九种经典排序算法详解(冒泡排序,插入排序,选择排序,快速排序,归并排序,堆排序,计数排序,桶排序,基数排序)
Posted hunrry
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了九种经典排序算法详解(冒泡排序,插入排序,选择排序,快速排序,归并排序,堆排序,计数排序,桶排序,基数排序)相关的知识,希望对你有一定的参考价值。
综述
最近复习了各种排序算法,记录了一下学习总结和心得,希望对大家能有所帮助。本文介绍了冒泡排序、插入排序、选择排序、快速排序、归并排序、堆排序、计数排序、桶排序、基数排序9种经典的排序算法。针对每种排序算法分析了算法的主要思路,每个算法都附上了伪代码和C++实现。
算法分类
原地排序(in-place):没有使用辅助数据结构来存储中间结果的排序**算法。
非原地排序(not-in-place / out-of-place):使用了辅助数据结构来存储中间结果的排序算法
稳定排序:数列值(key)相等的元素排序后相对顺序维持不变
不稳定排序:不属于稳定排序的排序算法

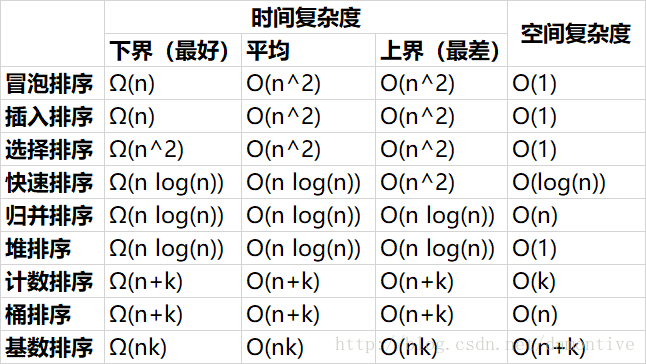
算法复杂度
1. 冒泡排序(Bubble Sort)
思路
不断地遍历数列,比较相邻元素,每次把无序部分最大的元素放到最后,遍历n-1次后,数列就是有序的了。
伪代码
BUBBLE_SORT(A, n) for( i from 0 to n-2) //遍历n-1次 for(j from 0 to n-2-i) //比较无序部分的所有相邻元素 if(A[j] > A[j+1]) //如果前面的元素大,放到后面去 swap(A[i],A[j+1]) swapped = true if(not swapped) //如果以第j个数为起点遍历,没有发生交换,说明后面已经有序了 break;
最好情况
输入数列有序,第一次遍历结束就会完成排序,时间复杂度最好为Ω(n)
C++实现
void bubbleSort(vector<int> &arr) { for(int i = 0; i < arr.size() - 1; i++) { bool swapped = false; for(int j = 0; j < arr.size() - 1 - i; j++) { if(arr[j] > arr[j + 1]) { int temp = arr[j]; arr[j] = arr[j + 1]; arr[j + 1] = temp; swapped = true; } } if(!swapped) { break; } } }
2. 插入排序(Insertion Sort)
思路
把数列分为有序和无序部分,每次从无序部分拿出第一个元素,然后从后向前扫描有序部分,找到相应位置并插入,具体来说就是对于比当前元素大的元素,往后移动一位。直到找到比当前元素小的,在该元素后面插入当前元素
伪代码
INSERTION_SORT(A,n) for(i from 1 to n-1) //从1开始遍历无序数组 temp = A[i] //取出当前元素 j = i-1 while(j >= 0 and temp < A[j]) //比temp大的元素后移 A[j+1] = A[j] j -= 1 arr[j+1] = temp; //temp 放入第0个或者第一个不比temp大的元素
最好情况
输入数列有序,每次插入都是直接插在了有序部分的后面,时间复杂度最好为Ω(n)
C++实现
void insertionSort(vector<int> &arr) { for(int i=1; i<arr.size(); i++) { int temp = arr[i]; int j = i -1; while(j >=0 && temp < arr[j]) { arr[j+1] = arr[j]; j--; } arr[j+1] = temp; } }
3. 选择排序(Selection Sort)
思路
数列分为有序部分和无序部分,重复下列过程n次:找到无序部分中最小的数,放到有序部分的最后面(即和无序部分的第一个置换)
伪代码
SELECTION_SORT(A, n) for(i from 0 to n-2) //i指向无序部分的开头,n-2为倒数第二个元素的索引 for(j from i to n-1) // 找到无序部分最小的元素 minLoc = findMin() swap(A[i],A[minLoc]) //最小的元素置换到i位置上(加入了有序部分)
C++实现
void selectionSort(vector<int> &arr) { for(int i=0; i<arr.size()-1; i++) { int min = INT_MAX; int minLoc = -1; for(int j=i; j<arr.size(); j++) { if(arr[j] < min) { min = arr[j]; minLoc = j; } } arr[minLoc] = arr[i]; arr[i] = min; } }
4. 快速排序 (Quick Sort)
思路
使用分治算法,每次以pivot为基准将数列分成两部分,左边的都小于等于基准,右边的都大于基准,然后分别递归地对左右两部分进行快速排序(终止条件是元素个数为1个或者0个)。算法的核心在于分区(把数列分成两部分)
分区时,从数列中选择一个元素作为pivot(一般选最后一个,翻译为“基准”或者“哨兵”),使用两个指针,第一个指针始终指向左边部分的结尾(初始位置为-1),第二个指针用于遍历数列(初始位置为0),发现小于等于pivot的就和右部分第一个数字互换(相当于把数加入了左边部分),比pivot大的数就跳过(相当于把数加入了右边部分)
伪代码
QUICK_SORT(A,head,tail) //输入数列A,[head, tail),不包含tail if(tail - head > 1) //元素个数低于1个,有序,停止递归 pivot = PARTITION(A,head,tail) //分区,获得pivot索引 QUICK_SORT(A,head,pivot)//递归 QUICK_SORT(A,pivot+1,tail)//递归,pivot已经在正确的位置上了,不参与后续排序 PARTITION(A,head,tail) //分区,[head,tail) i = head - 1 //i初始化为head-1,代表着左半边现在没有元素 pivot = A[tail-1] //选择最后一个元素作为pivot for(j from head to tail-2) //遍历全部元素(除了最后一个 tail-1) if(A[j] <= pivot)//发现小于等于pivot的元素,置换(大于的话,j就直接后移了) i += 1 //i此时指向了大于pivot的区的第一个元素 swap(A[i],A[j]) swap(A[i+1],A[tail-1]) //最后把pivot放到中间位置 return i+1 //返回pivot
最坏情况
- 输入的数列是有序数列,这样每次分区选到的pivot都是当前最大值,每次分区的结果都是左边n-1个数,右边0个数,需要进行n-1分区,递归深度为n,时间复杂度为O(n^2)
- 输入的数列是逆序数列,与上面的情况类似,时间复杂也也为O(n^2)
最好情况
每次分区的结果都是均匀的分成了左右两部分,那么时间复杂度就是Θ(n log(n))
C++实现
void quickSort(vector<int> &arr) { quickSort(arr, 0, arr.size()); } void quickSort(vector<int> &arr, int head, int tail) { if(tail - head > 1) { int pivot = partition(arr, head, tail); quickSort(arr, head, pivot); quickSort(arr, pivot+1, tail); } } int partition(vector<int> &arr, int head, int tail) { int i = head - 1; int pivot = arr[tail - 1]; for(int j = head; j < tail - 1; j++) { //这里不能用<,数组为[3,3]这样时,i没有移动过,一直为-1,quickSort在右半部分永久进行递归[0,2) if(arr[j] <= pivot) { i++; int temp = arr[i]; arr[i] = arr[j]; arr[j] = temp; } } arr[tail - 1] = arr[i + 1]; arr[i + 1] = pivot; return i + 1; }
5. 归并排序(Merge Sort)
思路
使用分治算法,把数列均匀地分成左右两部分,分别进行归并排序(递归终止条件为只有一个或者0个元素),然后将左右两个有序数列合并到一起。
伪代码
MERGE_SORT(A,head,tail) if(tail - head < 2) //元素个数小于2个就停止了 return mid = (head + tail)/2 MERGE_SORT(A,head,mid) //左边归并排序 MERGE_SORT(A,mid,tail) //右边归并排序 copy A[head,mid) to B //复制A的左半部分到B,B有序 copy A[mid,tail) to C //复制A的右半部分到C,C有序 merge B,C to A //合并B和C两个有序数列,将结果放在A中
C++实现
void mergeSort(vector<int> &arr) { mergeSort(arr, 0, arr.size()); } void mergeSort(vector<int> &arr, int head, int tail) { if(tail - head < 2) { return; } int mid = (head + tail) / 2; mergeSort(arr, head, mid); mergeSort(arr, mid, tail); vector<int> left(arr.begin() + head, arr.begin() + mid); vector<int> right(arr.begin() + mid, arr.begin() + tail); int i = 0, j = 0, k = head; while(i < left.size() && j < right.size() && k < tail) //这里k判断条件是小于tail,不是arr.size()!! { if(left[i] < right[j]) { arr[k++] = left[i++]; } else { arr[k++] = right[j++]; } } if(i == left.size()) { while(j < right.size() && k < tail) { arr[k++] = right[j++]; } } else if(j == right.size()) { while(i < left.size() && k < tail) { arr[k++] = left[i++]; } } }
6. 堆排序(Heap Sort)
思路
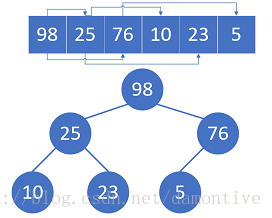
构建大顶堆(降序构建小顶堆),然后交换root节点和最后一个节点,此时将堆的大小减1,并利用堆化算法把堆重新调整为大顶堆,重复上述过程,直到大小为1,堆排序完成,因为每次都是把堆当前最大的数放到堆后面,所以数列最终变成有序了。
堆化算法针对root的左右孩子均为大顶堆,但是root自己可能比左右孩子小的情况,算法比较root和左右孩子,选择最大的和root进行置换(如果root最大就不用置换了),置换后以被置换的孩子为root继续执行堆化算法,直到当前root比左右孩子大了或者已经是叶子节点了。
伪代码
//堆化算法,左右孩子均为大顶堆,root可能比左右孩子小,违反大顶堆性质MAX_HEAPIFY(A,i) //i是当前root的索引 left = i*2+1 right = i*2 + 2 //找到左、右孩子,root中的最大值 max = i if(left < heapSize and A[left] > A[i]) max = left; if(right <headpSize and A[right] > A[max]) max = right if(max != i) //最大值不是root节点,交换之,并继续堆化被破坏的子堆 swap(A[i],A[max]) MAX_HEAPIFY(A,max) //自底向上构建大顶堆 BUILD_MAX_HEAP(A,n) //从最后一个父节点开始(n-1)为最后一个元素的索引,自底向上执行堆化算法 for(i from ((n-1)-1)/2 to 0) MAX_HEAPIFY(A,i) ///堆排序算法,不断把root置换到堆的后面,heapSize减一并执行堆化算法 HEAP_SORT(A,n) BUILD_MAX_HEAP(A,n) for(i from n-1 to 1) swap(A[i],A[0]) heapSize -= 1 MAX_HEAPIFY(A,0)
C++实现
void heapSort(vector<int> &arr) { buildMaxHeap(arr); int heapSize = arr.size(); for(int i = arr.size() - 1; i > 0; i--) { int temp = arr[i]; arr[i] = arr[0]; arr[0] = temp; heapSize--; maxHeapify(arr,heapSize,0); } } void buildMaxHeap(vector<int> &arr) { for(int i = ((arr.size() - 1) - 1) / 2; i >= 0; i--) { maxHeapify(arr,arr.size(),i); } } void maxHeapify(vector<int> &arr, int heapSize, int root) { int left = root * 2 + 1; int right = root * 2 + 2; int max = root; if(left < heapSize && arr[left] > arr[max]) { max = left; } if(right < heapSize && arr[right] > arr[max]) { max = right; } if(max != root) { int temp = arr[max]; arr[max] = arr[root]; arr[root] = temp; maxHeapify(arr,heapSize,max); } }
7. 计数排序(Counting Sort)
思路
计数排序是一种非比较排序,对数列中每个元素X,通过统计数列中小于等于X的元素个数来计算X所处的位置进行排序。使用数组统计元素个数, counts[i]记录的是小于等于 i 的元素个数。
伪代码
COUNTING_SORT(A,n) for(i from 0 to n-1) //计数 counts[A[i]]++ for(i from 1 to n-1) //累加,以便进行反向填充 counts[i] += counts[i-1] for(i from n-1 to 0) //反向填充是为了保证排序是稳定的 B[counts[A[i]]-1] = A[i] counts[A[i]] -= 1 A = B
C++实现:使用数组计数
void countingSort(vector<int> &arr) { int max = 0; for(int i = 0; i < arr.size(); i++) { if(arr[i] > max) { max = arr[i]; } } vector<int> counts(max + 1, 0); for(int i = 0; i < arr.size(); i++) { counts[arr[i]]++; } for(int i = 1; i <= max; i++) { counts[i] += counts[i - 1]; } vector<int> tempArr(arr.size(), -1); for(int i = arr.size() - 1; i >= 0; i--) { tempArr[counts[arr[i]] - 1] = arr[i]; counts[arr[i]]--; } arr = move(tempArr); }
8. 桶排序(Bucket Sort)
思路
把数列中元素的值范围分割成多个长度相等的区间,称为桶,把元素按值所在区间分别放到不同的桶中。然后桶内分别进行排序(比如使用插入排序),最终获得有序数列
伪代码
#下面的假设值范围为0~999,桶数目BNUM为100 INDEX_OF(j) return j/10 //这里根据实际的数据情况和运行环境可以调整桶的分配方式 BUCKET_SORT(A,n) list B //桶们 for(i from 0 to n-1) //分桶 insert A[i] to B[INDEX_OF[A[i]]] for(i from 0 to BUMN-1) INSERTION_SORT(B[i]) //分别桶内排序 A = B[0] + B[1] + ... + B[BNUM-1] //按序连接各个桶
C++实现
#define BUCKETS_NUM 100 int indexOf(int num) { return num/10; } void bucketSort(vector<int> &arr) { vector<vector<int>> buckets(BUCKETS_NUM); for(int i=0; i<arr.size(); i++) { buckets[indexOf(arr[i])].push_back(arr[i]); } for(int i=0; i<BUCKETS_NUM; i++) { insertionSort(buckets[i]); } int k =0; for(int i=0; i<BUCKETS_NUM; i++) { for(int j=0; j<buckets[i].size(); j++) { arr[k++] = buckets[i][j]; } } }
9. 基数排序(Radix Sort)
思路
把元素按照位置分割成不同的数字,从最低位部分开始,一直到最高位部分,分别对每部分进行入桶操作,入桶时桶内元素的相对顺序不变,然后将桶按顺序连接起来,进行下一部分的入桶排序。对整数来说,位数较短的前面补0,下面叙述假定数列元素都是非负整数
为什么多次入桶后数列就有序了
因为进行高位入桶时是按序入桶的,所以高位相同的数字,低位的顺序仍然保留下来了。只有高位不同的数字,低位的顺序才会被打乱,高位不同肯定是按照高位的顺序排的,所以打乱没有影响。
下面举个例子说明一下。
假设待排序数列为 01, 88, 13, 78, 56, 79, 07 , 28, 76 这里为了方便理解,位数不够的前面已经补0了。
第一次按照最低位(个位数)入桶
| 桶编号 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|---|---|---|
| - | 01 | 13 | 56 | 07 | 78 | 79 | ||||
| - | 76 | 88 | ||||||||
| - | 28 |
将桶按顺序连接起来,形成新的数列01, 13, 56, 76, 07, 78, 88, 28, 79
第二次按照次最低位(十位数)入桶
| 桶编号 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|---|---|---|
| 01 | 13 | 28 | 56 | 76 | 88 | |||||
| 07 | 78 | |||||||||
| 79 |
将桶按顺序连接起来,得到新的数列01, 07, 13, 28, 56, 76, 78, 79, 88,排序完成
为什么要从最低位开始
以非负整数为例,每次从最低位开始的话,每次入桶都有10个桶。如果从最高位开始的话,第一次10个桶,第二次如果还是10个桶,那么如果低位不同,高位的相对顺序就会被打乱,这显然是错误的。那么为了保证高位的顺序不被打乱。就必须要在高位的桶内进行排序,即每个桶里面要再分10个桶。第二位总共需要10*10=100个桶。以此类推n位就需要10^个桶,虽然也可以实现,但是开销太大,所以不从最高位开始。
伪代码
//以对非负整数进行基数排序为例 RADIX_SORT(A,n) for(i from d-1 to 0) //d是数字的位数,进行d次入桶(排序) for(j from 0 to n-1) put A[j] into B[D[A[j]]] //D[x]是x第i位的值。 A = B[0] + B[1] + ... + B[9] //按序连接桶
C++实现
void radixSort(vector<int> &arr) { vector<vector<int>> buckets(10); int radix = 1; for(int i=0; i<10; i++) //INT_MAX为10位数,所以最多进行10次入桶 { for(int j = 0; j < arr.size(); j++) { buckets[(arr[j] / radix) % 10].push_back(arr[j]); } int k = 0; for(int i = 0; i < 10; i++) { for(int j = 0; j < buckets[i].size(); j++) { arr[k++] = buckets[i][j]; } if(buckets[i].size() == arr.size())//全部在一个桶里了,提前结束 { return; } buckets[i].clear(); } radix*=10; } }
以上是关于九种经典排序算法详解(冒泡排序,插入排序,选择排序,快速排序,归并排序,堆排序,计数排序,桶排序,基数排序)的主要内容,如果未能解决你的问题,请参考以下文章