Annual salary30W+Java开发工程师——3.数组
Posted bit_zhy
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Annual salary30W+Java开发工程师——3.数组相关的知识,希望对你有一定的参考价值。
文章目录
1.初识数组和数组的定义
(1)初识数组
数组就是储存一组相同数据类型的集合
(2)数组的定义
1.静态初始化定义方法
这个方法和c语言几乎是一样的,格式为:int[] 数组名 = 1,2,3,4,5;
2.动态初始化定义方法
格式:int[] 数组名 = new int[]1,2,3,4,5;
3.不初始化定义方法
这个方法是唯一一种可以在[]中加数字的,格式为:
int[] arr = new int[数组长度] ;
2.使用数组
(1)下标的访问
在访问数组某一个元素时是以arr[下标]的方式来访问,值得注意的是下标是从零开始的,因此我们要留心不要越界访问,否则会抛出数组越界的异常
在我们发现这种异常时,我们要锁定的是访问数组元素的代码位置来找寻问题。
(2)获取数组长度
在Java中,获取数组长度可以使用方法:数组名.length,来直接获取数组的长度,也就是数组中元素的个数。
(3)遍历数组
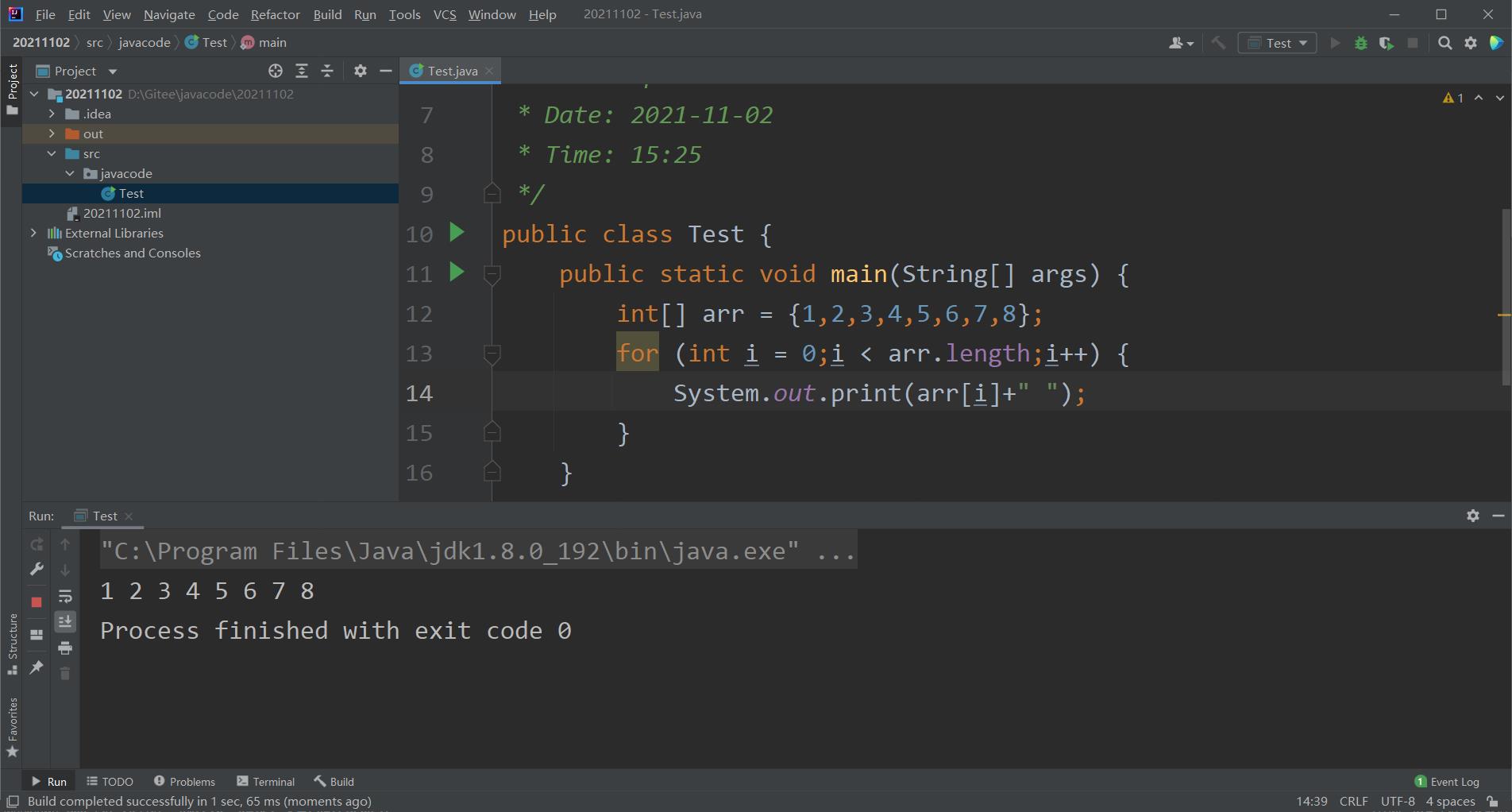
1.利用for i循环遍历数组
这种方法我们都接触过并且很熟练,在这里我就不过多赘述了,上传一段代码给大家。
2.利用for each循环遍历数组
for each循环是我们新接触的一种循环,我们可以将其理解为加强for循环,具体可以实现的是,不利用数组的下标,便可以访问到数组的每个元素,具体使用的方法格式为:
for(数组的元素的数据类型 接受的变量名 :数组名) 代码段 ;
下面我利用for each循环打印一遍数组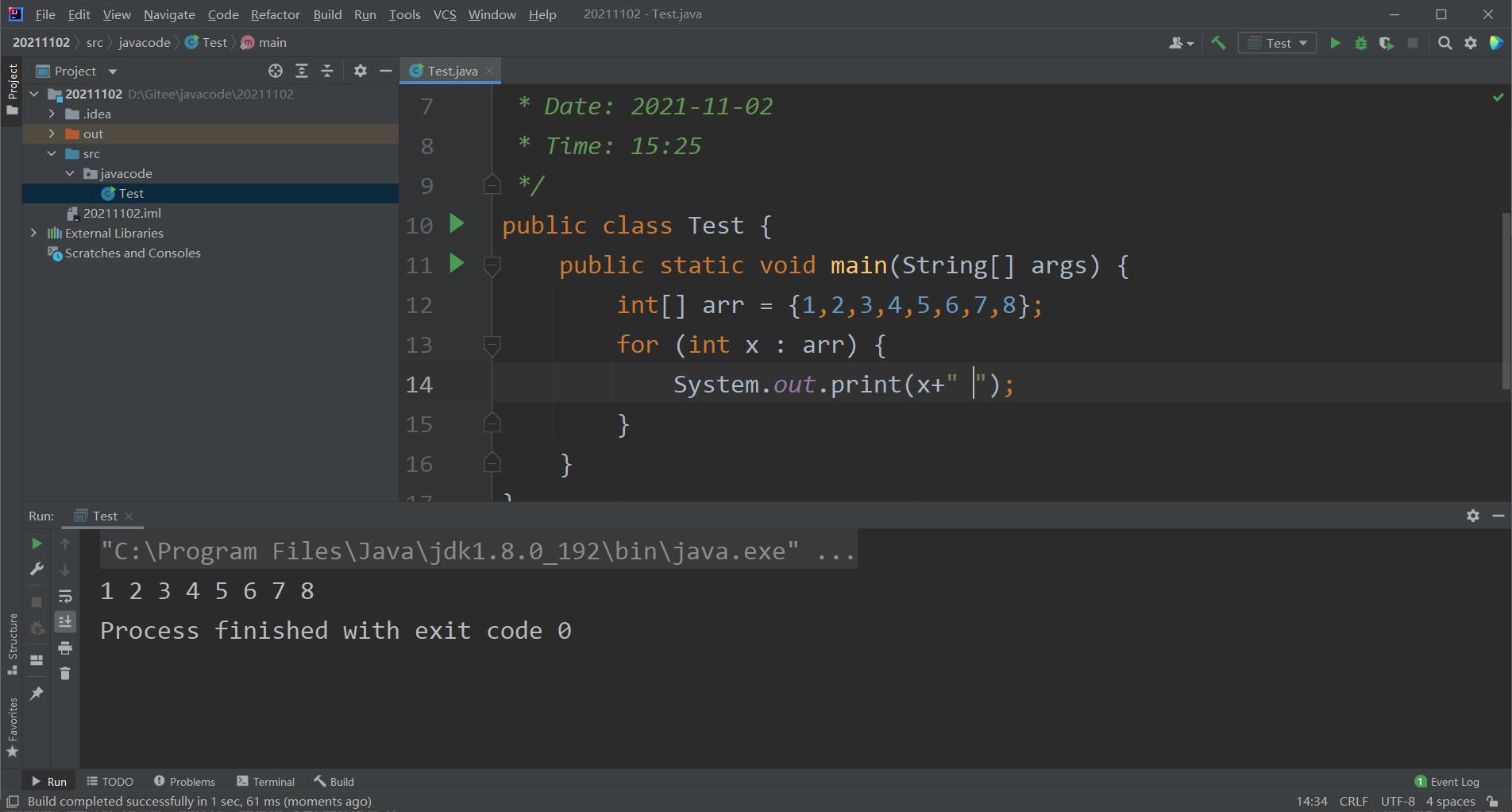
在我们不需要使用数组下标时,我们可以选择for each循环,是否利用下标便是这两种循环的最大区别。
3.利用数组的操作类
在打印数组时,我们可以利用操作类Arrays.toString(数组名),来直接将数组打印出来,不过我们要记得引头文件:import java.util.Arrays;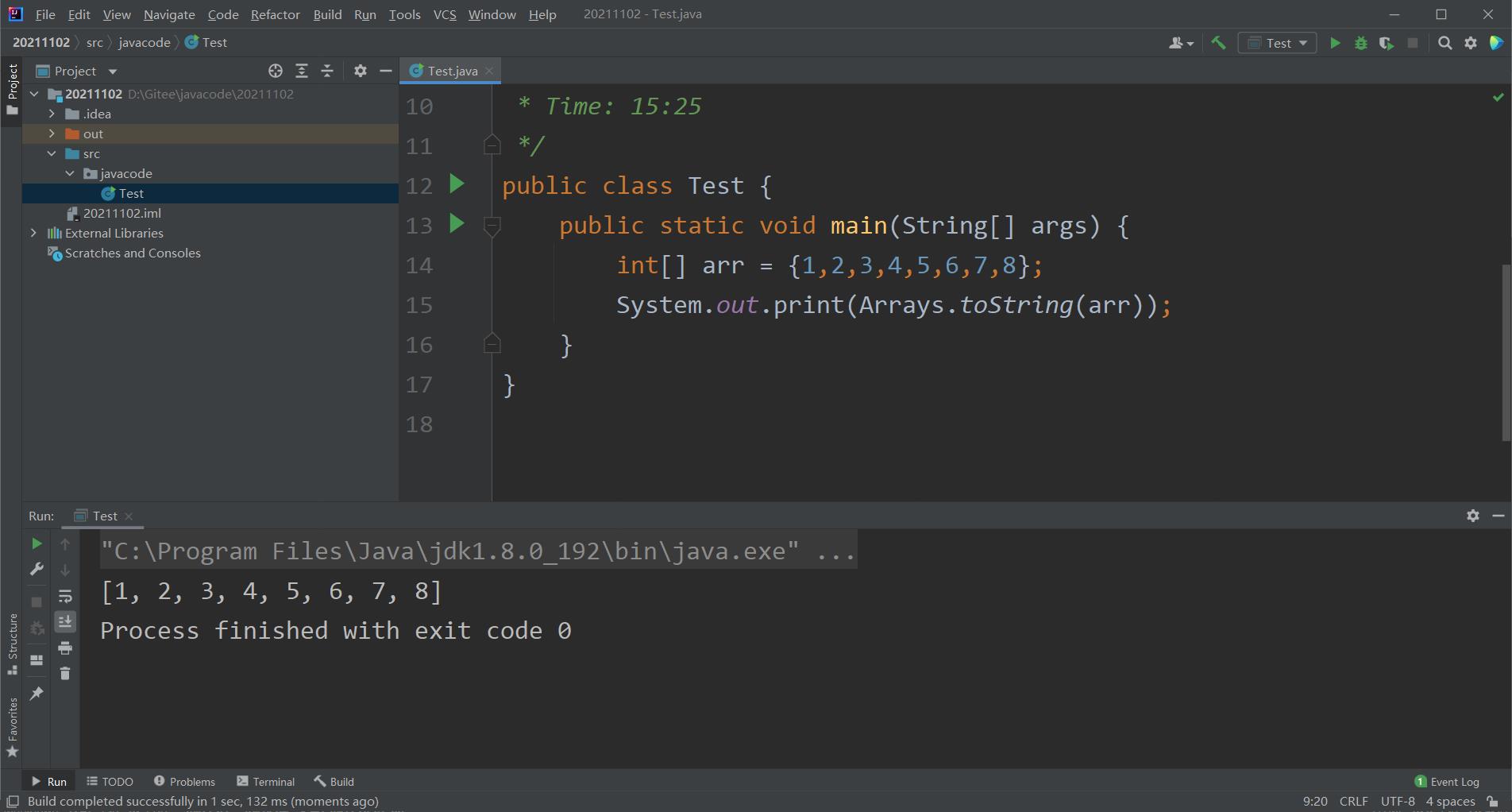
这个方法本质上是将数组的内容转换成字符串形式,如下图解释。
3.数组作为方法的参数(引用类型)
数组作为方法的参数本质上可以理解为一种传值调用,只不过传的值是一个地址而已,下面我们通过两段代码来加深一下理解。
(1)访问同一个数组对象
当数组作为方法的参数时,是直接将数组对象的地址传到方法中去的,事实上类似于C语言的传址调用了,这个时候我们如果在方法中对数组进行编辑的话,是会影响这个数组本身的,因为方法访问的对象和我们本身建立的对象是同一个对象,因此方法中改变的就是对象本身,我们用一段代码令数组的元素都扩大两倍并且输出。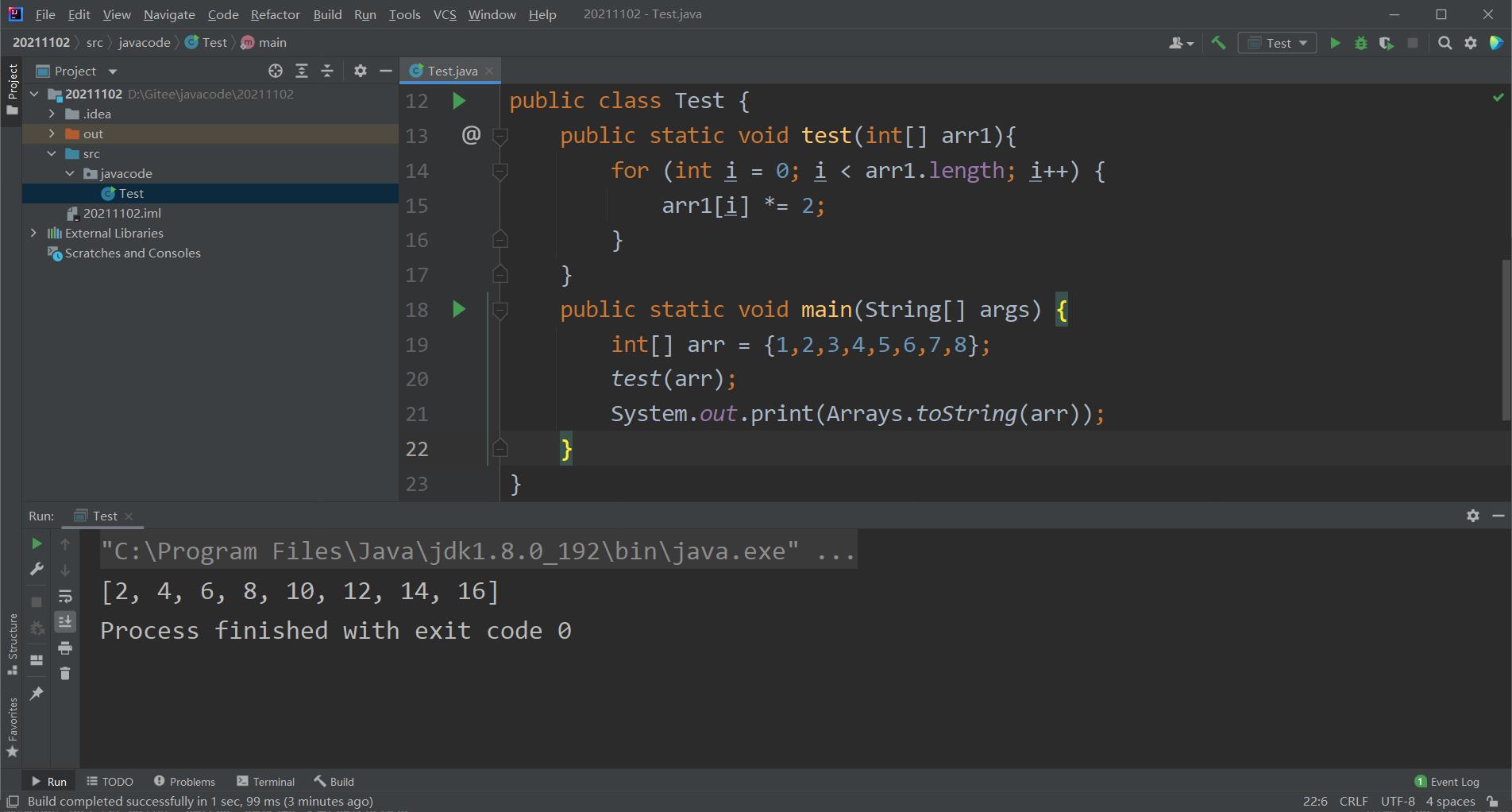
在这段代码中我们的方法中通过arr1这个形式参数可以直接访问到我们的arr数组并且改变它,这就是数组访问同一个对象。
(2)访问其他数组对象
我们可以在方法中调整形参数组的访问对象,例如新建一个对象,因为我们说过数组作为参数实际上是一个值是地址的传值调用,那么我们就可以调整这个值储存的地址,若我们新建一个对象,那么这个形式参数数组的地址就会变为我们新建数组的地址,这时改变形参数组并不会影响到我们原本的数组,因为他们访问的不是同一个对象,大家看完这段代码相信就可以理解了。
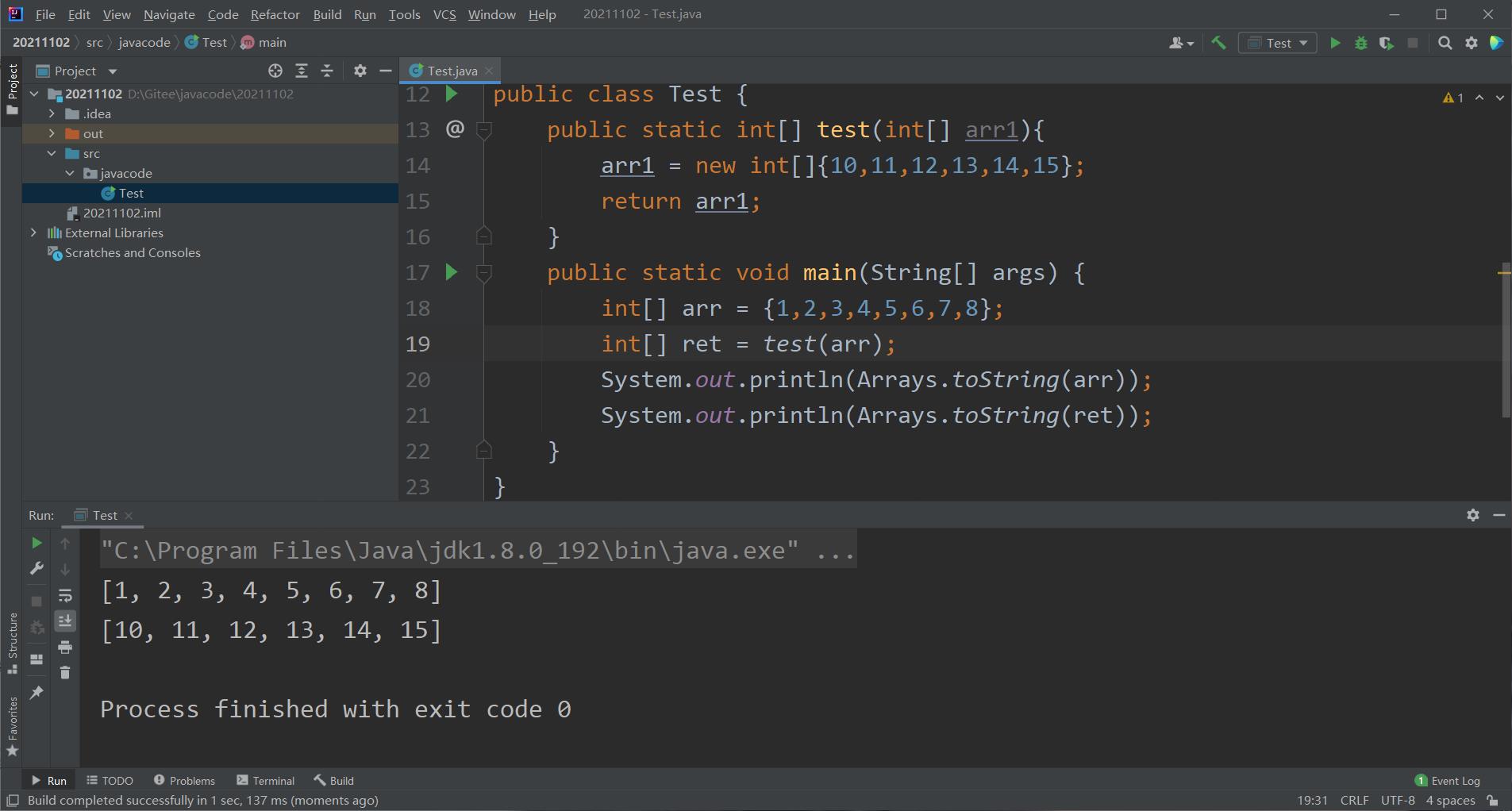
在我们新建了对象之后,arr1的值不再像上边那样被改变,只是我们返回来的arr1是一个新的数组罢了。
(3)引用类型
上述提到的数组作为参数事实上都属于一种引用类型,而一种引用类型是只能储存一个对象的地址,不可以指向多个对象。但是可以多个引用指向同一个对象,例如第一个访问同一个对象的就是形参数组对象也指向我们的数组arr。同时,我们也可以指定引用类型为null,也就是说可以int[] arr= null;这时如果访问改变arr的话便会抛出无效引用异常
(4)补充
在上述所说的改变数组等等,这些都是建立在参数是一个对象而非一个简单类型如某一局部变量,如果是局部变量作为形式参数的话,我们在方法中改变局部变量的值是无效的,因为我们无法访问某个简单类型的地址。例如: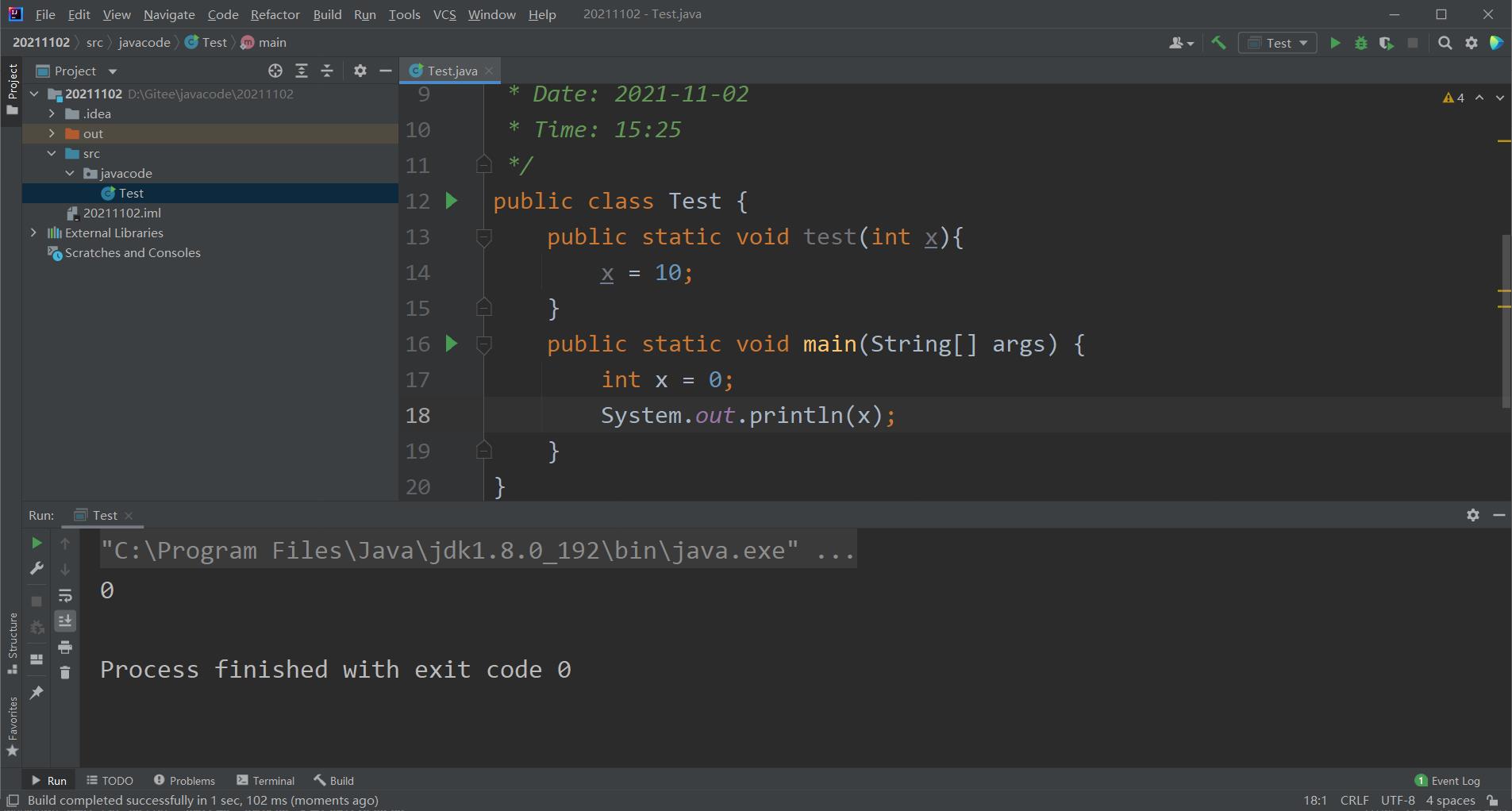
在这里即使我们将x上传并且在方法中修改,但是在最后输出时x的值仍然是零。
4.初识JVM内存区域划分
(1)JVM虚拟机栈
虚拟机栈(JVM Stack): 重点是存储局部变量表(当然也有其他信息). 我们刚才创建的 int[] arr 这样的存储地址的引用就是在这里保存。
(2)本地方法栈
本地方法栈(Native Method Stack): 本地方法栈与虚拟机栈的作用类似. 只不过保存的内容是Native方法的局部变量. 在有些版本的 JVM 实现中(例如HotSpot), 本地方法栈和虚拟机栈是一起的。
(3)PC寄存器
程序计数器 (PC Register): 只是一个很小的空间, 保存下一条执行的指令的地址。
(4)堆
堆(Heap): JVM所管理的最大内存区域. 使用 new 创建的对象都是在堆上保存 (例如前面的 new int[]1, 2, 3 )
(5)方法区
方法区(Method Area): 用于存储已被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据. 方法编译出的的字节码就是保存在这个区域。
(6)运行时常量池
运行时常量池(Runtime Constant Pool): 是方法区的一部分, 存放字面量(字符串常量)与符号引用. (注意 从 JDK1.7 开始, 运行时常量池在堆上)。
5.深浅拷贝
(1)浅拷贝
我们可以理解为,如果我们拷贝了某一个对象,我们通过引用这个拷贝出的对象,就可以操作编辑源对象,那这便是一种浅拷贝。例如对数组的一些拷贝,本质上我们仅仅是对数组的地址进行了拷贝,那么我们通过同一个地址便可以访问到同一个对象,便可以修改这个对象,这就是浅拷贝。
(2)深拷贝
我们可以理解为,如果我们拷贝了某一个对象,我们通过引用这个拷贝出的对象,不可以操作编辑源对象,那这便是一种浅拷贝。例如第三点中补充之中所说的,简单类型的拷贝,无法通过引用修改变量x的值便修改了x的值,这就是一种浅拷贝。
(3)关于深浅拷贝
事实上,对于深浅拷贝的实现完全是看我们的代码是如何写的,如果想实现真正意义上的深拷贝,那么就需要拷贝原内容的本质,而不是它的地址,一般我们都采用new一个新的对象,也可以理解为一个新的地址来储存这个原内容的东西,这就是真正的深拷贝,拷贝出的东西和原来的东西在内存上完全是两块毫不相干的区域。
6.二维数组
(1)对于二维数组本质的理解
二维数组本质上其实是一个一维数组,而这个一维数组的每一个元素又是一个一维数组,这样就组成了二维数组,我们利用一段代码帮助大家理解。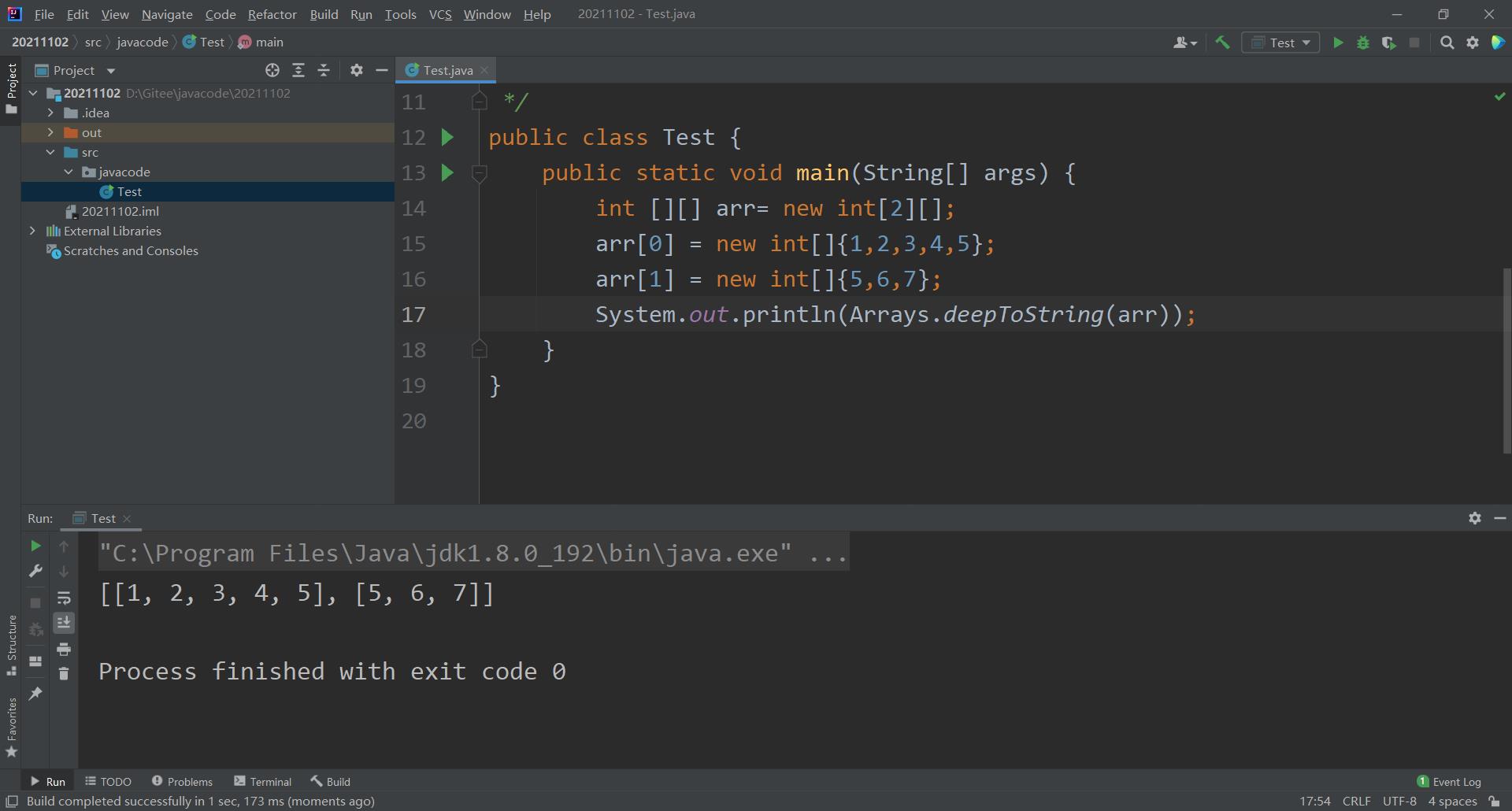
可以看到,我们在定义二维数组arr时,只给了其行数,这其实意味着该二维数组arr中拥有两个元素,但是每个元素是什么我们都没有说明,在引用类型之中,没有初始化的数据类型都是有默认初始值的,未初始化的数组初始值为null,因此第十四行代码的本质是创建了一个含有两个元素且都为null的二维数组,在第十五行和第十六行代码中分别给arr的第一个元素(0下标)和第二个元素(1下标)分别赋了一个一维数组,因此打印出来的结果是如上图。这很明显的说明了二维数组本质是一个储存一维数组的一维数组。
(2)deepToString方法
类似于上面的toString函数,将二维数组转化为字符串形式并且每一个元素都会被[ ]包裹着打印出来。
以上是关于Annual salary30W+Java开发工程师——3.数组的主要内容,如果未能解决你的问题,请参考以下文章