深度学习 Embedding层 两大作用 - 转载
Posted 琥珀彩
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度学习 Embedding层 两大作用 - 转载相关的知识,希望对你有一定的参考价值。
1. one-hot概念
首先,我们有一个one-hot编码的概念。假设,我们中文,一共只有10个字。那么我们用0-9就可以表示完。
比如,这十个字就是“我从哪里来,要到何处去”。其分别对应“0-9”,如下:
我 从 哪 里 来 要 到 何 处 去
0 1 2 3 4 5 6 7 8 9
那么,其实我们只用一个列表就能表示所有的对话
如:我 从 哪 里 来 要 到 何 处 去 ——>>>[0 1 2 3 4 5 6 7 8 9]
或:我 从 何 处 来 要 到 哪 里 去 ——>>>[0 1 7 8 4 5 6 2 3 9]
但是,我们看看one-hot编码方式(详见:OneHot编码知识点_tengyuan93的博客-CSDN博客_onehot编码),他把上面的编码方式弄成以下这样:
# 我从哪里来,要到何处去
[
[1 0 0 0 0 0 0 0 0 0]
[0 1 0 0 0 0 0 0 0 0]
[0 0 1 0 0 0 0 0 0 0]
[0 0 0 1 0 0 0 0 0 0]
[0 0 0 0 1 0 0 0 0 0]
[0 0 0 0 0 1 0 0 0 0]
[0 0 0 0 0 0 1 0 0 0]
[0 0 0 0 0 0 0 1 0 0]
[0 0 0 0 0 0 0 0 1 0]
[0 0 0 0 0 0 0 0 0 1]
]
# 我从何处来,要到哪里去
[
[1 0 0 0 0 0 0 0 0 0]
[0 1 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 1 0 0]
[0 0 0 0 0 0 0 0 1 0]
[0 0 0 0 1 0 0 0 0 0]
[0 0 0 0 0 1 0 0 0 0]
[0 0 0 0 0 0 1 0 0 0]
[0 0 1 0 0 0 0 0 0 0]
[0 0 0 1 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0 0 1]
]即:把每一个字都对应成一个10维(样本总数/字总数)的数组/列表,其中每一个字都用唯一对应的数组/列表对应,数组/列表的唯一性用1表示。如上,“我”表示成[1。。。。],“去”表示成[。。。。1],这样就把每一系列的文本整合成一个稀疏矩阵。
那问题来了,稀疏矩阵(二维)和列表(一维)相比,有什么优势?
很明显,计算简单嘛,稀疏矩阵做矩阵计算的时候,只需要把1对应位置的数相乘求和就行,也许你心算都能算出来;而一维列表,你能很快算出来?何况这个列表还是一行,如果是100行、1000行和或1000列呢?
所以,one-hot编码的优势就体现出来了,计算方便快捷、表达能力强。
然而,缺点也随着来了。
比如:中文大大小小简体繁体常用不常用有十几万,然后一篇文章100W字,你要表示成100W X 10W的矩阵???
这是它最明显的缺点。过于稀疏时,过度占用资源。
比如:其实我们这篇文章,虽然100W字,但是其实我们整合起来,有99W字是重复的,只有1W字是完全不重复的。那我们用100W X 10W的岂不是白白浪费了99W X 10W的矩阵存储空间。那怎么办???
这时,Embedding层横空出世。
2.embedding层
插张图片,
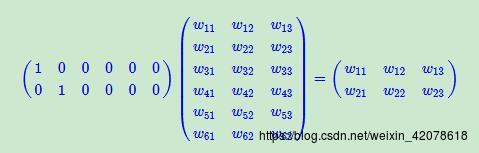
链接:https://spaces.ac.cn/archives/4122
假设:我们有一个2 x 6的矩阵,然后乘上一个6 x 3的矩阵后,变成了一个2 x 3的矩阵。
先不管它什么意思,这个过程,我们把一个12个元素的矩阵变成6个元素的矩阵,直观上,大小是不是缩小了一半?
embedding层,在某种程度上,就是用来降维的,降维的原理就是矩阵乘法。在卷积网络中,可以理解为特殊全连接层操作,跟1x1卷积核异曲同工!
复习一下,矩阵乘法需要满足一个条件。A X B时,B的行数必须等于A的列数。得出的结果为A的行数 X B的列数的一个矩阵
也就是说,假如我们有一个100W X10W的矩阵,用它乘上一个10W X 20的矩阵,我们可以把它降到100W X 20,瞬间量级降了。。。10W/20=5000倍!!!
这就是嵌入层的一个作用 —— 降维。
然后中间那个10W X 20的矩阵,可以理解为查询表,也可以理解为映射表,也可以理解为过度表。
--------此外--------
接着,既然可以降维,当然也可以升维。为什么要升维?这也是很神奇的。咱们再举一个例子:

这张图,我要你在10米开外找出五处不同!What?烦请出题者走近两步,我先把我的刀拿出来,您再说一遍题目我没听清。
当然,目测这是不可能完成的。但是我让你在一米外,也许你一瞬间就发现衣服上有个心是不同的,然后再走近半米,你又发现左上角和右上角也是不同的。再走近20厘米,又发现耳朵也不同,最后,在距离屏幕10厘米的地方,终于发现第五个不同的地方在耳朵下面一点的云。
但是,其实无限靠近并不代表认知度就高了。比如,要求你只能距离屏幕1厘米远的地方找,找出五处不同。。。出题人你是不是脑袋被门挤了。。。
由此可见,距离的远近会影响我们的观察效果。同理也是一样的,低维的数据可能包含的特征是非常笼统的,我们需要不停地拉近拉远来改变我们的感受野,让我们对这幅图有不同的观察点,找出我们要的茬。
embedding的又一个作用体现了。对低维的数据进行升维时,可能把一些其他特征给放大了,或者把笼统的特征给分开了。同时,这个embedding是一直在学习在优化的,就使得整个拉近拉远的过程慢慢形成一个良好的观察点。比如:我来回靠近和远离屏幕,发现45厘米是最佳观测点,这个距离能10秒就把5个不同点找出来了。
回想一下为什么CNN层数越深准确率越高,卷积层卷了又卷,池化层池了又升,升了又降,全连接层连了又连。因为我们也不知道它什么时候突然就学到了某个有用特征。但是不管怎样,学习都是好事,所以让机器多卷一卷,多连一连,反正错了多少我会用交叉熵告诉你,怎么做才是对的我会用梯度下降算法告诉你,只要给你时间,你迟早会学懂。因此,理论上,只要层数深,只要参数足够,NN能拟合任何特征。
总之,它类似于虚拟出一个关系对当前数据进行映射。这个东西也许一言难尽吧,但是目前各位只需要知道它有这些功能的就行了。
想具体理解其作用,建议大家去探究探究卷积神经网络的各种中间过程,以及反向传播理论。到时候大家再来深入理解嵌入层时,那就一通百通了。
以上是关于深度学习 Embedding层 两大作用 - 转载的主要内容,如果未能解决你的问题,请参考以下文章