一些机器学习算法
Posted sanxiandoupi
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一些机器学习算法相关的知识,希望对你有一定的参考价值。
假设对于某个数据集,随机变量C表示样本为C类的概率,F1表示测试样本某特征出现的概率,套用基本贝叶斯公式,则如下所示: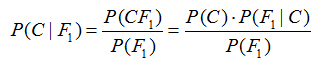
上式表示对于某个样本,特征F1出现时,该样本被分为C类的条件概率。那么如何用上式来对测试样本分类呢?
举例来说,有个测试样本,其特征F1出现了(F1=1),那么就计算P(C=0|F1=1)和P(C=1|F1=1)的概率值。前者大,则该样本被认为是0类;后者大,则分为1类。
对该公示,有几个概念需要熟知:
先验概率(Prior):P(C)是C的先验概率,可以从已有的训练集中计算分为C类的样本占所有样本的比重得出。
证据(Evidence):即上式P(F1),表示对于某测试样本,特征F1出现的概率。同样可以从训练集中F1特征对应样本所占总样本的比例得出。
似然(likelihood):即上式P(F1|C),表示如果知道一个样本分为C类,那么他的特征为F1的概率是多少。
对于多个特征而言,贝叶斯公式可以扩展如下:
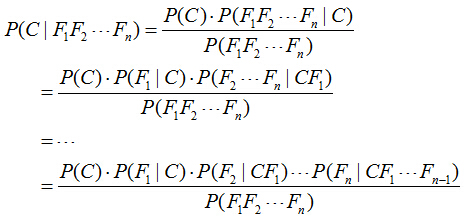
分子中存在一大串似然值。当特征很多的时候,这些似然值的计算是极其痛苦的。现在该怎么办?
为了简化计算,朴素贝叶斯算法做了一假设:“朴素的认为各个特征相互独立”。这么一来,上式的分子就简化成了:
P(C)P(F1|C)P(F2|C)…P(Fn|C)。
这样简化过后,计算起来就方便多了。
这个假设是认为各个特征之间是独立的,看上去确实是个很不科学的假设。因为很多情况下,各个特征之间是紧密联系的。然而在朴素贝叶斯的大量应用实践实际表明其工作的相当好。
其次,由于朴素贝叶斯的工作原理是计算P(C=0|F1…Fn)和P(C=1|F1…Fn),并取最大值的那个作为其分类。而二者的分母是一模一样的。因此,我们又可以省略分母计算,从而进一步简化计算过程。
另外,贝叶斯公式推导能够成立有个重要前期,就是各个证据(evidence)不能为0。也即对于任意特征Fx,P(Fx)不能为0。而显示某些特征未出现在测试集中的情况是可以发生的。因此实现上通常要做一些小的处理,例如把所有计数进行+1(加法平滑(additive smoothing,又叫拉普拉斯平滑(Laplace smothing))。而如果通过增加一个大于0的可调参数alpha进行平滑,就叫Lidstone平滑。
例如,在所有6个分为C=1的影评样本中,某个特征F1=1不存在,则P(F1=1|C=1) = 0/6,P(F1=0|C=1) = 6/6。
经过加法平滑后,P(F1=1|C=1) = (0+1)/(6+2)=1/8,P(F1=0|C=1) = (6+1)/(6+2)=7/8。
注意分母的+2,这种特殊处理使得2个互斥事件的概率和恒为1。
最后,我们知道,当特征很多的时候,大量小数值的小数乘法会有溢出风险。因此,通常的实现都是将其转换为log:
log[P(C)P(F1|C)P(F2|C)…P(Fn|C)] = log[P(C)]+log[P(F1|C)] + … +log[P(Fn|C)]
将乘法转换为加法,就彻底避免了乘法溢出风险。
实例说明:
|
|
要注意的是选用的朴素贝叶斯分类器类别:MultinomialNB,这个分类器以出现次数作为特征值,使用的TF-IDF也能符合这类分布。
其他的朴素贝叶斯分类器如GaussianNB适用于高斯分布(正态分布)的特征,而BernoulliNB适用于伯努利分布(二值分布)的特征。
以上是关于一些机器学习算法的主要内容,如果未能解决你的问题,请参考以下文章