大数据系列14:dask使用简介
Posted IE06
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据系列14:dask使用简介相关的知识,希望对你有一定的参考价值。
anaconda装完了之后会自带dask。中文版文档见https://www.heywhale.com/mw/project/610c8f40fe727700176ae461
Dask 带有四个可用的调度程序:
· threaded:由线程池支持的调度程序
· processes:由进程池支持的调度程序
· single-threaded(又名" sync"):同步调度程序,用于调试
· distributed:用于在多台计算机上执行图形的分布式调度程序,推荐用distributed,我们后面仅用这个。
1. 基础环境配置
- 集群上配置dask。anaconda中自带dask,如果没有的话,pip install一下。注意python的配置需要一致,可以用docker镜像来做,以保持环境一致。
- 在任意一台机器上安装anaconda最新版,然后安装dask-labextension。可以pip install安装,也可以在下面的页面搜索进行安装,然后执行jupyter lab build。
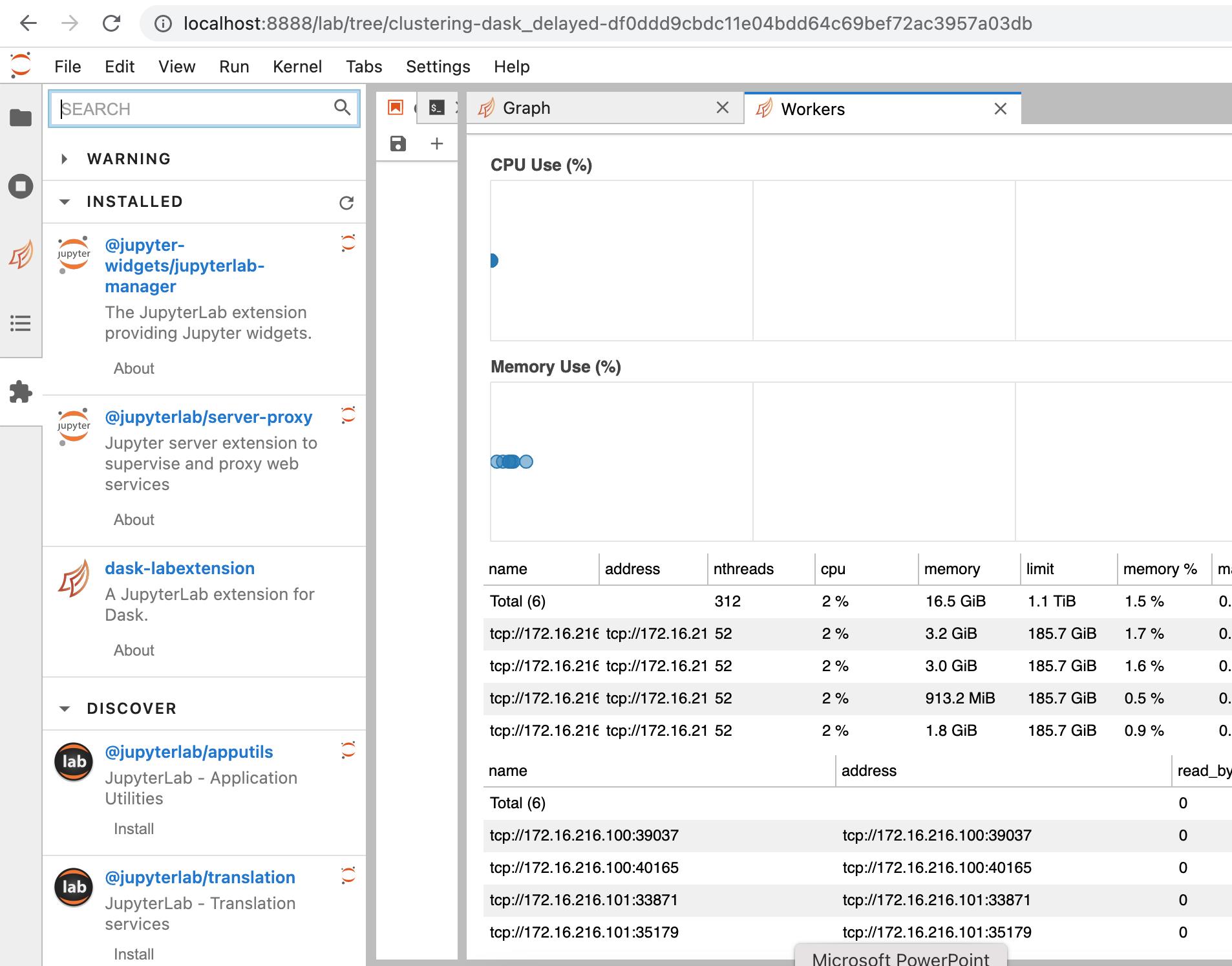
2. 分布式计算环境dask.distributed
2.1 本机上的创建方式
from dask.distributed import Client,LocalCluster
# 最简单的方式,默认按照cpu核数创建worker数量
c = Client()
# 也可以指定参数
c = Client(LocalCluster(n_workers=3, threads_per_worker=7, processes=True))
2.2 分布式创建方式
如果要用分布式,在主节点上执行dask-scheduler,会得到类似如下的结果:
$ dask-scheduler # 创建scheduler
distributed.scheduler - INFO - -----------------------------------------------
distributed.scheduler - INFO - Clear task state
distributed.scheduler - INFO - Scheduler at: tcp://192.168.10.100:8786
distributed.scheduler - INFO - bokeh at: :8787
distributed.scheduler - INFO - Local Directory: /tmp/scheduler-wydqn90b
distributed.scheduler - INFO - -----------------------------------------------
distributed.scheduler - INFO - Receive client connection: Client-237debe6-cd07-11e8-9edd-a0c589feaf42
然后在工作节点上执行dask-worker tcp://192.168.10.100:8786
然后在任意一台机器上连接上主节点:
client = Client('tcp://localhost:8786')
3. 数据类型
主要包括:dask.array, dask.dataframes, dask.bag
3.1 Array
除了linalg库,numpy系列基本都有实现。
import dask.array as da
x = da.random.uniform(low=0, high=10, size=(10000, 10000), # normal numpy code
chunks=(1000, 1000)) # break into chunks of size 1000x1000
y = x + x.T - x.mean(axis=0) # Use normal syntax for high level algorithms
3.2 DataFrames
类似pandas:
import dask.dataframe as dd
df = dd.read_csv('2018-*-*.csv', parse_dates='timestamp', # normal Pandas code
blocksize=64000000) # break text into 64MB chunks
s = df.groupby('name').balance.mean() # Use normal syntax for high level algorithms
3.3 Bags / lists
Daskbag可以从文件中逐行读取数据,然后用.take方法输出指定行数的数据。
Dask Bag实现了例如map,filter,fold,和groupby等操作。它使用Python迭代器并行地完成这个任务,占用的内存很小。它类似于PyToolz的并行版本或PySpark RDD的Python版本。下面是个例子:
import dask.bag as db
b = db.read_text('*.json').map(json.loads)
total = (b.filter(lambda d: d['name'] == 'Alice')
.map(lambda d: d['balance'])
.sum())
filtered.compute()
4. 计算过程
4.1 future系列
和async中的future类似,有下面几个重要的方法:
client.scatter(list)
client.map(function, list of parameters) #starmap类似
client.submit(function, parameter)
client.gather(res)
res.result()
一旦调用submit方法,会立即开始在后台异步执行。通过gather方法或者result函数可以获得结果。
4.2 delay系列
和yield类似,需要先from dask import delayed。有两种执行方式:
- 使用@delayed装饰符
- 使用delayed(function)
from dask import delayed
def inc(x):
return x + 1
def double(x):
return x * 2
def add(x, y):
return x + y
data = [1, 2, 3, 4, 5]
output = []
for x in data:
a = delayed(inc)(x)
b = delayed(double)(x)
c = delayed(add)(a, b)
output.append(c)
total = dask.delayed(sum)(output)
total.compute()
4.3 一些对比结果
对一个如下的任务,overhead非常大,我们来评测一下性能
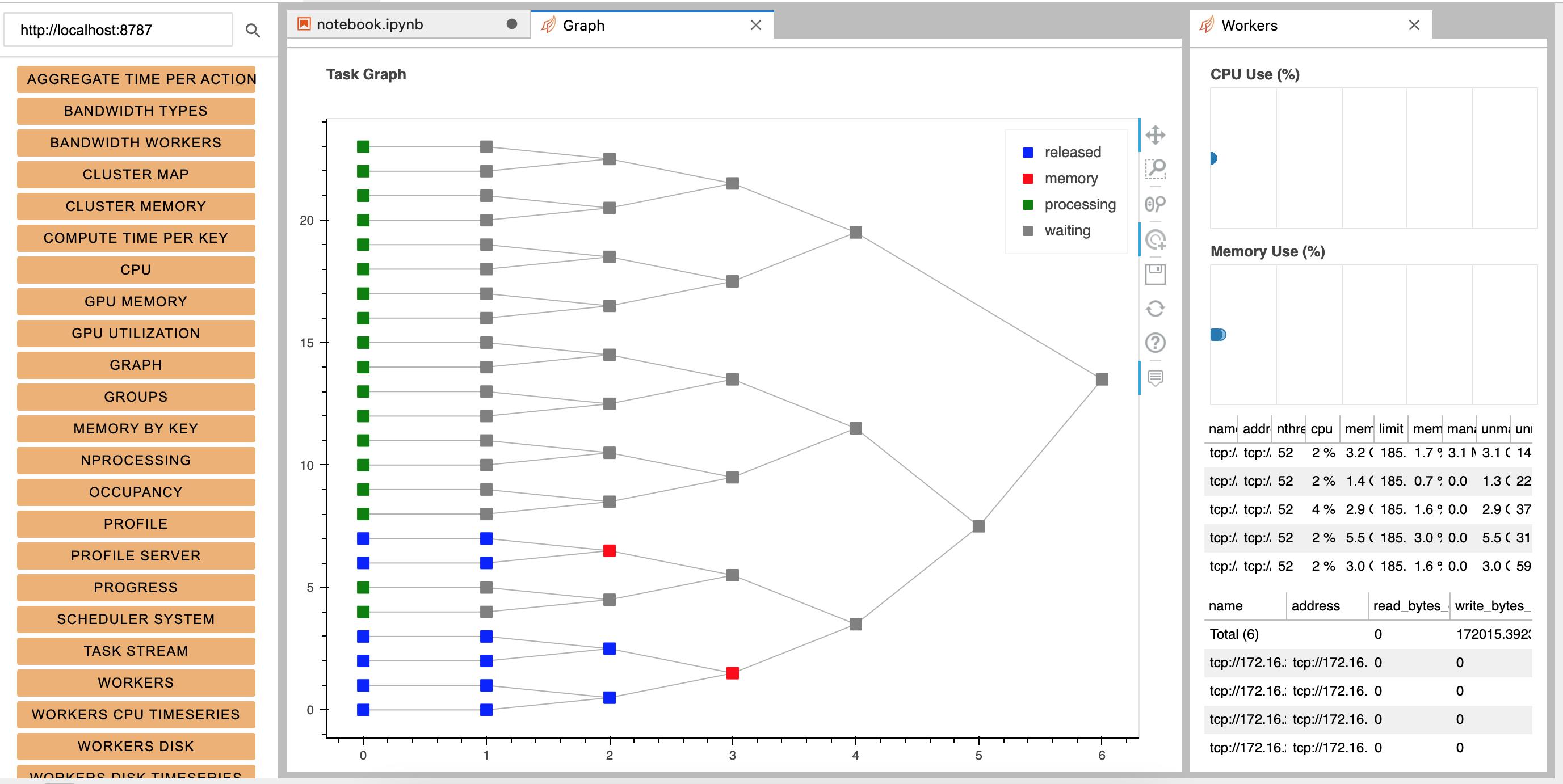
使用local的方式,无论那种配置,基本都是在8min30s左右。
使用两台机器的集群,使用dask.delayed,耗时6min左右。
使用三台机器的集群,使用dask.delayed,耗时5min20s左右。
其中拉取数据部分,无论是单机跑还是分布式跑,都是用时3min30s左右。去除这部分后,剩下的计算时间在3、2、1台机器下的耗时分别是:1.83、2.5、5min左右。
另外三台机器下还测试了dask.future,耗时6min左右;此外还测试了单机下使用多进程的方式,耗时443s(8进程)和482s(24进程)。
5. 状态监控
5.1 进度查询
首先是进度条,单机版本可以用progressbar函数,分布式版本可以用progress函数。
下面是自定义查询进度的方法:
① 首先要获得任务数量。
from dask.base import collections_to_dsk
dsks = dict(collections_to_dsk([delayed_tasks]))
taskNum = len(dsks.keys())
② 获取运行完的任务
from dask.distributed import get_task_stream
res = client.get_task_stream()
num = 0
for ri in res:
if ri['status']=='OK':
num+=1
5.2 内存等性能监控
首先,可以用MemorySampler来监控内存,示例如下:
from distributed.diagnostics import MemorySampler
ms = MemorySampler()
with ms.sample("test"):
dask.compute(total)
ms.plot(align=True)
print(ms.samples['test'])
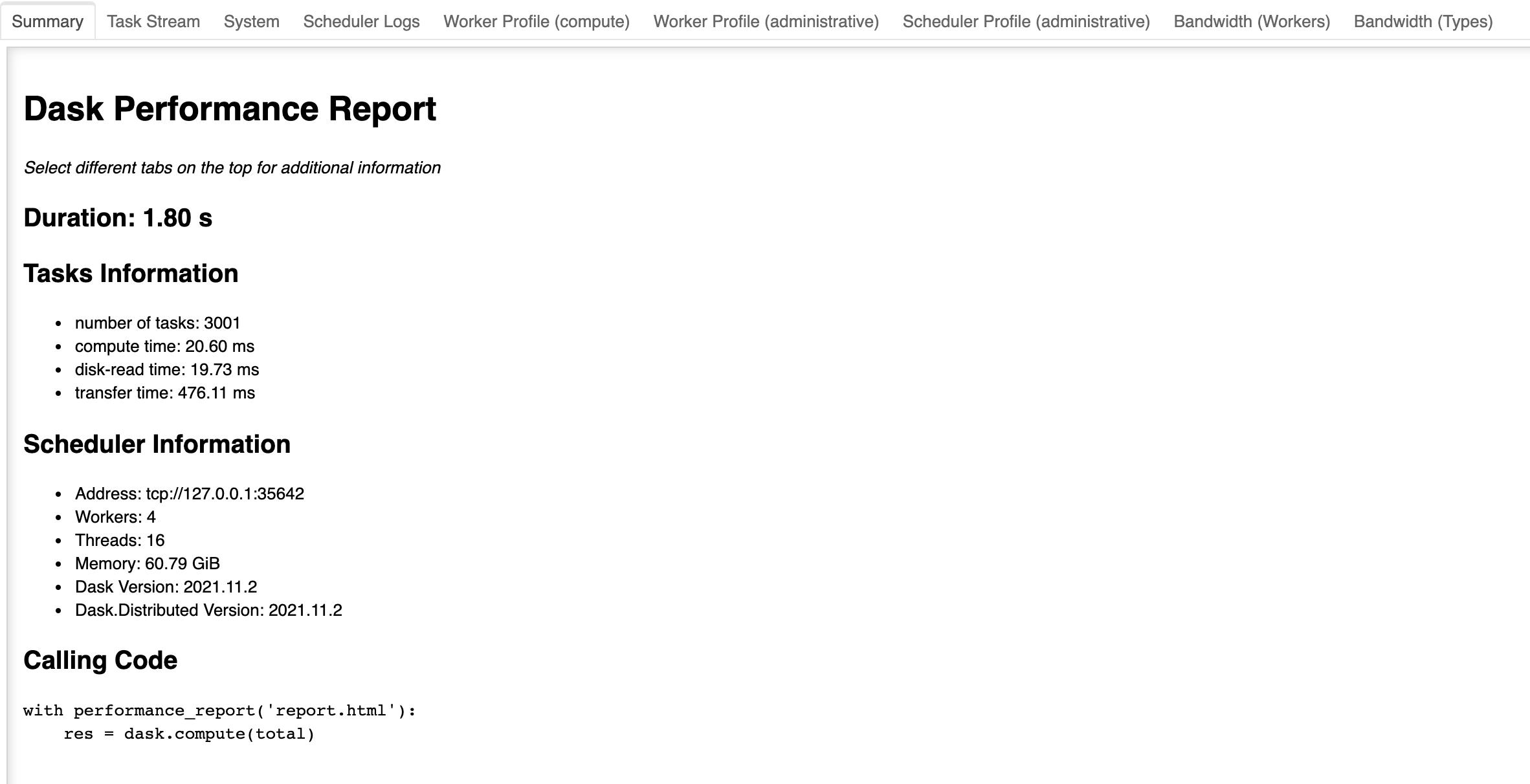
还有一种方式,是performance_report,示例如下:
with performance_report('report.html'):
groups = dask.compute(total)
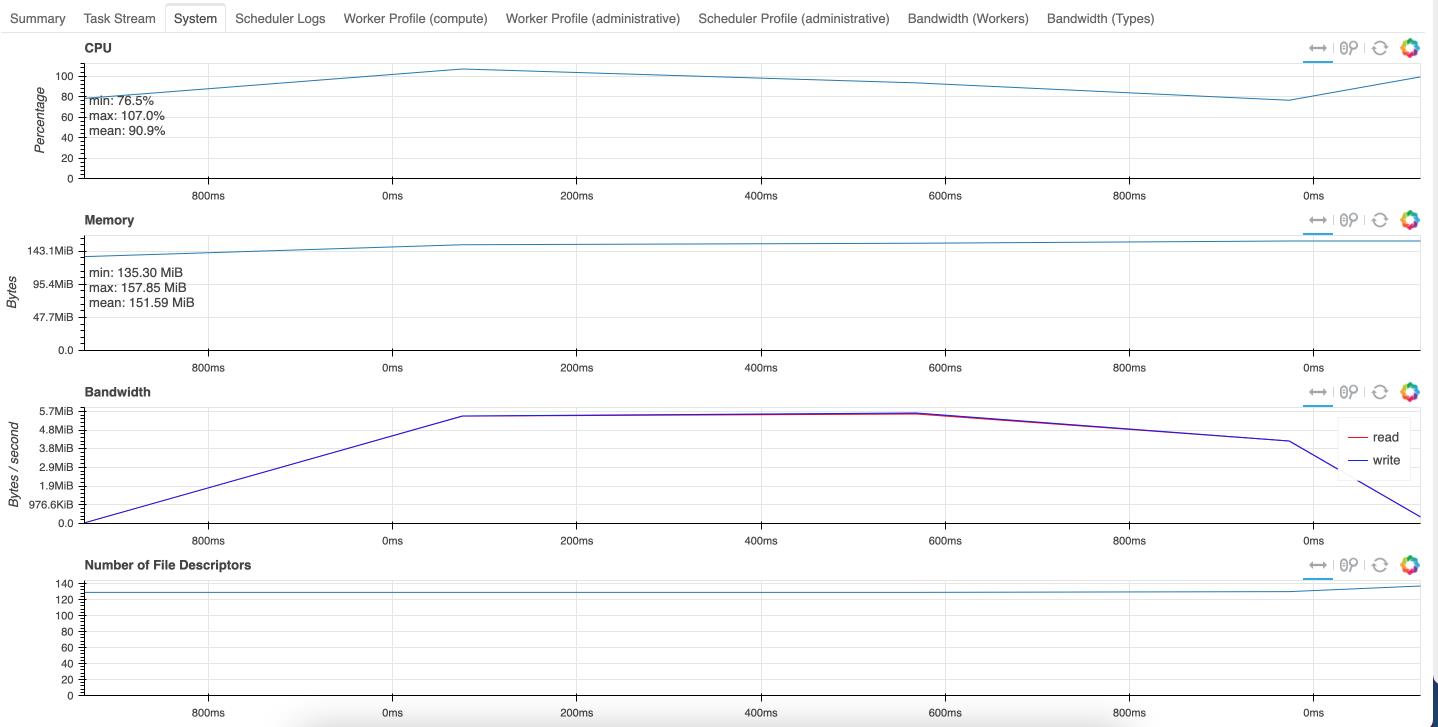
会在文件下下保存html文件,里面有cpu、内存、消耗时间等信息
以上是关于大数据系列14:dask使用简介的主要内容,如果未能解决你的问题,请参考以下文章
除了 pandas 和 dask 之外,还都有哪些更快的读取大数据集和应用行明智操作的方法?