内存四区野指针以及堆栈的区别
Posted still-smile
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了内存四区野指针以及堆栈的区别相关的知识,希望对你有一定的参考价值。
C语言内存四区:代码区、数据区、栈区、堆区
1.代码区(.text):代码区中主要存放程序中的代码(二进制),属性是只读。
2.数据区(静态存储区):主要包括静态全局区和常量区,如果要站在汇编角度细分的话还可以分为很多小的区。
A.全局区(静态区,static):全局变量和静态变量的存储是放在一块的,初始化的(全局变量和静态变量)在一块区域(.data,显示初始化为非零的全局变量), 未初始化的全局变量和未初始化的静态变量在相邻的另一块区域(.bss,显式初始化为0或者并未显式初始化)。 程序结束后有系统释放。
B.常量区 :常量字符串就是放在这里的。(常量、函数名、关键字、字符串等) 程序结束后由系统释放。
3.栈区(stack):内存的分配和释放都是自动进行 ,存放函数的参数值,局部变量的值等。栈内存分配运算内置于处理器的指令集中,效率高,但容量有限,局部变量生命周期短。(linux中查看栈大小,ulimit -s,本机8M)
4.堆区(heap):有些操作对象只有在程序运行时才能确定,这样编译器在编译时无法为他们预先分配内存空间,只有在程序运行时分配,所以称为动态内存,malloc/free等。
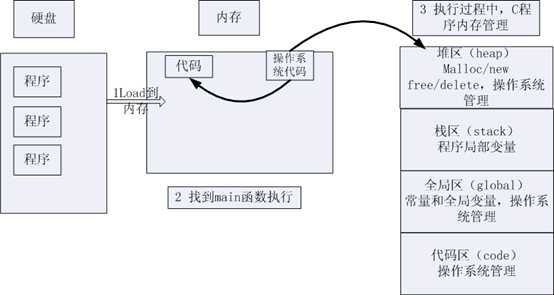
程序的运行:
1 双击运行程序时,操作系统把硬盘上的程序load到内存。
2 操作系统把c代码分成四个区。
3 操作系统找到入口函数main,开始执行。
动态内存的申请和释放
#include <stdlib.h> void *malloc(size_t size);
malloc工作机制:
malloc函数的实质体现在,它有一个将可用的内存块连接为一个长长的列表的所谓空闲链表(堆内存)。调用malloc函数时,它沿连接表寻找一个大到足以满足用户请求所需要的内存块。然后,将该内存块一分为二(一块的大小与用户请求的大小相等,另一块的大小就是剩下的字节)。接下来,将分配给用户的那块内存传给用户,并将剩下的那块(如果有的话)返回到连接表上。调用free函数时,它将用户释放的内存块连接到空闲链上。到最后,空闲链会被切成很多的小内存片段,如果这时用户申请一个大的内存片段,那么空闲链上可能没有可以满足用户要求的片段了。于是,malloc函数请求延时,并开始在空闲链上翻箱倒柜地检查各内存片段,对它们进行整理,将相邻的小空闲块合并成较大的内存块。如果无法获得符合要求的内存块,malloc函数会返回NULL指针,因此在调用malloc动态申请内存块时,一定要进行返回值的判断。
1.只关心申请内存的大小,单位字节。
2.申请空间一定是连续的。有可能申请到比实际申请的大,申请失败时返回空指针。
3.需要将申请的内存用一个指针来接住。
4.需要显示初始化。堆区是不会在自动的分配时做初始化的,包括清零。
#include <stdlib.h> void free(void *ptr);
1.必须提供初始地址,否则会出现内存泄漏的现象。
2.malloc和free配对使用,避免内存泄露。
3.不允许重复释放,因为该空间可能再第一次释放后被分配利用了。
4.free只能释放堆空间,其他都执行错误。
关于野指针
所谓野指针是垃圾指针,不是NULL指针。导致的主要原因如下:
1.指针变量没有初始化。
2.指针被free释放后,没有置NULL。free是把指针所指向的内存空间释放,使内存成为自由内存。而指针仍然指向这块自由内存,很危险。
3.指针操作超越了变量的作用范围。
4.不要返回指向栈内存的指针。
堆和栈的区别
1.申请方式
栈(stack):系统自动分配,如int b;
堆(heap):程序员手动分配,如malloc
2.申请后的系统响应
栈(stack):栈空间剩余内存大于申请空间,才会申请成功,否则报错。
堆(heap):在系统中有一个记录空闲内存地址的链表。当系统收到申请时,系统就会开始遍历链表,寻找第一个空间大于所申请空间的堆节点,然后将该节点从空闲节点链表中删除,将该节点的空间分配给程序。另外,对于多数系统,会在这块内存空间的首地址处记录本次分配的大小。这样,代码中的删除的语句才能正确释放本内存空间。如果找到的堆节点的大小与申请的大小不同,系统会自动的将多余的那部分重新装入空闲链表中。
3.申请大小的限制。
栈(stack):栈是向低地址扩展的数据结构,是一块连续的内存区域。栈的容量和起始地址都是系统预先设置好的,申请过大的内存会导致栈溢出,因此,能获取的空间比较小(在Linux version 3.2.0-87-generic-pae中栈的大小为8M)
堆(heap):堆是向高地址扩展的数据结构,是不连续的内存区域。这是由于系统采用链表来存储空闲的内存地址,地址是不连续的,而链表遍历的方向是由低地址向高地址。堆的大小也受限于有效的虚拟内存,因此获取空间比较灵活,也比较大。
4.申请速度的限制
栈(stack):由系统自动分配,速度比较快,但程序员一般无法控制。
堆(heap):由malloc等分配,一般速度比较慢,而且容易产生内存碎片,不过使用方便。
5.堆和栈中的存储内容
栈(stack):在调用函数的时候,第一个进栈的是函数调用语句的下一条可执行语句的地址,然后是函数的各个参数,一般情况,参数由右往左入栈的,然后是函数中的局部变量。当本次函数调用结束后,局部变量先出栈,然后是参数,最后栈顶指针指向最开始的存储地址,也就是调用该函数出的下一条指令,程序由该点继续运行。
堆(heap):一般在堆的头部用一个字节存放堆的大小,堆中的具体内容由程序员安排。
以上是关于内存四区野指针以及堆栈的区别的主要内容,如果未能解决你的问题,请参考以下文章