引:
attr_list=edges[["amount:double","usd:double","p:double","idx:int"]].values
# edges 图中最主要的节点
Main_node=edges.values[0][0]
print(Main_node)
# 为所有出现的节点建立一个索引值 用序号为其做标记
node_index=
index_node=
nodes_sum=[]
for i in edges["source:START_ID"]:
nodes_sum.append(i)
for i in edges["target:END_ID"]:
nodes_sum.append(i)
nodes_sum=list(set(nodes_sum))
for index,i in enumerate(nodes_sum):
node_index[i]=''.join(re.findall("\\d+",i))
index_node[''.join(re.findall("\\d+",i))]=i
# print(node_index)
# print(index_node)
print(edges.values.shape)根据原始数据构建有向图:
# 基于 有向图
EDGES=[]
for idx,i in enumerate(edges.values):
hang=[]
# 添加节点 两个 是有向的
hang.append(i[0])
hang.append(i[1])
# 添加边的信息
weight=
weight["weight"]=int(idx)
hang.append(weight)
EDGES.append(hang)
# print(EDGES)
g=nx.DiGraph()
g.add_edges_from(EDGES)
print("边的数量",len(g.edges()))
print("节点个数",len(g.nodes()))
# print(g.edges.data())
# print(g.edges[1,2]["weight"])
# print(g[1])
# print(list(g.neighbors(2))) # 邻居也是有向的
# print("节点4和节点1的共同邻居:",list(nx.common_neighbors(g,2,3)))
# - `node_size`: 指定节点的尺寸大小(默认是300)
# - `node_color`: 指定节点的颜色 (默认是红色,可以用字符串简单标识颜色,例如'r'为红色,'b'为绿色等)
# - `node_shape`: 节点的形状(默认是圆形,用字符串'o'标识)
# - `alpha`: 透明度 (默认是1.0,不透明,0为完全透明)
# - `width`: 边的宽度 (默认为1.0)
# - `edge_color`: 边的颜色(默认为黑色)
# - `style`: 边的样式(默认为实现,可选: solid|dashed|dotted,dashdot)
# - `with_labels`: 节点是否带标签(默认为True)
# - `font_size`: 节点标签字体大小 (默认为12)
# - `font_color`: 节点标签字体颜色(默认为黑色)
nx.draw(g,with_labels=True,node_shape="*",font_size=3,node_size=5)
# nx.draw(g,node_shape="*",font_size=1,node_size=2)根据有向图进行游走:
# 基于有向图的游走 强特征提取
random.seed(1)# 设置随机种子用于后边的结果的复现
np.random.seed(0)
num_walks=10
walk_length=10
walks=[]
for i in range(num_walks):
for node in g.nodes():
walk=[]
walk.append(node)
while(len(walk)<walk_length):
node_list=list(g.neighbors(node))
if len(node_list)==0: # 假设在有向图中这个节点没有有向的邻居节点
break
# print("node_list",node_list)
node=np.random.choice(node_list,1).item()
# print(node)
# print("*"*100)
walk.append(node)
if len(walk)==walk_length:
walks.append(walk)
print(len(walks))
# print(walks)
# for i in walks:
# print(len(i))
print(np.array(walks).shape)
# 用节点的 边的信息来把 节点序列替换掉: edges中 存在个节点之间存在两条边的情况
walks_data=[]
for walk in walks:
walk_data=[]
for idx,node in enumerate(walk):
if node in list(nodes_addr["account:ID"]):
node_data=nodes_addr.loc[nodes_addr["account:ID"]==node,:].values[0][1]
walk_data.append(node_data)
if node in list(nodes_tx["tx_hash:ID"]):
node_data=nodes_tx.loc[nodes_tx["tx_hash:ID"]==node,:].values[0][2:10]
for i in node_data:
walk_data.append(i)
if idx != len(walk)-1:
currt_node=node
next_node=walk[idx+1]
edge_data=edges.loc[(edges["source:START_ID"]==currt_node)&(edges["target:END_ID"]==next_node),:].values[:,3:6].reshape(1,-1)[0]
# 存在个两个节点之间存在两条边的情况 所以不能直接进行相加处理 要充分的展示出来
for i in edge_data:
walk_data.append(i)
walks_data.append(walk_data)
# break
# 对 walks_data中的数据做补齐操作
MaxLen=max(len(i)for i in walks_data)
walks_data=sequence.pad_sequences(walks_data,maxlen=MaxLen,value=0,padding='post')
# 用 0填充
walks_data=np.array(walks_data)
print(walks_data.shape)
根据原始数据构建无向图:
EDGES=[]
for idx,i in enumerate(edges.values):
hang=[]
# 添加节点 两个 是有向的
hang.append(i[0])
hang.append(i[1])
# 添加边的信息
weight=
weight["weight"]=int(idx)
hang.append(weight)
EDGES.append(hang)
# print(EDGES)
g=nx.Graph()
g.add_edges_from(EDGES)
print("边的数量",len(g.edges()))
print("节点个数",len(g.nodes()))
# print(g.edges.data())
# print(g.edges[1,2]["weight"])
# print(g[1])
# print(list(g.neighbors(2))) # 邻居也是有向的
# print("节点4和节点1的共同邻居:",list(nx.common_neighbors(g,2,3)))
# - `node_size`: 指定节点的尺寸大小(默认是300)
# - `node_color`: 指定节点的颜色 (默认是红色,可以用字符串简单标识颜色,例如'r'为红色,'b'为绿色等)
# - `node_shape`: 节点的形状(默认是圆形,用字符串'o'标识)
# - `alpha`: 透明度 (默认是1.0,不透明,0为完全透明)
# - `width`: 边的宽度 (默认为1.0)
# - `edge_color`: 边的颜色(默认为黑色)
# - `style`: 边的样式(默认为实现,可选: solid|dashed|dotted,dashdot)
# - `with_labels`: 节点是否带标签(默认为True)
# - `font_size`: 节点标签字体大小 (默认为12)
# - `font_color`: 节点标签字体颜色(默认为黑色)
nx.draw(g,with_labels=True,node_shape="*",font_size=3,node_size=5)
# nx.draw(g,node_shape="*",font_size=1,node_size=2)根据无向图进行游走:
random.seed(1)# 设置随机种子用于后边的结果的复现
np.random.seed(0)
num_walks=10
walk_length=10
walks=[]
for i in range(num_walks):
for node in g.nodes():
walk=[]
walk.append(node)
while(len(walk)<walk_length):
node_list=list(g.neighbors(node))
if len(node_list)==0: # 假设在有向图中这个节点没有有向的邻居节点
break
# print("node_list",node_list)
node=np.random.choice(node_list,1).item()
# print(node)
# print("*"*100)
walk.append(node)
if len(walk)==walk_length:
walks.append(walk)
print(len(walks))
# print(walks)
# for i in walks:
# print(len(i))
print(np.array(walks).shape)
# 用节点的 边的信息来把 节点序列替换掉: edges中 存在个节点之间存在两条边的情况
walks_data=[]
for walk in walks:
walk_data=[]
for idx,node in enumerate(walk):
if node in list(nodes_addr["account:ID"]):
node_data=nodes_addr.loc[nodes_addr["account:ID"]==node,:].values[0][1]
walk_data.append(node_data)
if node in list(nodes_tx["tx_hash:ID"]):
node_data=nodes_tx.loc[nodes_tx["tx_hash:ID"]==node,:].values[0][2:10]
for i in node_data:
walk_data.append(i)
if idx != len(walk)-1:
currt_node=node
next_node=walk[idx+1]
edge_data=edges.loc[(edges["source:START_ID"]==currt_node)&(edges["target:END_ID"]==next_node),:].values[:,3:6].reshape(1,-1)[0]
# 存在个两个节点之间存在两条边的情况 所以不能直接进行相加处理 要充分的展示出来
for i in edge_data:
walk_data.append(i)
walks_data.append(walk_data)
# break
# 对 walks_data中的数据做补齐操作
MaxLen=max(len(i)for i in walks_data)
walks_data=sequence.pad_sequences(walks_data,maxlen=MaxLen,value=0,padding='post')
# 用 0填充
walks_data=np.array(walks_data)
print(walks_data.shape)
建模:pytorch 框架
导入库:
import pandas as pd
from collections import Counter
import torch
from torch import nn
from torch import optim
import math,os
import tensorflow as tf
import keras
import numpy as np
import pandas as pd
from sklearn.metrics import f1_score
import warnings
import re
import jieba
warnings.filterwarnings('ignore')
from tqdm import tqdm
from sklearn.model_selection import train_test_split
from collections import Counter
import matplotlib.pyplot as plt
plt.rcParams["font.sans-serif"] = ['Simhei']
plt.rcParams["axes.unicode_minus"] = False
import re
from pylab import *
import numpy as np
from sklearn.model_selection import train_test_split
import torch
import torch.nn as nn
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
import pandas as pd
import numpy as np
import random
import re,os
from collections import Counter
import networkx as nx
from keras_preprocessing import sequence进行有向图和无向图的特征建模个游走
# 有向图特征提取
def directed_graph_walk(edges,nodes_addr,nodes_tx,Main_node,num_walks,walk_length): # 无有向图读取文件
# random.seed(1)# 设置随机种子用于后边的结果的复现
# np.random.seed(0)
Main_node=edges.values[0][0] # 最主要的节点地址
EDGES=[]
for idx,i in enumerate(edges.values):
hang=[]
hang.append(i[0])
hang.append(i[1])
weight=
weight["weight"]=int(idx)
hang.append(weight)
EDGES.append(hang)
g=nx.DiGraph()
g.add_edges_from(EDGES)
walks=[]
for i in range(num_walks):
for node in g.nodes():
walk=[]
walk.append(node)
while(len(walk)<walk_length):
node_list=list(g.neighbors(node))
if len(node_list)==0: # 假设在有向图中这个节点没有有向的邻居节点
break
node=np.random.choice(node_list,1).item()
walk.append(node)
if len(walk)==walk_length:
if Main_node in walk:
walks.append(walk)
# 用节点的 边的信息来把 节点序列替换掉: edges中 存在个节点之间存在两条边的情况
walks_data=[]
for walk in walks:
walk_data=[]
for idx,node in enumerate(walk):
if node in list(nodes_addr["account:ID"]):
node_data=nodes_addr.loc[nodes_addr["account:ID"]==node,:].values[0][1]
walk_data.append(node_data)
if node in list(nodes_tx["tx_hash:ID"]):
node_data=nodes_tx.loc[nodes_tx["tx_hash:ID"]==node,:].values[0][2:10]
for i in node_data:
walk_data.append(i)
if idx != len(walk)-1:
currt_node=node
next_node=walk[idx+1]
edge_data=edges.loc[(edges["source:START_ID"]==currt_node)&(edges["target:END_ID"]==next_node),:].values[:,3:6].reshape(1,-1)[0]
# 存在个两个节点之间存在两条边的情况 所以不能直接进行相加处理 要充分的展示出来
for i in edge_data:
walk_data.append(i)
if len(walk_data)> 120:
walk_data=walk_data[0:120]
walks_data.append(walk_data)
# 对 walks_data中的数据做补齐操作
if np.array(walks_data).shape[0]>20: # 数据特征太少的舍弃掉
MaxLen=120
walks_data=sequence.pad_sequences(walks_data,maxlen=MaxLen,value=0,padding='post')
walks_data=np.array(walks_data)
if int(walks_data.shape[0])<200:
walks_data = np.pad(walks_data,((0,int(200-walks_data.shape[0])),(0,0)), 'constant',constant_values=(0,0))# constant连续一样的值填充
else:
walks_data=walks_data[0:200]
return walks_data
else:
return walks_data
# 无向图特征提取
def Undirected_graph_walk(edges,nodes_addr,nodes_tx,Main_node,num_walks,walk_length): # 无有向图读取文件
# random.seed(1)# 设置随机种子用于后边的结果的复现
# np.random.seed(0)
EDGES=[]
for idx,i in enumerate(edges.values):
# edges 图中最主要的节点
hang=[]
# 添加节点 两个 是有向的
hang.append(i[0])
hang.append(i[1])
# 添加边的信息
weight=
weight["weight"]=int(idx)
hang.append(weight)
EDGES.append(hang)
g=nx.Graph()
g.add_edges_from(EDGES)
walks=[]
for i in range(num_walks):
for node in g.nodes():
walk=[]
walk.append(node)
while(len(walk)<walk_length):
node_list=list(g.neighbors(node))
if len(node_list)==0: # 假设在有向图中这个节点没有有向的邻居节点
break
node=np.random.choice(node_list,1).item()
walk.append(node)
if len(walk)==walk_length:
if Main_node in walk:
walks.append(walk)
# 用节点的 边的信息来把 节点序列替换掉: edges中 存在个节点之间存在两条边的情况
walks_data=[]
for walk in walks:
walk_data=[]
for idx,node in enumerate(walk):
if node in list(nodes_addr["account:ID"]):
node_data=nodes_addr.loc[nodes_addr["account:ID"]==node,:].values[0][1]
walk_data.append(node_data)
if node in list(nodes_tx["tx_hash:ID"]):
node_data=nodes_tx.loc[nodes_tx["tx_hash:ID"]==node,:].values[0][2:10]
for i in node_data:
walk_data.append(i)
if idx != len(walk)-1:
currt_node=node
next_node=walk[idx+1]
edge_data=edges.loc[(edges["source:START_ID"]==currt_node)&(edges["target:END_ID"]==next_node),:].values[:,3:6].reshape(1,-1)[0]
# 存在个两个节点之间存在两条边的情况 所以不能直接进行相加处理 要充分的展示出来
for i in edge_data:
walk_data.append(i)
if len(walk_data)> 120:
walk_data=walk_data[0:120]
walks_data.append(walk_data)
# print("无向图",np.array(walks_data).shape)
# 对 walks_data中的数据做补齐操作
MaxLen=120
walks_data=sequence.pad_sequences(walks_data,maxlen=MaxLen,value=0,padding='post')
walks_data=np.array(walks_data)
if int(walks_data.shape[0])<200:
walks_data = np.pad(walks_data,((0,int(200-walks_data.shape[0])),(0,0)), 'constant',constant_values=(0,0))# constant连续一样的值填充
else:
walks_data=walks_data[0:200]
return walks_data
# 正样本函数加载
def load_g(tree_catalogue_idx):
edges=pd.read_csv("train_data/train_data/address"+str(tree_catalogue_idx)+"/edges.csv")
edges=edges.drop(['amount_and_percentage:string'],axis=1)# 删除一列无关紧要的
nodes_addr=pd.read_csv("train_data/train_data/address"+str(tree_catalogue_idx)+'/nodes_addr.csv')
nodes_tx=pd.read_csv("train_data/train_data/address"+str(tree_catalogue_idx)+'/nodes_tx.csv')
# in_tx 处理 成 01 的方式
type_string_01=[]
for i in edges["type:string"]:
if i=="in_tx":
type_string_01.append(0)
else:
type_string_01.append(1)
edges["type:string"]=type_string_01
# 为属性值建立数组用于边权重索引属性值索引:
attr_list=edges[["amount:double","usd:double","p:double","idx:int"]].values
# edges 图中最主要的节点
Main_node=edges.values[0][0]
return edges,nodes_addr,nodes_tx,Main_node
# 负样本函数加载
def load_g_0(tree_catalogue_idx):
edges=pd.read_csv("train_data3/train_data3/address"+str(tree_catalogue_idx)+"/edges.csv")
edges=edges.drop(['amount_and_percentage:string'],axis=1)# 删除一列无关紧要的
nodes_addr=pd.read_csv("train_data3/train_data3/address"+str(tree_catalogue_idx)+'/nodes_addr.csv')
nodes_tx=pd.read_csv("train_data3/train_data3/address"+str(tree_catalogue_idx)+'/nodes_tx.csv')
# in_tx 处理 成 01 的方式
type_string_01=[]
for i in edges["type:string"]:
if i=="in_tx":
type_string_01.append(0)
else:
type_string_01.append(1)
edges["type:string"]=type_string_01
# 为属性值建立数组用于边权重索引属性值索引:
attr_list=edges[["amount:double","usd:double","p:double","idx:int"]].values
# edges 图中最主要的节点
Main_node=edges.values[0][0]
return edges,nodes_addr,nodes_tx,Main_node
# 正样本读取
# 读取目录下所有的文件
data_catalogue= os.listdir("train_data/train_data")
train_x_class_1=[]
print("开始取正样本")
for catalogue in data_catalogue:#先取几个图的数据做测试
train_one_g=[]
tree_catalogue_idx=str(re.findall("\\d+",catalogue)[0])
e=pd.read_csv("train_data/train_data/address"+str(tree_catalogue_idx)+"/edges.csv")
if len(e.values)>5:
edges,nodes_addr,nodes_tx,Main_node=load_g(tree_catalogue_idx)
num_walks=10
walk_length=5
directed_walks_data=directed_graph_walk(edges,nodes_addr,nodes_tx,Main_node,num_walks,walk_length)
num_walks=10
walk_length=5
Undirected_walks_data=Undirected_graph_walk(edges,nodes_addr,nodes_tx,Main_node,num_walks,walk_length)
if len(directed_walks_data)>20 :
print("第几个图:",catalogue)
print("有向图",np.array(directed_walks_data).shape)
print("有向图",np.array(Undirected_walks_data).shape)
print("----------------------------------")
train_one_g.append(directed_walks_data)
train_one_g.append(Undirected_walks_data)
train_x_class_1.append(train_one_g)
if len(train_x_class_1)==100:
break
# 负样本读取
class_0_data_catalogue= os.listdir("train_data3/train_data3")
train_x_class_0=[]
print("开始取负样本")
for catalogue in class_0_data_catalogue:#先取几个图的数据做测试
train_one_g=[]
tree_catalogue_idx=str(re.findall("\\d+",catalogue)[0])
# 测试是否是空 空则跳过
e=pd.read_csv("train_data3/train_data3/address"+str(tree_catalogue_idx)+"/edges.csv")
if len(e.values)>5:
edges,nodes_addr,nodes_tx,Main_node=load_g_0(tree_catalogue_idx)
num_walks=10
walk_length=5
directed_walks_data=directed_graph_walk(edges,nodes_addr,nodes_tx,Main_node,num_walks,walk_length)
# print("有向图",np.array(directed_walks_data).shape)
num_walks=10
walk_length=5
Undirected_walks_data=Undirected_graph_walk(edges,nodes_addr,nodes_tx,Main_node,num_walks,walk_length)
if len(directed_walks_data)>20 :
print("第几个图:",catalogue)
print("有向图",np.array(directed_walks_data).shape)
print("有向图",np.array(Undirected_walks_data).shape)
print("----------------------------------")
train_one_g.append(directed_walks_data)
train_one_g.append(Undirected_walks_data)
train_x_class_0.append(train_one_g)
if len(train_x_class_0)==100:
break
构建数据加载类:
# 数据类加载
from sklearn.model_selection import train_test_split
from torch.utils.data import random_split
from torch.utils.data import Dataset, DataLoader
train_x=train_x_class_1 + train_x_class_0
tranin_y_0=[ 0 for i in range(len(train_x_class_0))]
tranin_y_1=[ 1 for i in range(len(train_x_class_1))]
train_y=tranin_y_1 + tranin_y_0
# X_train, X_test, y_train, y_test = train_test_split(train_x,train_y, test_size=0.1, random_state=1)
class mydataset(Dataset):
def __init__(self): # 读取加载数据
self._x=torch.FloatTensor(np.array(train_x).astype(float))
self._y=torch.FloatTensor(np.array(train_y).astype(float))
self._len=len(train_x)
def __getitem__(self,item):
return self._x[item],self._y[item]
def __len__(self):# 返回整个数据的长度
return self._len
data=mydataset()
print(data._len)
# 划分 训练集 测试集
torch.manual_seed(0)
train_data,test_data=random_split(data,[round(0.9*data._len),round(0.1*data._len)])#这个参数有的版本没有 generator=torch.Generator().manual_seed(0)
# 随机混乱顺序划分的 四舍五入
# 训练 loader
train_loader =DataLoader(train_data, batch_size = 10, shuffle = True, num_workers = 0 , drop_last=False)
# 测试 loader
test_loader =DataLoader(test_data, batch_size =10, shuffle = True, num_workers = 0 , drop_last=False)
# dorp_last 是说最后一组数据不足一个batch的时候 能继续用还是舍弃。 # num_workers 多少个进程载入数据
# # 训练
# for step,(train_x,train_y) in enumerate(train_loader):
# print(step,':',(train_x.shape,train_y.shape),(train_x,train_y))
# print("------------------------------------------------------------------------------------------------------")
# # 测试
# for step,(test_x,test_y) in enumerate(test_loader):
# print(step,':',(test_x.shape,test_y.shape),(test_x,test_y))定义模型训练预测:
# 模型定义
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
class conv_LSTM(nn.Module): # 注意Module首字母需要大写
def __init__(self, ):
super().__init__()
input_size = 106
hidden_size = 106
input_size = 106
self.conv1_1 = nn.Conv2d(in_channels=1,out_channels=1,kernel_size=(2,15))
self.conv1_2 = nn.Conv2d(in_channels=1,out_channels=1,kernel_size=(10,15))
self.conv2_1 = nn.Conv2d(in_channels=1,out_channels=1,kernel_size=(2,15))
self.conv2_2 = nn.Conv2d(in_channels=1,out_channels=1,kernel_size=(10,15))
# input_size:输入lstm单元向量的长度 ,hidden_size输出lstm单元向量的长度。也是输入、输出隐藏层向量的长度
self.lstm = nn.LSTM(input_size, hidden_size, num_layers=1) # ,batch_first=True
# --------------------------------------------------------------------------
self.multihead_Linear_k = nn.Linear(hidden_size, hidden_size)
self.multihead_Linear_q = nn.Linear(hidden_size, hidden_size)
self.multihead_Linear_v = nn.Linear(hidden_size, hidden_size)
self.multihead_attn = nn.MultiheadAttention(embed_dim=hidden_size, num_heads=2)
# 因此模型维度 hidden_size 必须可以被头部数量整除
# --------------------------------------------------------------------------
self.lstm_2 = nn.LSTM(hidden_size, hidden_size, num_layers=1)
# --------------------------------------------------------------------------
self.linear_1 = nn.Linear(hidden_size, 1)
self.ReLU = nn.ReLU()
self.linear_2 = nn.Linear(780,2)
self.softmax=nn.Softmax(dim=1)
def forward(self,x,batch_size):
# x [10, 2, 500, 120]
x=x.transpose(1,0)
x1=x[0]
x2=x[1]
# 上边这三行这样取可能有错误
x1=x1.to(device)
x2=x2.to(device)
x1=x1.unsqueeze(1)
x2=x2.unsqueeze(1)
# self.conv1(x1)输入:x[ batch_size, channels, height_1, width_1 ]
x1_1 =self.conv1_1(x1)
x1_2 =self.conv1_2(x1)
x2_1 =self.conv2_1(x2)
x2_2 =self.conv2_2(x2)
x=torch.cat((x1_1, x1_2,x2_1,x2_2), 2)
x=x.squeeze(1)
x = x.transpose(1,0)
x=self.ReLU(x)
# 输入 lstm的矩阵形状是:[序列长度,batch_size,每个向量的维度] [序列长度,batch, 64]
lstm_out, h_n = self.lstm(x, None)
# print(lstm_out.shape) #[序列长度,batch_size, 64]
# query,key,value的输入形状一定是 [sequence_size, batch_size, emb_size] 比如:value.shape torch.Size( [序列长度,batch_size, 64])
query = self.multihead_Linear_q(lstm_out)
key = self.multihead_Linear_k(lstm_out)
value = self.multihead_Linear_v(lstm_out)
# multihead_attention 输入矩阵计算 :
attn_output, attn_output_weights = self.multihead_attn(query, key, value)
# 输出 attn_output.shape torch.Size([序列长度,batch_size, 64])
lstm_out_2, h_n_2 = self.lstm_2(attn_output, h_n)
lstm_out_2 = lstm_out_2.transpose(0, 1)
# print("lstm_out_2.shape",lstm_out_2.shape)# lstm_out_2.shape torch.Size([20, 600, 128])
# [序列长度,batch_size, 64]
# prediction=lstm_out_2[-1].to(device)
# print(prediction.shape)# torch.Size([batch_size, 64])
# 使用卷积
# 两个全连接+激活函数
prediction = self.linear_1(lstm_out_2)
prediction = prediction.squeeze(2)
prediction = self.ReLU(prediction)
prediction = self.linear_2(prediction)
prediction = prediction.squeeze(1)
prediction=self.softmax(prediction)
return prediction
model = conv_LSTM().to(device)
loss_function = torch.nn.CrossEntropyLoss().to(device)# 损失函数的计算 交叉熵损失函数计算
optimizer = torch.optim.Adam(model.parameters(), lr=0.001) # 建立优化器实例
batch_size=64
train_loader =DataLoader(train_data, batch_size =batch_size, shuffle = True, num_workers = 0 , drop_last=False)
criterion = torch.nn.CrossEntropyLoss() # 损失函数的计算 交叉熵损失函数计算
sum_train_epoch_loss=[] # 存储每个epoch 下 训练train数据的loss
sum_test_epoch_loss=[] # 存储每个epoch 下 测试 test数据的loss
# 这个函数是测试用来测试x_test y_test 数据 函数
def eval_test(model): # 返回的是这10个 测试数据的平均loss
test_epoch_loss = []
with torch.no_grad():
optimizer.zero_grad()
for step, (test_x, test_y) in enumerate(test_loader):
y_pre = model(test_x, batch_size).to(device)
test_y = test_y.to(device)
test_y =test_y .long()
test_loss = loss_function(y_pre, test_y)
test_epoch_loss.append(test_loss.item())
return np.mean(test_epoch_loss)
best_test_loss=10000
epochs=100
# 开始训练
for epoch in range(epochs):
epoch_loss=[]
for step,(train_x,train_y) in enumerate(train_loader):
y_pred = model(train_x,batch_size).to(device)
train_y=train_y.to(device)
single_loss = loss_function(y_pred,train_y.long())
del train_y
del train_x
del y_pred
epoch_loss.append(single_loss.item())
single_loss.backward()#调用backward()自动生成梯度
optimizer.step()#使用optimizer.step()执行优化器,把梯度传播回每个网络
train_epoch_loss=np.mean(epoch_loss)
test_epoch_loss=eval_test(model)#测试数据的平均loss
sum_train_epoch_loss.append(train_epoch_loss)
sum_test_epoch_loss.append(test_epoch_loss)
if test_epoch_loss<best_test_loss:
best_test_loss=test_epoch_loss
print("best_test_loss",best_test_loss)
best_model=model
print("epoch:" + str(epoch) + " train_epoch_loss: " + str(train_epoch_loss) + " test_epoch_loss: " + str(test_epoch_loss))
torch.save(best_model, 'best_model.pth')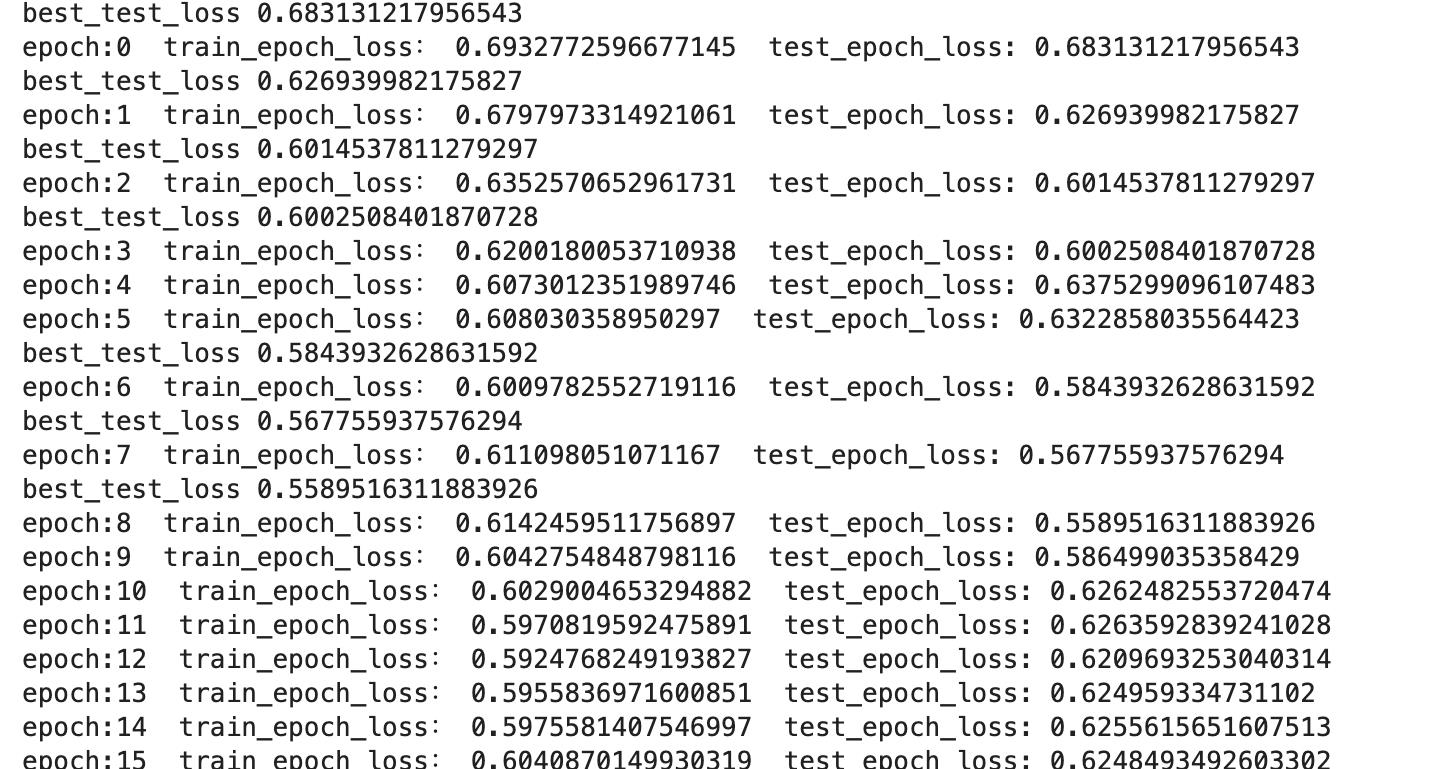
模型结果预测:
from sklearn.metrics import accuracy_score
#模型加载: 进行预测数据预测
test_loader =DataLoader(test_data, batch_size =20, shuffle = True, num_workers = 0 , drop_last=False)
model.load_state_dict(torch.load('75best_model.pth').cpu().state_dict())
model.eval()
with torch.no_grad():
optimizer.zero_grad()
for step, (test_x, test_y) in enumerate(test_loader):
y_pre = model(test_x,20).cpu()
y_pre=torch.argmax(y_pre,dim=1)
print(y_pre)
print(test_y)
accuracy=accuracy_score(test_y, y_pre)
print(accuracy)0.75准确率
loss图:
# 画图 loss损失函数
fig = plt.figure(facecolor='white', figsize=(10,7 ))
plt.xlabel('第几个epoch')
plt.ylabel('loss值')
plt.xlim(xmax=len(sum_train_epoch_loss),xmin=0)
plt.ylim(ymax=max(sum_train_epoch_loss),ymin=0)
#画两条(0-9)的坐标轴并设置轴标签x,y
x1 =[i for i in range(0,len(sum_train_epoch_loss),1)] # 随机产生300个平均值为2,方差为1.2的浮点数,即第一簇点的x轴坐标
y1 = sum_train_epoch_loss # 随机产生300个平均值为2,方差为1.2的浮点数,即第一簇点的y轴坐标
x2 = [i for i in range(0,len(sum_test_epoch_loss),1)]
y2 = sum_test_epoch_loss
colors1 = '#00CED4' #点的颜色
colors2 = '#DC143C'
area = np.pi * 4**1 # 点面积
# 画散点图
plt.scatter(x1, y1, s=area, c=colors1, alpha=0.4, label='train_loss')
plt.scatter(x2, y2, s=area, c=colors2, alpha=0.4, label='val_loss')
# plt.plot([0,9.5],[9.5,0],linewidth = '0.5',color='#000000')
plt.legend()
plt.savefig('loss曲线.png', dpi=300)
plt.show()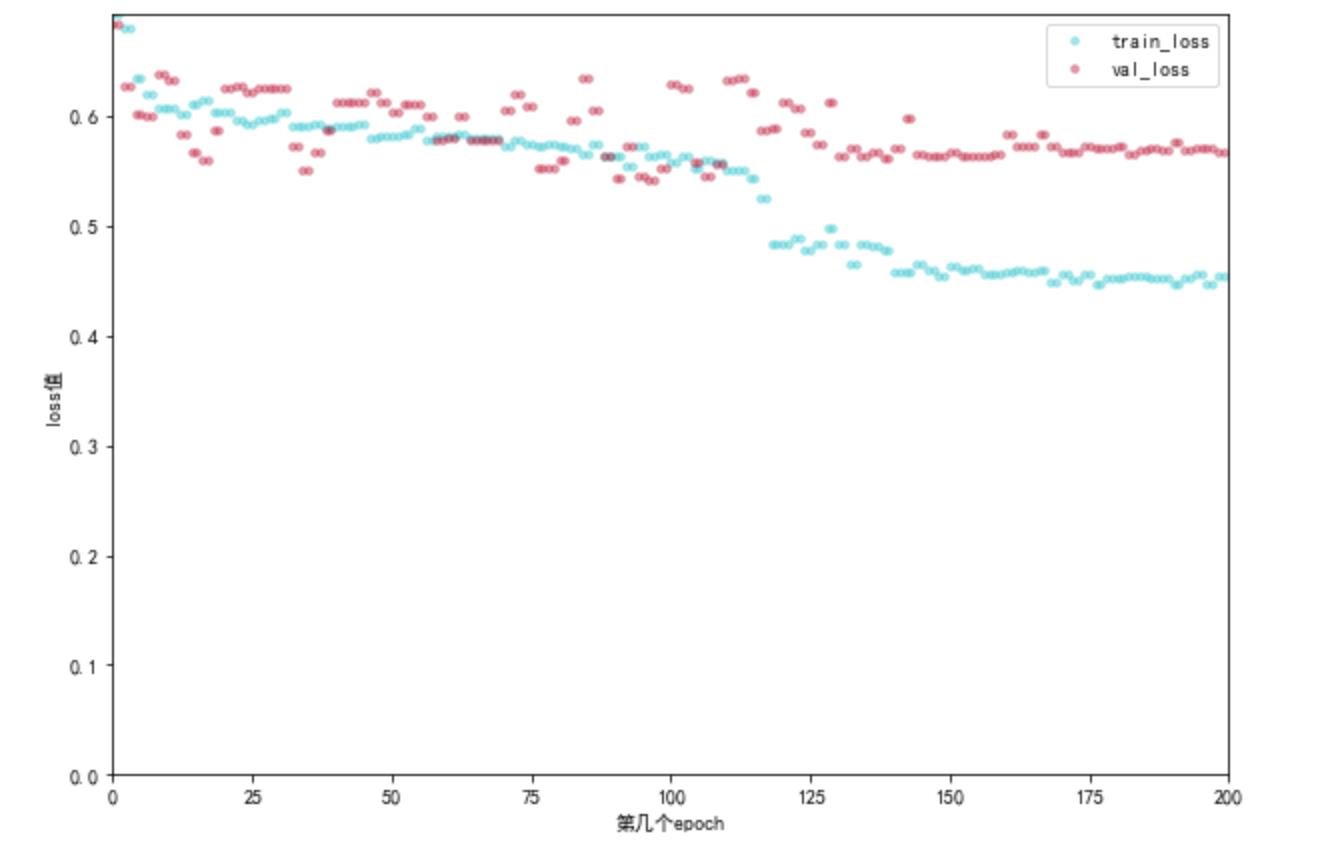
请给个赞+收藏、分享不易!
以上是关于比特币非法地址交易识别的主要内容,如果未能解决你的问题,请参考以下文章