说说 python-docx 解析 word 文档的原理
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了说说 python-docx 解析 word 文档的原理相关的知识,希望对你有一定的参考价值。
参考技术A 首先通过 pip 安装 python-docx,命令为 pip install python-docx 。python-docx 使用 Document 对象来表示整个 docx 文档。其内部包含 一个Paragraph 对象列表。每个 Paragraph 对应 docx 文档的一个段落。
word 文档中除了字符串,还包含字体、大小、颜色等样式信息。相同样式的连续字符串,就会被保存在一个 Run 对象中。
假设 docx 文档中有下面这些内容:
那么经过 python-docx 解析,就会生成 3 个 Run 对象:
python用python-docx读写word文档
python-docx库可用于创建和编辑Microsoft Word(.docx)文件。
官方文档:https://python-docx.readthedocs.io/en/latest/index.html
备注:
doc是微软的专有的文件格式,docx是Microsoft Office2007之后版本使用,其基于Office Open XML标准的压缩文件格式,比
doc文件所占用空间更小。docx格式的文件本质上是一个ZIP文件,所以其实也可以把.docx文件直接改成.zip,解压后,里面的
word/document.xml包含了Word文档的大部分内容,图片文件则保存在word/media里面。
python-docx不支持.doc文件,间接解决方法是在代码里面先把.doc转为.docx。
一、安装包
pip3 install python-docx
二、创建word文档
下面是在官文示例基础上对个别地方稍微修改,并加上函数的使用说明
from docx import Document from docx.shared import Inches document = Document() #添加标题,并设置级别,范围:0 至 9,默认为1 document.add_heading(‘Document Title‘, 0) #添加段落,文本可以包含制表符(\\t)、换行符(\\n)或回车符(\\r)等 p = document.add_paragraph(‘A plain paragraph having some ‘) #在段落后面追加文本,并可设置样式 p.add_run(‘bold‘).bold = True p.add_run(‘ and some ‘) p.add_run(‘italic.‘).italic = True document.add_heading(‘Heading, level 1‘, level=1) document.add_paragraph(‘Intense quote‘, style=‘Intense Quote‘) #添加项目列表(前面一个小圆点) document.add_paragraph( ‘first item in unordered list‘, style=‘List Bullet‘ ) document.add_paragraph(‘second item in unordered list‘, style=‘List Bullet‘) #添加项目列表(前面数字) document.add_paragraph(‘first item in ordered list‘, style=‘List Number‘) document.add_paragraph(‘second item in ordered list‘, style=‘List Number‘) #添加图片 document.add_picture(‘monty-truth.png‘, width=Inches(1.25)) records = ( (3, ‘101‘, ‘Spam‘), (7, ‘422‘, ‘Eggs‘), (4, ‘631‘, ‘Spam, spam, eggs, and spam‘) ) #添加表格:一行三列 # 表格样式参数可选: # Normal Table # Table Grid # Light Shading、 Light Shading Accent 1 至 Light Shading Accent 6 # Light List、Light List Accent 1 至 Light List Accent 6 # Light Grid、Light Grid Accent 1 至 Light Grid Accent 6 # 太多了其它省略... table = document.add_table(rows=1, cols=3, style=‘Light Shading Accent 2‘) #获取第一行的单元格列表 hdr_cells = table.rows[0].cells #下面三行设置上面第一行的三个单元格的文本值 hdr_cells[0].text = ‘Qty‘ hdr_cells[1].text = ‘Id‘ hdr_cells[2].text = ‘Desc‘ for qty, id, desc in records: #表格添加行,并返回行所在的单元格列表 row_cells = table.add_row().cells row_cells[0].text = str(qty) row_cells[1].text = id row_cells[2].text = desc document.add_page_break() #保存.docx文档 document.save(‘demo.docx‘)
创建的demo.docx内容如下:
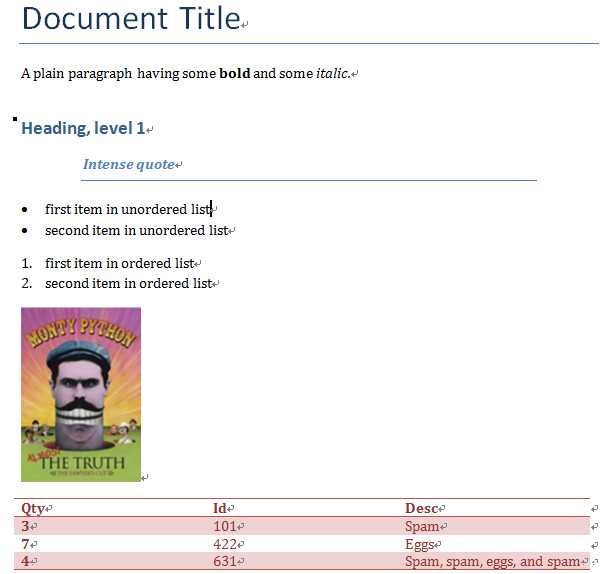
三、读取word文档
from docx import Document doc = Document(‘demo.docx‘) #每一段的内容 for para in doc.paragraphs: print(para.text) #每一段的编号、内容 for i in range(len(doc.paragraphs)): print(str(i), doc.paragraphs[i].text) #表格 tbs = doc.tables for tb in tbs: #行 for row in tb.rows: #列 for cell in row.cells: print(cell.text) #也可以用下面方法 ‘‘‘text = ‘‘ for p in cell.paragraphs: text += p.text print(text)‘‘‘
运行结果:
Document Title A plain paragraph having some bold and some italic. Heading, level 1 Intense quote first item in unordered list second item in unordered list first item in ordered list second item in ordered list 0 Document Title 1 A plain paragraph having some bold and some italic. 2 Heading, level 1 3 Intense quote 4 first item in unordered list 5 second item in unordered list 6 first item in ordered list 7 second item in ordered list 8 9 Qty Id Desc 3 101 Spam 7 422 Eggs 4 631 Spam, spam, eggs, and spam [Finished in 0.2s]
以上是关于说说 python-docx 解析 word 文档的原理的主要内容,如果未能解决你的问题,请参考以下文章