java中使用pdfbox对pdf文件进行操作时,如何实现插入文本的自动换行操作?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了java中使用pdfbox对pdf文件进行操作时,如何实现插入文本的自动换行操作?相关的知识,希望对你有一定的参考价值。
如题,我使用的是如下语句插入文本的
PDPageContentStream contentStream = new PDPageContentStream(document, pdPage);
contentStream.beginText();
contentStream.setFont( font, 12 );
contentStream.moveTextPositionByAmount(100,700);
contentStream.drawString(s);
contentStream.endText();
如何实现自动换行,求高手解答
int rows = 700;
String str = text.getText();
String[] outs = str.split("\n");
PDFdoc = new PDDocument();
PDPage page = new PDPage();
PDFdoc.addPage(page);
PDFont font = PDType1Font.TIMES_ROMAN;
PDPageContentStream contentStream = new PDPageContentStream(PDFdoc, page);
for(int i=0;i<outs.length;i++)
if(rows-FontSize>100)
rows -= FontSize;
else
contentStream.close();
page = new PDPage();
PDFdoc.addPage(page);
contentStream = new PDPageContentStream(PDFdoc, page);
rows = 700;
contentStream.beginText();
contentStream.moveTextPositionByAmount( 100, rows );
contentStream.setFont( font, FontSize );
contentStream.drawString( outs[i] );
contentStream.endText();
contentStream.close();
PDFdoc.save(new FileOutputStream(fdoc));
PDFdoc.close();
needSave = false;
setTitle(Program.ProgramName+" - "+fdoc.getName());
注:FontSize是字体大小,我暂时设定行距为0,你可以自己再改改,换行大概就是这个思路了
pdf一页的纵坐标应该是从上到下800到0,保留一定的边距的话从700到100就是整个打印文本的范围。应该是这样的,我只是为了赶我们变态的操作系统实验作业,没有再多去尝试(吐槽:这明显跟操作系统没有任何关系,我们老师还拿这个当作业,难为我们也不是这样难为的……操作系统有难题不布置,偏偏布置这种恶心人的题,最后贴上
普通操作系统实验考试:内存管理,从页表地址到实际物理地址的转换;文艺操作系统实验考试:nachos的结构分析(暂定,欢迎更改);二逼操作系统实验考试:文件操作,pdf文件的读写
)
参考资料:http://pdfbox.apache.org/userguide/cookbook/creation.html#HelloWorld
本回答被提问者和网友采纳java代码实现对pdf文件文本和图片内容的提取
教程
pom文件引入jar依赖
<!-- https://mvnrepository.com/artifact/org.apache.pdfbox/pdfbox -->
<dependency>
<groupId>org.apache.pdfbox</groupId>
<artifactId>pdfbox</artifactId>
<version>3.0.0-RC1</version>
</dependency>
<dependency>
<groupId>com.github.jai-imageio</groupId>
<artifactId>jai-imageio-jpeg2000</artifactId>
<version>1.3.0</version>
</dependency>java核心代码实现
import org.apache.pdfbox.Loader;
import org.apache.pdfbox.pdmodel.PDDocument;
import org.apache.pdfbox.pdmodel.PDPage;
import org.apache.pdfbox.pdmodel.PDPageTree;
import org.apache.pdfbox.pdmodel.PDResources;
import org.apache.pdfbox.pdmodel.graphics.image.PDImageXObject;
import org.apache.pdfbox.text.PDFTextStripper;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.*;
import java.util.Iterator;
public class PDFUtil
public static void main(String[] args) throws IOException
//提取图片
extractImages("C:\\\\Users\\\\liuya\\\\Desktop\\\\word\\\\帆软报表帮助文档.pdf");
//提取文字
extractText("C:\\\\Users\\\\liuya\\\\Desktop\\\\word\\\\帆软报表帮助文档.pdf");
/**
* 提取文本
* @return
*/
public static void extractText(String path)
try
File fdf = new File(path);
//通过文件名加载文档
PDDocument pdd = Loader.loadPDF(fdf);
//获取文档的页数
int pageNumber = pdd.getNumberOfPages();
//剥离器(读取pdf文件)
PDFTextStripper stripper = new PDFTextStripper();
//排序
stripper.setSortByPosition(true);
//设置要读取的起始页码
stripper.setStartPage(1);
//设置要读取的结束页码
stripper.setEndPage(pageNumber);
// System.out.println(stripper.getText(pdd));
//生成的txt的文件路径
String docPath =path.substring(0,path.lastIndexOf("."))+".txt";
File doc = new File(docPath);
if(!doc.exists())
doc.createNewFile();
//文件输出流
FileOutputStream fos = new FileOutputStream(doc);
Writer writer = new OutputStreamWriter(fos, "utf-8");
stripper.writeText(pdd, writer);
writer.close();
fos.close();
System.out.println("提取文本完成");
catch (Exception e)
e.printStackTrace();
/**
* 提取图片
* @return
*/
public static boolean extractImages(String path)
boolean result = true;
try
File fdf = new File(path);
//通过文件名加载文档
PDDocument document = Loader.loadPDF(fdf);
PDPageTree pages = document.getPages();
Iterator<PDPage> iter = pages.iterator();
//生成的txt的文件路径
String imagePath =path.substring(0,path.lastIndexOf("."));
while(iter.hasNext())
PDPage page = iter.next();
PDResources resources =page.getResources();
resources.getXObjectNames().forEach(e->
try
if(resources.isImageXObject(e))
PDImageXObject imageXObject=(PDImageXObject)resources.getXObject(e);
BufferedImage bufferedImage= imageXObject.getImage();
System.out.println(bufferedImage);
ImageIO.write(bufferedImage,"jpg",new File(imagePath+"_"+e+".jpg"));
catch (IOException ioException)
ioException.printStackTrace();
);
System.out.println("----------------------------------------------");
System.out.println("提取图片完成");
// document.save(fdf);
document.close();
catch(IOException ex)
ex.printStackTrace();
return false;
return result;
idea控制台运行输出
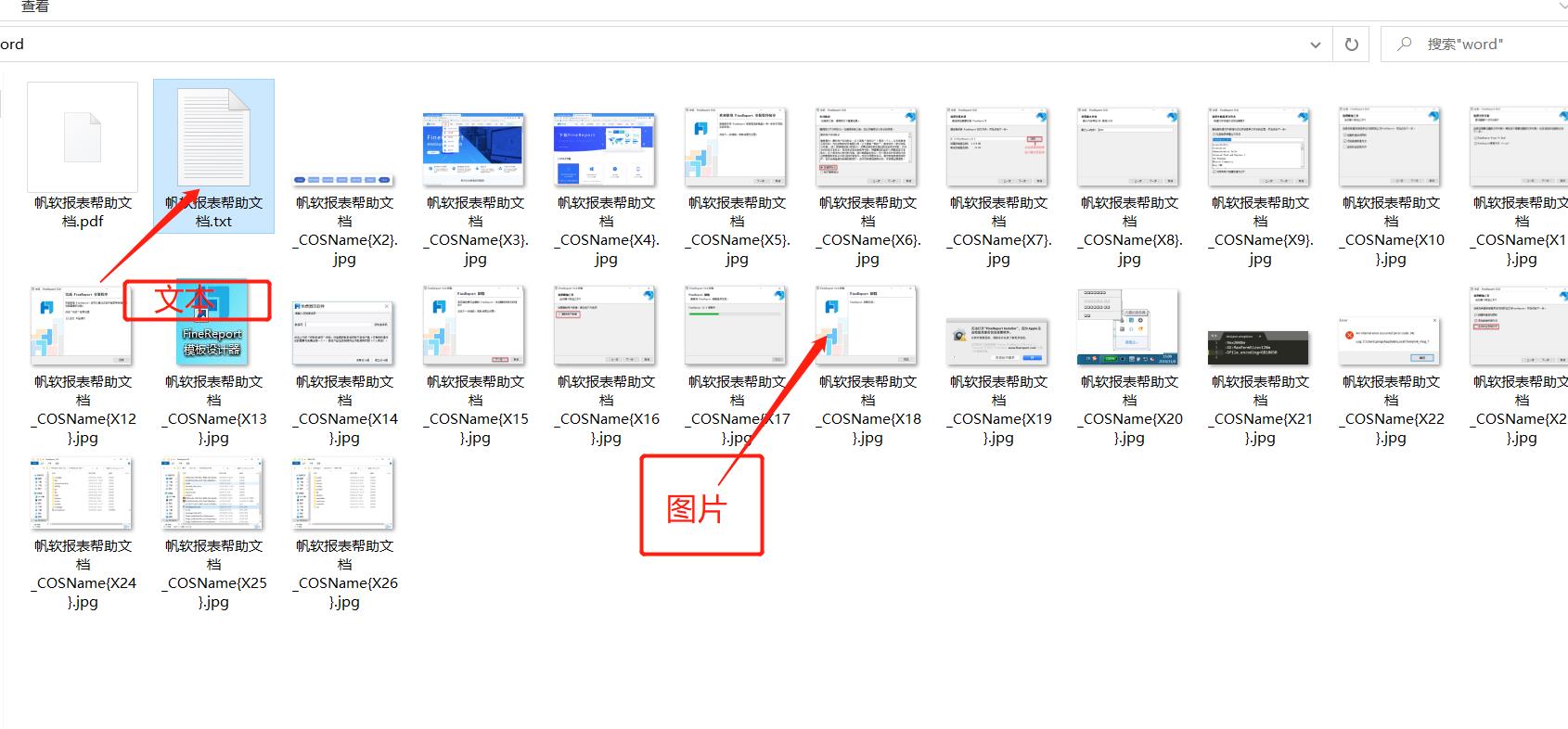
提取文件和原pdf文件在同一文件夹下
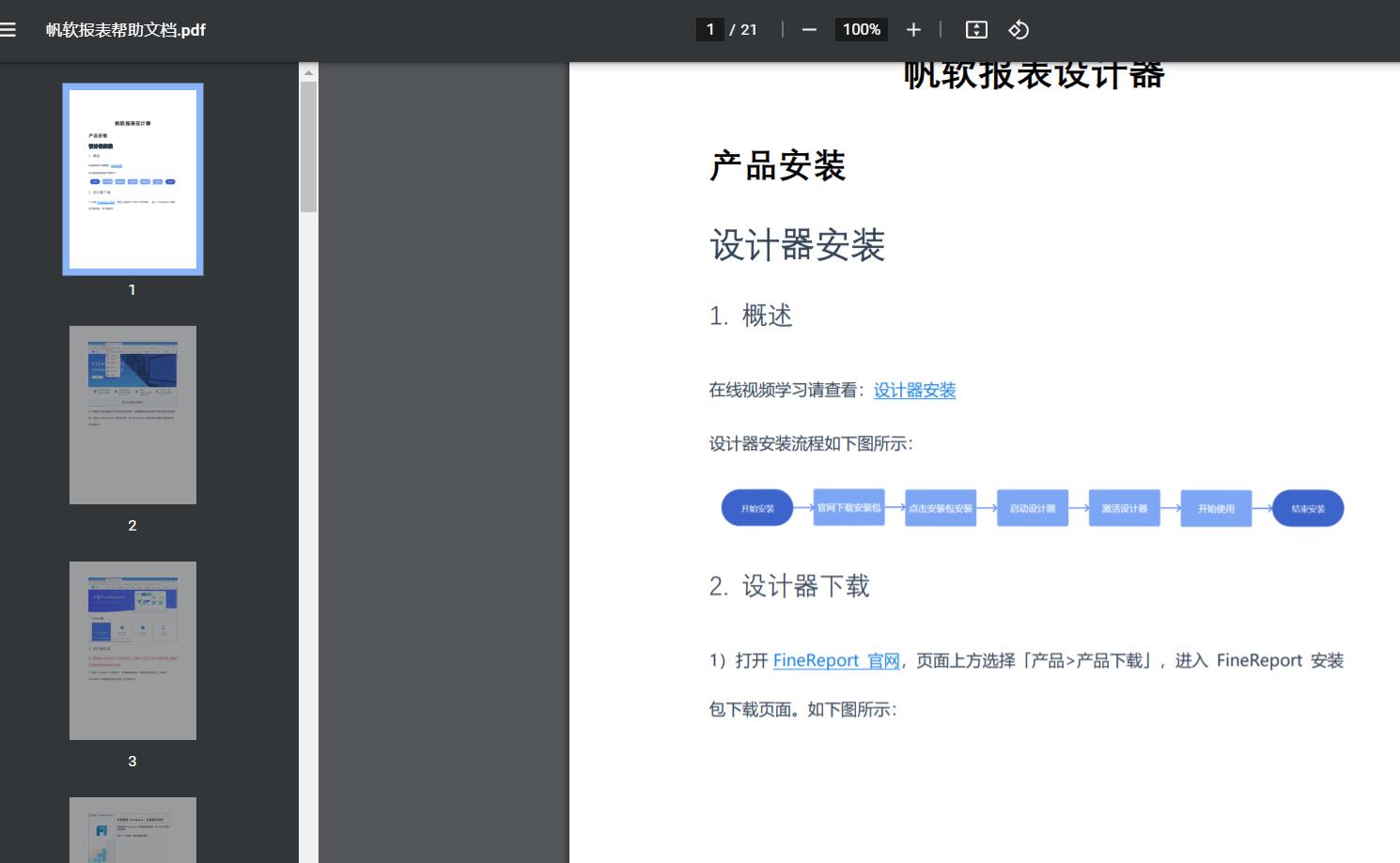
原pdf内容部分展示
提取文本展示
提取图片展示
相关文章推荐
JAVA实现PDF合并、拆分代码工具类 https://blog.csdn.net/weixin_40986713/article/details/120065363
https://blog.csdn.net/weixin_40986713/article/details/120065363
如果有想要看的相关技术实现的文章,请在评论区留言,博主尽量满足!!!
以上是关于java中使用pdfbox对pdf文件进行操作时,如何实现插入文本的自动换行操作?的主要内容,如果未能解决你的问题,请参考以下文章