Python数据分析笔记#7.3.1 字符串对象方法
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python数据分析笔记#7.3.1 字符串对象方法相关的知识,希望对你有一定的参考价值。
参考技术A「目录」
数据清洗和准备
Data Cleaning and Prepration
--------> 字符串对象方法
字符串对象方法
Python能够成为流行的数据处理语言的部分原因是其易于处理字符串和文本。大部分文本运算都直接做成了字符串对象的内置方法。
split方法可以 通过指定分隔符对字符串进行切片 。
例如,以逗号分割的字符串可以用split拆分成数段:
strip可以 去除字符串头尾指定的字符 ,默认是空白符或换行符。
strip常常与split一起使用:
利用 加法可以将字符串连接起来 :
但这种方式并不实用,毕竟字符串多了就很麻烦。一种更快 更符合Python风格的方式是是使用join方法 ,我们向join方法中传入一个列表或元组:
检测子串的最佳方法是利用Python的in关键字,还可以使用index和find。
index和find会 查找指定值的首次出现的位置 。
find和index的区别是:若找不到字符串,index将会引发一个 异常 ,find则会返回 -1 :
count可以 返回指定字串的出现次数
replace用于将 指定模式替换为另一个模式 (replace will substitute occurrences of one pattern for another)
再记录几个Python内置的字符串方法吧。
startswith和endswith: 若字符串以某个前缀(后缀)开头,则返回True :
lower和uppe: 分别将字母字符转换为小写或大写 。
ljust和rjust: 用空格(或其他字符)填充字符串的空白侧以返回符合最低宽度的字符串 。
这章终于还剩两节就结束了。
-END-
python cookbook第三版学习笔记三:列表以及字符串
过滤序列元素:
有一个序列,想从其中过滤出想要的元素。最常用的办法就是列表过滤:比如下面的形式:这个表达式的意义是从1000个随机数中选出大于400的数据
test=[]
for i in range(1000):
test.append(random.randint(1,1000))
ret=[n for n in test if n >400]
根据cookbook书上的描述,这个方法适用于小数据的方式。如果数据集非常的大,而且要考虑内存的话建议使用生成器的方式ret=(n for n in test if n >400)
def filter_data(n):
start=time.time()
test=[]
for i in range(n):
test.append(random.randint(1,n))
ret=[n for n in test if n >400]
end=time.time()
print ‘Time using list iterater is %s‘ % (end-start)
start=time.time()
test=[]
for i in range(n):
test.append(random.randint(1,n))
ret=(n for n in test if n >400)
end=time.time()
print ‘Time using generater is %s‘ % (end-start)
我们先看下n=1000的运行结果:
filter_data(1000) 时间都差不多,看不出差别

N=10000的运行结果 用生成器要少于列表过滤的方法
filter_data(10000)

N=100000的运行结果 差距进一步拉大
filter_data(100000)

可以看出随着数据的扩大,确实生成器更能节省时间。
如果我们有两个列表,一个是存储信息的,一个是存储该信息的特征值的时候。我们想吧满足某种特征值的信息提取出来该如何操作呢。这里有个过滤工具itertools.compress
假设我们有下列数据,address存放的是具体的地址信息,count值对应的是各个地址信息的特征值。两者的索引是一一对应
addresses = [
‘5412 N CLARK‘,
‘5148 N CLARK‘,
‘5800 E 58TH‘,
‘2122 N CLARK‘
‘5645 N RAVENSWOOD‘,
‘1060 W ADDISON‘,
‘4801 N BROADWAY‘,
‘1039 W GRANVILLE‘,
]
counts=[0,3,10,4,1,7,6,1]
如果我们想把特征值大于5的地址信息提取出来。其实方法也比较简单,如下是没有依赖任何模块的写法,也就是通过两个列表一一判断。
for i in range(len(addresses)):
if counts[i] >= 5:
tmp.append(addresses[i])
print tmp
compress的用法如下:首先生成一个feature的列表,这个feature列表根据生成式生成一个满足条件的过滤表。然后调用compress,第一个参数是原始数据,第二个参数是过滤条件。
feature=[n>=5 for n in counts]
print feature
print list(compress(addresses,feature))
两种方法比较,如果过滤条件已经具备,那么使用compress更方便一些。否则从我个人感觉来看没有什么差别。
分割字符串:
如果我们有这样的字符串:字符全部以,为分隔符
line=‘asdf,fjdk,afed,fjek,asdf,foo‘
print line.split(‘,‘)
我们可以用字符串自带的split功能进行分割,参数携带分割符号就可以了
但是如果字符是这样的形式:
line=‘asdf fjdk;afed,fjek,asdf, foo‘
可以看到字符串的分隔符不固定,有空格 ; , ,+空格多种形式。那么单纯的用一个分隔符号就搞不定了。这个时候正则表达式就派上用场了。我们先看下正则表达式的用法。参考如下的表格
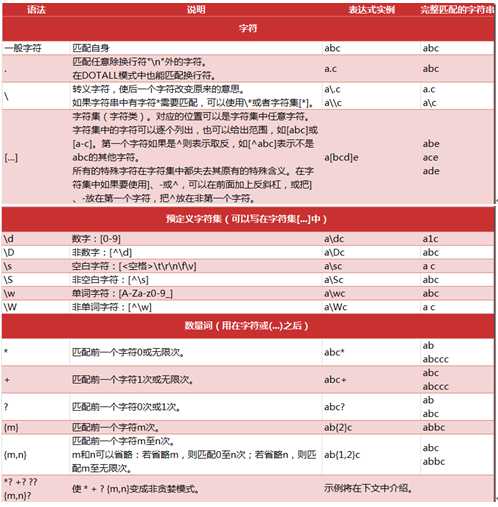
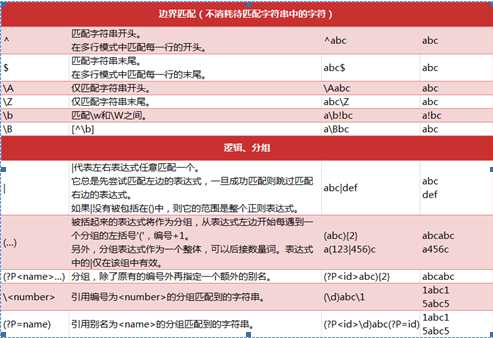
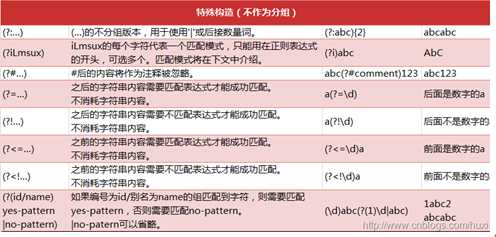
用如下的方式进行分割
print re.split(r‘[;,\\s]\\s*‘,line)
通过上面的表格可以了解到正则表达式的用法,[]是各种可能出现的符号。然后加上0个或者无限个空格。
即使我们的字符串改成如下的形式,asdf和foo之前有一个,以及多个空格。该方式也能正确的分割出字符
line=‘asdf fjdk;afed,fjek,asdf, foo‘
这里的分割方法只是将字符给分割出来了,如果我们想同时得到分隔符该如何处理呢。这里可以用到分组处理。
print re.split(r‘(;|,|\\s)\\s*‘,line)
用()分组的方式取代[],然后用|进行分割。通过前面的正则表达式可以了解到这个2个符号的用法。返回的结果如下:可以看到分割符也包含在里面了
[‘asdf‘, ‘ ‘, ‘fjdk‘, ‘;‘, ‘afed‘, ‘,‘, ‘fjek‘, ‘,‘, ‘asdf‘, ‘,‘, ‘foo‘]
如果你仍然想使用分组捕获但是不想分割符好出现,可以用(?:....)非捕获分组的形式。如下,这样的效果就和re.split(r‘[;,\\s]\\s*‘,line)的效果一致
re.split(r‘(?:,|;|\\s)\\s*‘, line)
具体的正则表达式用法可以参考<正则表达式>这本书,里面介绍得很详细。对于字符串处理来说,正则表达式可以达到事半功倍的效果。值得好好学学
以上是关于Python数据分析笔记#7.3.1 字符串对象方法的主要内容,如果未能解决你的问题,请参考以下文章