Elasticsearch 7.X 拼音分词器 pinyin 使用
Posted 小毕超
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Elasticsearch 7.X 拼音分词器 pinyin 使用相关的知识,希望对你有一定的参考价值。
一、pinyin 分词器
前面我们讲到了ik分词器的使用,以及部分源码和自定义词库的讲解,本篇文章我们讲解下拼音分词器 pinyin。
上篇文章地址:https://blog.csdn.net/qq_43692950/article/details/122276392
我们在百度或其他搜索引擎搜索时,可以发现尽管我搜索的时拼音但也可以搜到我们想要的文字:

今天我们学习的pinyin分词器就可以实现这一效果。
其中pinyin分词器两种分词规则:
pinyin:就是普通的把汉字转换成拼音;pinyin_first_letter:提取汉字的拼音首字母
二、pinyin分词器的编译和安装
elasticsearch-analysis-pinyin分词器目前没有下载即可使用的安装包,需要自己下载源码进行编译。
首先下载elasticsearch-analysis-pinyin 源码:
https://github.com/medcl/elasticsearch-analysis-pinyin
下载完成后我们需要修改pom文件,将es的版本,修改为和自己当前es相同的版本,我使用的7.14.0的所以修改为7.14.0:

下面使用maven进行打包,进入该目录下:
mvn package

打包成功后进入\\target\\releases下便是打包好的es插件,对该文件进行解压
然后在es的安装目录下plugins目录下新建pinyin目录,并将解压后的文件复制到该目录下:

下面重新启动es。
三、分词测试
向es服务器发送GET请求:
http://127.0.0.1:9200/_analyze
请求体为:
"text": "小毕超",
"analyzer":"pinyin"

下面进行数据查询的测试:
创建索引指定为pinyin分词器:
发送PUT请求:
http://127.0.0.1:9200/user4
"settings": ,
"mappings":
"properties":
"name":
"type": "text",
"index": true,
"analyzer": "pinyin"
,
"sex":
"type": "text",
"index": true,
"analyzer": "ik_smart"
,
"age":
"type": "long",
"index": false
下面添加两条数据:
向es服务器发送POST请求:
http://127.0.0.1:9200/user4/_doc
请求体为:
"name":"张三",
"age":18,
"sex":"男"
然后再添加一个:
"name":"zhangsan",
"age":18,
"sex":"男"
下面使用pinyin分词查询:
向es服务器发送GET请求:查询张三
http://127.0.0.1:9200/user4/_search
"query":
"match":
"name":
"analyzer":"pinyin",
"query":"张三"
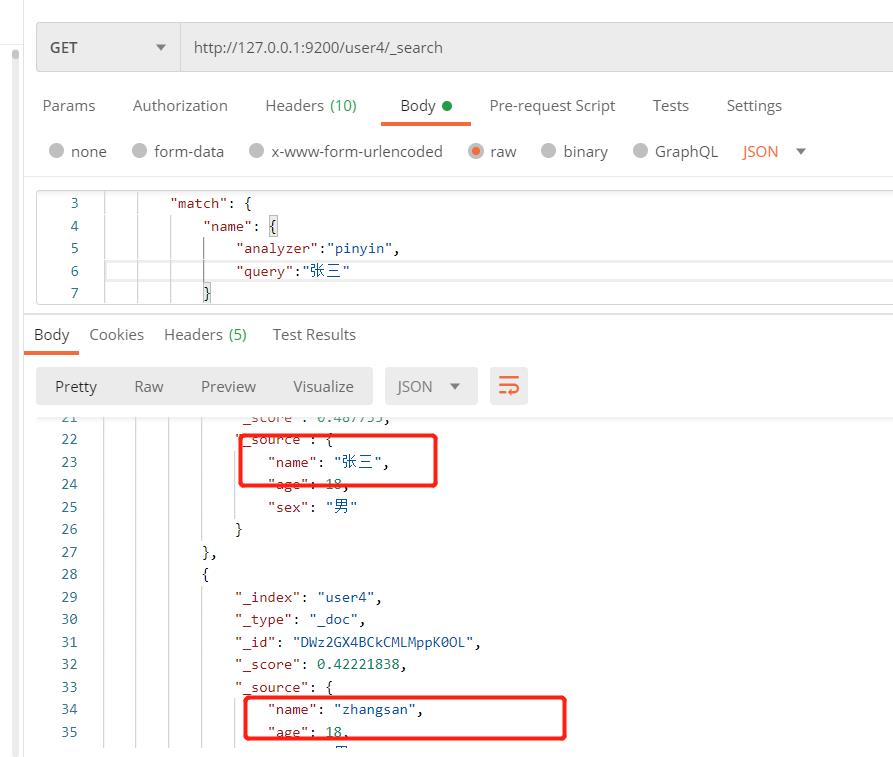
向es服务器发送GET请求:查询zhangsan
"query":
"match":
"name":
"analyzer":"pinyin",
"query":"zhangsan"


喜欢的小伙伴可以关注我的个人微信公众号,获取更多学习资料!
以上是关于Elasticsearch 7.X 拼音分词器 pinyin 使用的主要内容,如果未能解决你的问题,请参考以下文章
如何在Elasticsearch中安装中文分词器(IK)和拼音分词器?
Elasticsearch 分布式搜索引擎 -- elasticsearch-analysis-pinyin 拼音分词器的安装和介绍