RASADIET:Dual Intent and Entity Transformer
Posted 卓寿杰SoulJoy
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了RASADIET:Dual Intent and Entity Transformer相关的知识,希望对你有一定的参考价值。
最近工作中使用到rasa,其nlu部分有一个rasa自己提出的DIETClassifier框架组建,可用于意图分类与实体识别。今天有空,就来研究下它~
论文地址:https://github.com/RasaHQ/DIET-paper
1. 简介
先总结下DIET出彩的地方:
- DIET是一种用于意图分类和实体识别的多任务体系结构。
- 它能够以即插即用的方式结合语言模型的预训练单词嵌入,并将它们与单词和字符级 n-gram 稀疏特征结合起来。
- 实验表明,即使没有预训练的嵌入,仅使用单词和字符级 n-gram 稀疏特征,DIET 仍可以在复杂 NLU 数据集上取得state of art的结果。
- 添加预训练语言模型的单词和句子嵌入,可进一步提高所有任务的整体准确性。
- 性能最好的模型明显优于fine-tune的 BERT,训练速度快六倍。
2. 框架介绍
整体框架:
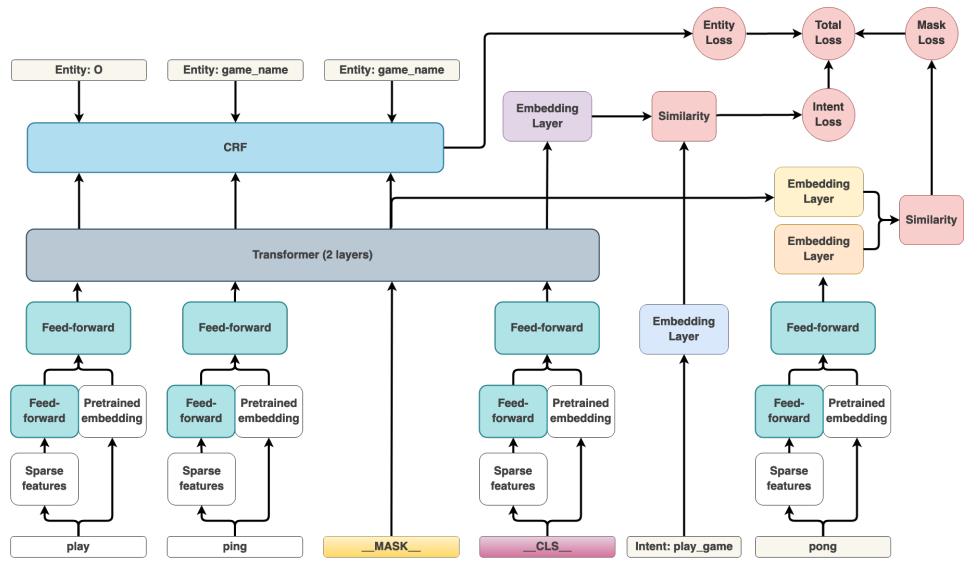
下面,我们结合上图进行逐个模块的讲解
2.1 Featurization
- token化之后,在每个句子后面添加一个特殊的分类token:_CLS_
- 每个token都会经过稀疏特征表示(one-hot编码以及n-grams(n < 5)的multi-hot编码)+全连接 与 稠密特征表示(如 ConveRT、BERT或 GloVe)。其中全连接网络权重是共享的,且输出的维度与稠密特征表示一致。
- 最好全连通层的输出与密集特征concatenate起来,再输入到一个全连接网络
2.2 Transformer
使用一个2层的transformer和相对位置attention,对整个句子进行encode,由于transformer架构要求它的输入与transformer层的维度相同,因此,concatenate后的特征通过另一个全连接层,在所有序列步骤中共享权值,以匹配transformer层的维度,在实验中是256维。
2.3 NER
通过CRF)在tranformer输出序列之上标记一个与token输入序列对应的层来预测实体。
2.4 Intent Classification
将transformer输出的__CLS__token表示 和 意图标签表示的语义向量空间,进行相似度比较,使用类似于triplet loss的思想:



2.5 Masking
受masked language modelling task的启发,作者额外增加一个MASK损失函数来预测randomly masked input tokens。在序列中随机选择输入词符的 15%, 对于选定的词符,在70%的情况下,将输入替换为特殊屏蔽词符 MASK 对应的向量,在 10% 情况下,用随机词符的向量替换输入,并在其余的 20% 情况下保留原始输入.。同样,使用类似于triplet loss的思想::



模型假设,为重建masked输入而增加一个训练目标应该起到正则化的作用,并且帮助模型从文本中学习更多的一般特征,而不仅仅是用于分类的识别特征。
2.6 Total loss

这个结构可以配置,可以随时关闭上述总和中的任何一种损失。该体系结构的设计方式可以打开或关闭多个组件,旨在处理意图和实体分类,但是如果只希望模型进行intent classification,则可以关闭Entity loss和Mask loss,而只专注于优化训练期间的Intent loss。
2.7 Batching
使用balanced batching策略来减轻类别不平衡,因为某些意图可能比其它意图更为频繁。 另外,还在整个训练期间增加批次大小,作为正则化的另一个来源。
3. 实验评估
3.1 联合训练的重要性
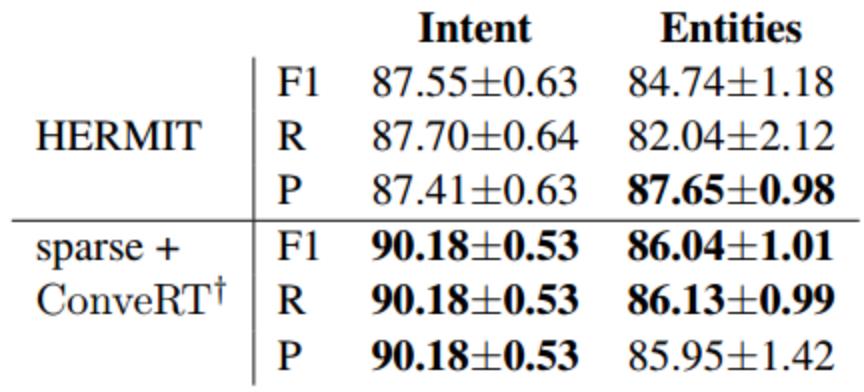
对比单任务学习性能:

可以看到相比之下,单任务的意图分类效果会有一点的提升(90.18->90.90),但是实体识别效果却降低了非常多(86.04->82.57)。这可能是由于特定意图与特定实体的存在之间的强相关性。 例如,几乎所有属于 play_game 意图的语句都有一个名为 game_name 的实体。 同样,实体 game_name 仅与意图 play_game 一起出现。 我们认为,这一结果进一步表明拥有像 DIET 这样的模块化和可配置架构的重要性,以便处理这两项任务之间的性能折中。
3.2 各模块的重要性
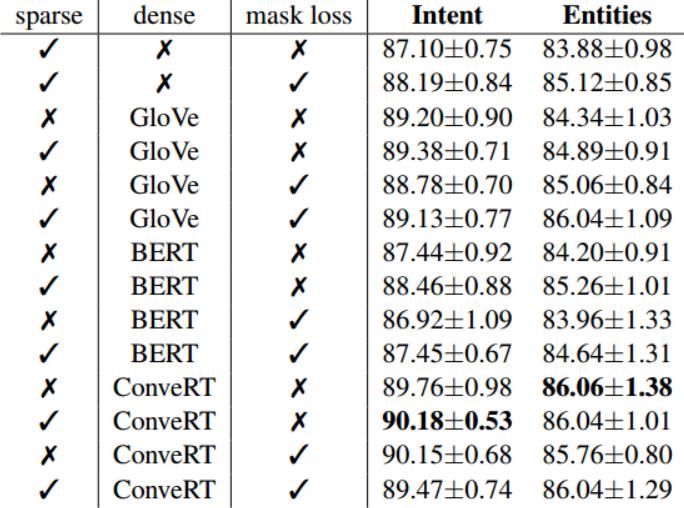
- 当使用sparse特征和mask损失,而没有任何预训练的embeddings时,DIET 的性能具有竞争力。 在目标和实体上增加mask损失都会使性能提高绝对值约 1%。但有了预训练的embeddings时,使用sparse特征,效果会更好,但如果加入mask损失,效果反而可能变差。所以,在rasa的DIETClassifier组件中,use_masked_language_model参数默认配置为 False
- 具有 GloVe emb的 DIET 也具有同等的竞争力,并且在与sparse特征和mask损失结合使用时,在意图和实体上都将得到进一步增强。
- 使用BERT emb作为dense特征的效果要比 GloVe 差。这应该是由于BERT 的预训练任务使得输出的向量不适应作为文本表示,因此在转移到对话任务之前需要微调。
- 由于ConveRT 专门针对会话数据进行微调,因此使用 ConveRT 嵌入的 DIET 的性能支持了这种假设。sparse特征 和 ConveRT 嵌入的结合在意图分类上获得了最佳的 F1 得分,并且在意图分类和实体识别方面都比现有最好结果高出 3% 左右。
3.3 与finetuning BERT 比较
将 可进行finetuning Bert的DIET 与 sparse特征+冻结预训练ConveRT Emb的 DIET进行比较:
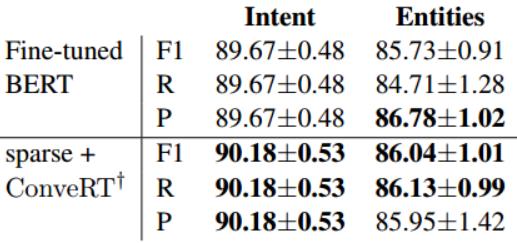
可以看到,sparse特征+冻结预训练ConveRT Emb的 DIET在实体识别上表现优于fine-tuned BERT的DIET,而在意图分类方面表现持平。 但要知道,在所有 10 个 NLU-Benchmark 数据集上**,finetuning的 DIET 中的 BERT 需要 60 个小时,而使用 ConveRT 嵌入和稀疏特征的 DIET 只需要 10 个小时。**
3.4 可迁移性
作者采用在 NLU-Benchmark 数据集上性能最佳的 DIET 模型配置,并在 ATIS 和 SNIPS 上对其进行评估。 下表中列出 ATIS 和 SNIPS 数据集上的意图分类准确性和命名实体识别 F1 得分。* 表示使用 BILOU 标记模式对数据进行标注。†表示未使用Mask Loss。
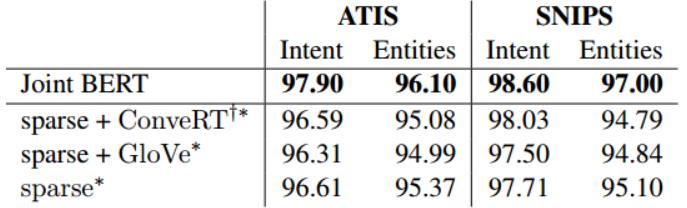
值得注意的是,DIET 仅使用稀疏特征而没有任何预训练的嵌入,即使这样其性能仅比 Joint BERT 模型低 1-2%之内。 利用 NLU-Benchmark 数据集上性能最佳模型的超参数,DIET 在 ATIS 和 SNIPS 上均获得与 Joint BERT 有竞争力的结果。
以上是关于RASADIET:Dual Intent and Entity Transformer的主要内容,如果未能解决你的问题,请参考以下文章