云计算之路-阿里云上:排查“黑色30秒”问题-为什么请求会排队
Posted liuqiyun
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了云计算之路-阿里云上:排查“黑色30秒”问题-为什么请求会排队相关的知识,希望对你有一定的参考价值。
http://www.cnblogs.com/cmt/p/3682642.html
针对Web服务器“黑色30秒”问题(详见云计算之路-阿里云上:Web服务器遭遇奇怪的“黑色30秒”问题),经过分析,我们准备从这个地方下手——为什么会出现ASP.NETRequest Queued大于0的情况(为什么请求会排队)?
首先, 通过Windows性能监视器去观察,看能不能找到这样的线索——在什么条件下会触发请求排队?
我们在性能监视器中增加了1个监视指标——HTTP Service Request QueuesArrival Rate
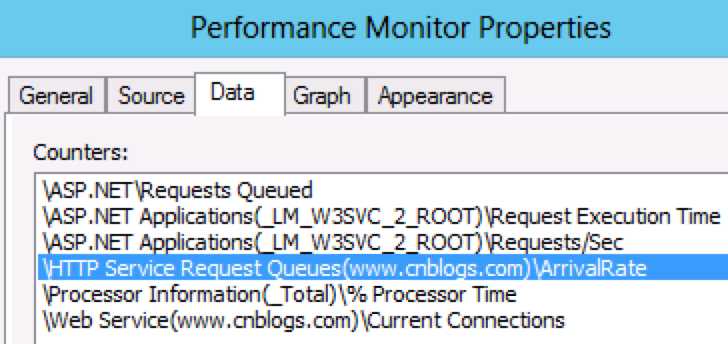
Arrival Rate: Rate at which requests are arriving in the queue
这是一个针对IIS的底层HTTP.SYS的监视指标,从我们的理解,认为它最直接地反映了到达IIS的当前要处理的并发请求。
启用这个Arrival Rate监视指标后,我们观察到了1次请求排队的情况(非“黑色30秒”故障场景)。
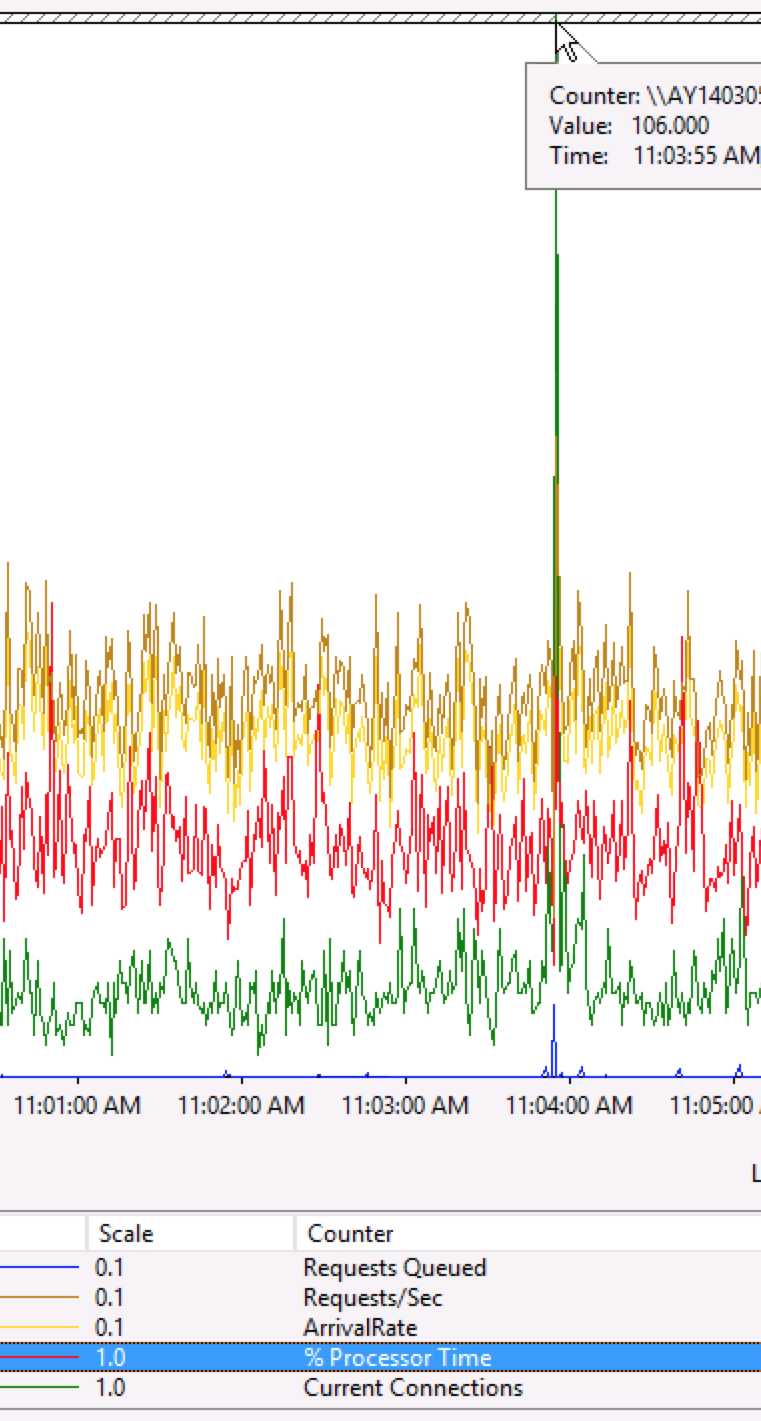
上图中跳起的蓝色就表现出现了请求排队。
我们来逐个指标看一下。
1. HTTP Service Request QueuesArrival Rate(到达IIS底层的请求)
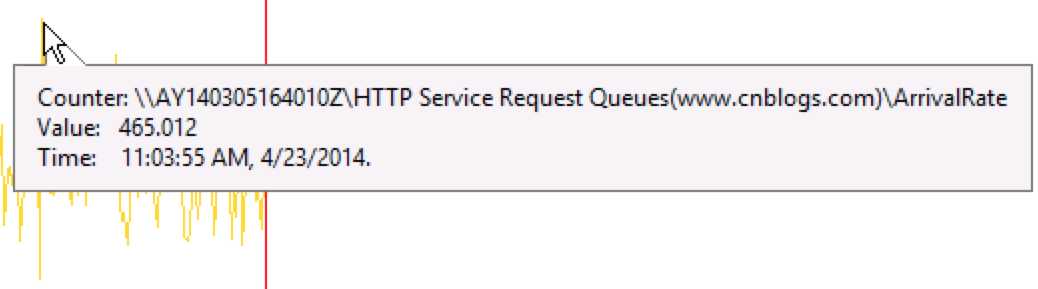
当时HTTP.SYS收到了465个并发请求。
2. Qequests/Sec(QPS,ASP.NET每秒处理的请求数)
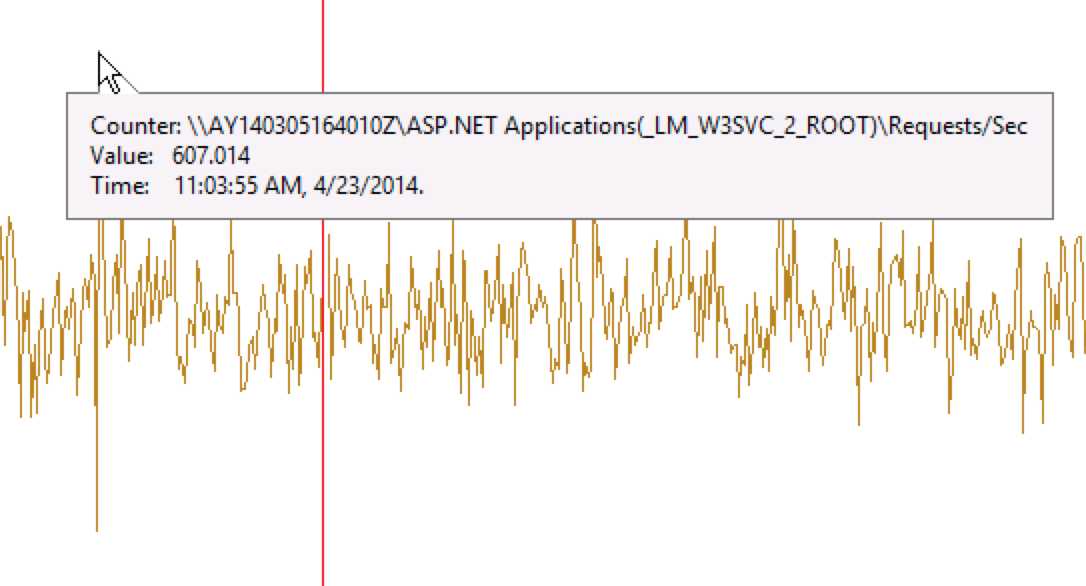
当时ASP.NET的QPS是607。
3. Requests Queued(排队的请求数)
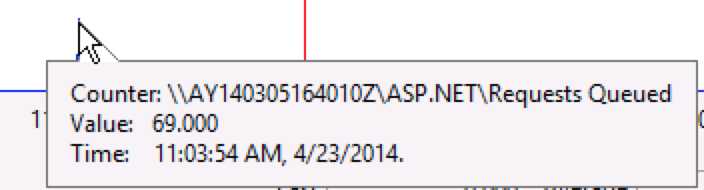
【注意】出现请求排队的时间点是11:03:54,而前2个指标高上去的时间点在11:03:55。
【重要线索】由此,我们可以得出这样的线索:是先出现请求排队(Requests Queued),然后才出现Arrival Rate与QPS上升。是请求排队引起Arrival Rate与QPS上升,而不是Arrival Rate与QPS上升引起请求排队。
接下来通过其他指标验证这个想法。
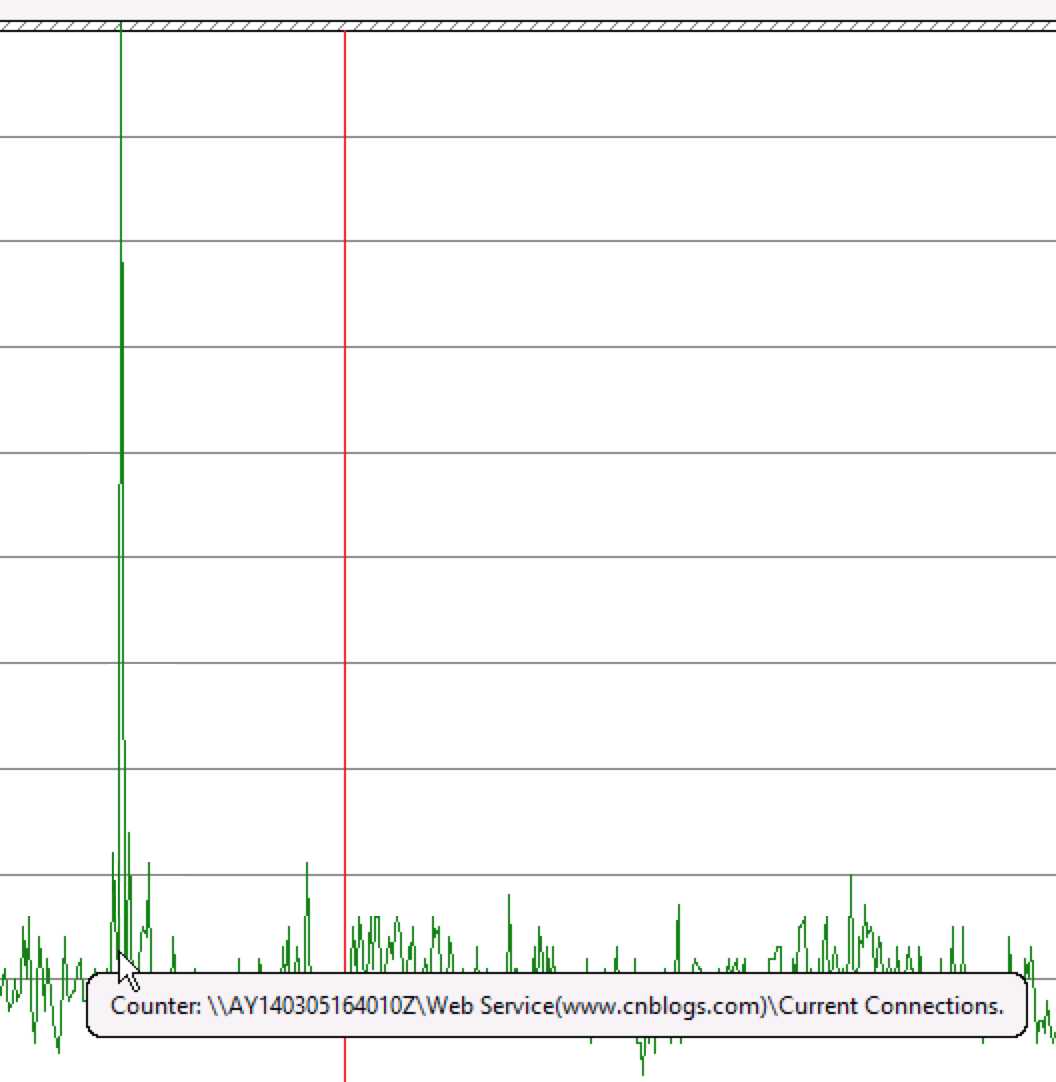
4. Current Connections
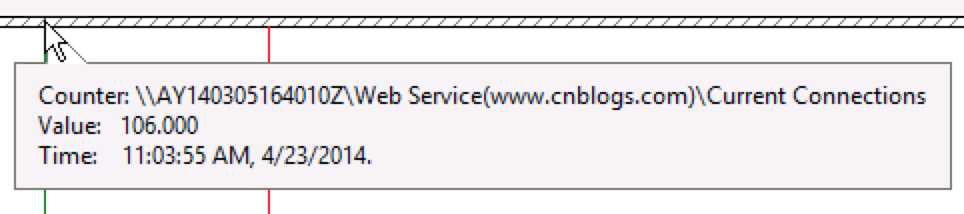
IIS当前连接数高上去也在出现请求排队之后。(成功验证1)
5. CPU
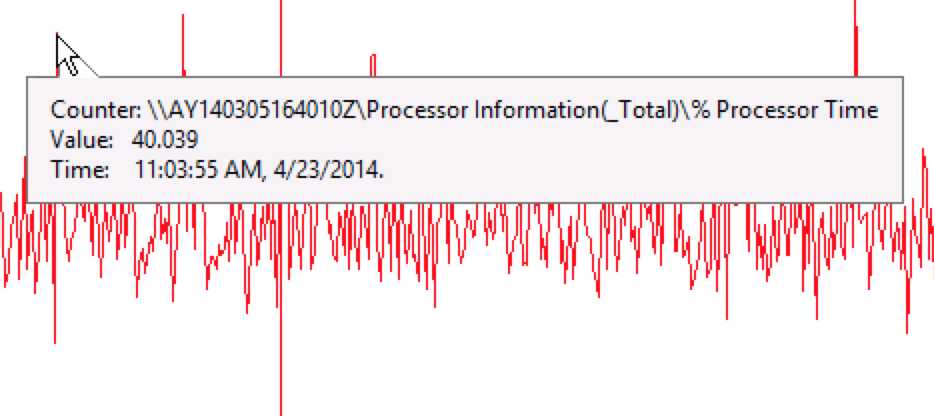
CPU占用也是在出现请求排队之后才高上去的。(成功验证2)
【分析结论】请求排队才是问题的原因,而其他表现只是请求排队后的结果表现。
那在11:03:54,请求排队时,其他指标又是什么情况呢?
1. ArrivalRate只有218
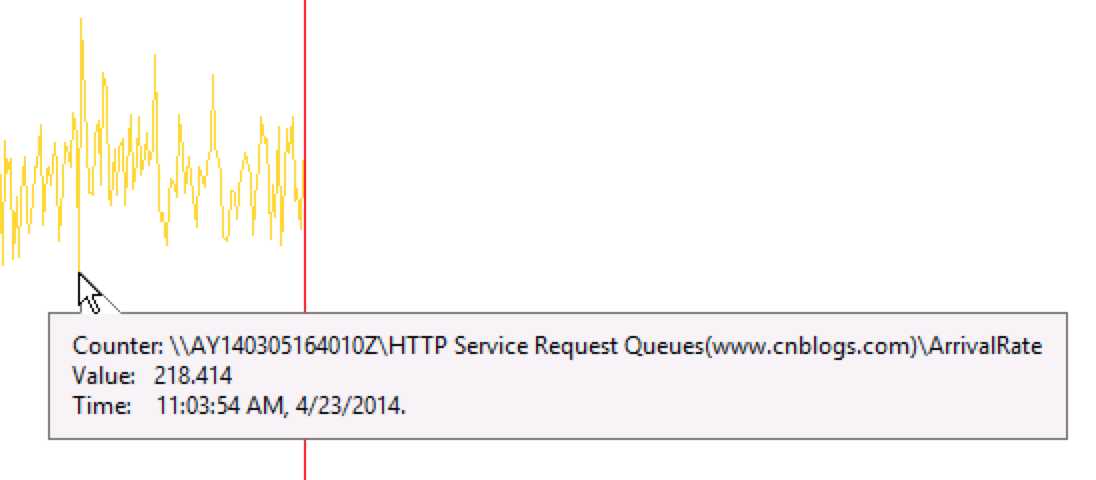
2. QPS只有151

3. Current Connections在15以下(具体数值在性能监视器上显示不出来)
4. CPU占用只有10%
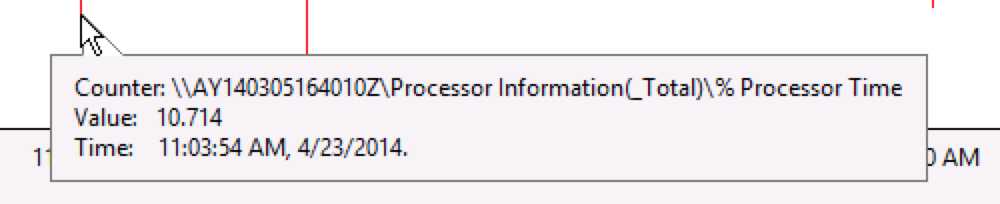
太奇怪了!在请求排队时,其他指标都处于低点——比正常情况更低的点。
更奇怪的是到达IIS的请求比平时变少了,请求反而排队了。
【猜想】
从这个监视到的表现看,我们唯一能解释得通的是:11:03:54,Web服务器似乎在打瞌睡,处理能力全面下降;然后,11:03:55,Web服务器醒了过来,处理能力全面恢复,这时不仅要处理当前的请求,还要处理之前排队的请求,一下子负载就高了上去。
难道谁给Web服务器下了药?如果用的是物理机,我们真的会怀疑是谁下的药?但现在用的是虚拟机,在“被下药”与“虚拟机问题”之间,哪个更值得怀疑呢?。。。这个问题只能留给阿里云的同学,我们再怎么怀疑,也只能怀疑而已,无法在虚拟机层面进行验证。
【进一步的线索】
在写这篇博客的期间,1台服务器正好发生了“黑色30秒”,看看性能监视器中的相关表现:
1. Arrival Rate与Requests Queued

2. 加上Current Connections
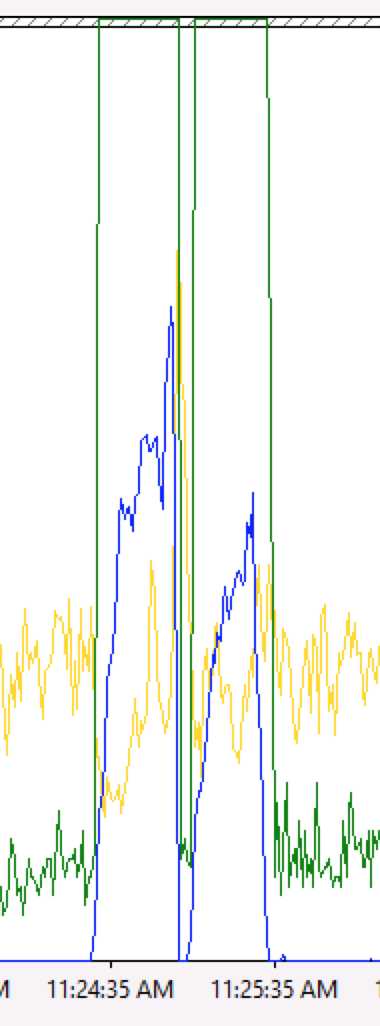
3. 加上CPU

4. 加上Request Execution Time
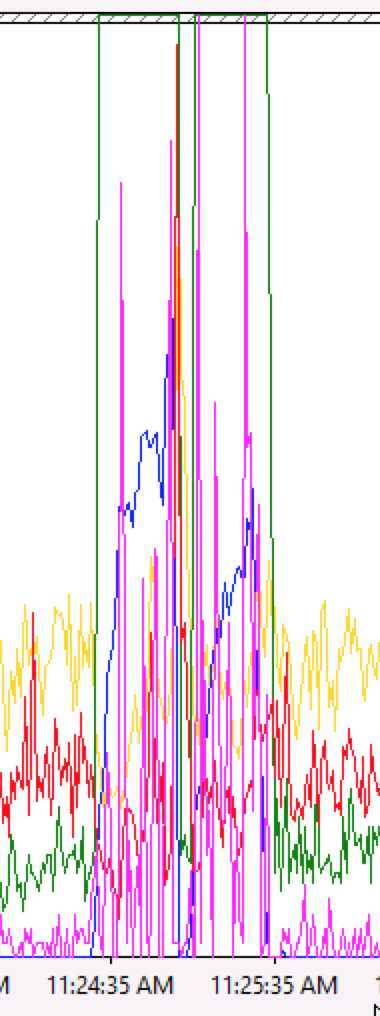
而且这次接连来了2个“黑色30秒”。
【小结】
虚拟的世界很精彩,虚拟的世界也很无奈。从应用、从Windows的角度,我们真的不知从何处理下手,我们能做的只是找问题的线索。问题的解决可能真的需要阿里云同学们的努力!
以上是关于云计算之路-阿里云上:排查“黑色30秒”问题-为什么请求会排队的主要内容,如果未能解决你的问题,请参考以下文章
云计算之路-阿里云上:服务器CPU 100%问题是memcached连接数限制引起的
云计算之路-阿里云上-容器难容:自建docker swarm集群遭遇无法解决的问题