计算机视觉-自定义对象检测器
Posted w-x-me
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了计算机视觉-自定义对象检测器相关的知识,希望对你有一定的参考价值。
1、模板匹配
运行指令:python template_matching.py --source 3.jpg --template 2.jpg
import argparse import cv2 ap = argparse.ArgumentParser() ap.add_argument("-s", "--source", required=True, help="Path to the source image") ap.add_argument("-t", "--template", required=True, help="Path to the template image") args = vars(ap.parse_args()) source = cv2.imread(args["source"]) template = cv2.imread(args["template"]) (tempH, tempW) = template.shape[:2] result = cv2.matchTemplate(source, template, cv2.TM_CCOEFF) #参数1:源图像 参数2:模板图像 参数3:模板匹配方法 (minVal, maxVal, minLoc, (x, y)) = cv2.minMaxLoc(result) #获取最佳匹配的(x,y)坐标 cv2.rectangle(source, (x, y), (x + tempW, y + tempH), (0, 255, 0), 2) #在源图像上绘制边框
2、训练自己的物体探测器
作用:结合caltech101数据集,结合.mat文件,训练对象检测器,生成SVM线性支持向量机
train_detector.py
运行指令:python train_detector.py --class stop_sign_images --annotations stop_sign_annotations
from __future__ import print_function from imutils import paths from scipy.io import loadmat from skimage import io import argparse import dlib ap = argparse.ArgumentParser() ap.add_argument("-c", "--class", required=True, help="Path to the CALTECH-101 class images")#要训练一个对象检测器的具体CALTECH-101(数据集)类的路径 ap.add_argument("-a", "--annotations", required=True, help="Path to the CALTECH-101 class annotations")#指定我们正在训练的特定类的边界框的路径(caltech101数据集中对应的.mat文件夹) ap.add_argument("-o", "--output", required=True, help="Path to the output detector")#输出分类器的路径 args = vars(ap.parse_args()) print("[INFO] gathering images and bounding boxes...") options = dlib.simple_object_detector_training_options() images = [] boxes = [] for imagePath in paths.list_images(args["class"]):#循环输入需要被训练的图像 imageID = imagePath[imagePath.rfind("/") + 1:].split("_")[1] imageID = imageID.replace(".jpg", "") p = "{}/annotation_{}.mat".format(args["annotations"], imageID) annotations = loadmat(p)["box_coord"]#从路径中提取图像ID,然后使用图像ID ,从磁盘加载相应的 注释(即边界框) bb = [dlib.rectangle(left=long(x), top=long(y), right=long(w), bottom=long(h)) for (y, h, x, w) in annotations]#构 矩形 对象来表示边界框 boxes.append(bb) images.append(io.imread(imagePath))#更新边界当前图像框和添加图片到列表中,在DLIB库将需要的两个图像和函数加载到训练分类器中
test_detector.py
运行指令:python test_detector.py --detector output/stop_sign_detector.svm --testing stop_sign_testing
作用:测试自定义对象检测器效果
from imutils import paths import argparse import dlib import cv2 ap = argparse.ArgumentParser() ap.add_argument("-d", "--detector", required=True, help="Path to trained object detector")#训练出的SVM线性检测器 ap.add_argument("-t", "--testing", required=True, help="Path to directory of testing images")#包含停止标志图像进行测试的目录的路径 args = vars(ap.parse_args()) detector = dlib.simple_object_detector(args["detector"]) for testingPath in paths.list_images(args["testing"]):#循环测试需要测试的图像 image = cv2.imread(testingPath) boxes = detector(cv2.cvtColor(image, cv2.COLOR_BGR2RGB)) for b in boxes: (x, y, w, h) = (b.left(), b.top(), b.right(), b.bottom()) cv2.rectangle(image, (x, y), (w, h), (0, 255, 0), 2) cv2.imshow("Image", image) cv2.waitKey(0)
3.1、图像金字塔
目录:
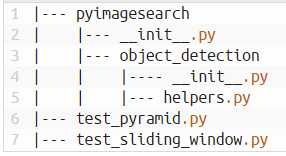
作用:指图像按一定比例缩放,并且返回。
知识点:关键字 yield 返回并不结束,理解为延迟返回结果
helper.py:
import imutils #自定义金字塔函数 def pyramid(image, scale=1.5, minSize=(30, 30)): #参数1:源图像 参数2:每次缩放比例 参数3:设置最小尺寸 yield image #定义为金字塔原图像 while True: w = int(image.shape[1] / scale) image = imutils.resize(image, width=w) #设置长宽按比例缩放 if image.shape[0] < minSize[1] or image.shape[1] < minSize[0]:#判断缩放的图片是否满足需求 break yield image #定义滑动穿口函数 def sliding_window(image, stepSize, windowSize):#参数1:要检查的对象 参数2:每次跳过多少像素,参数3:每次窗口要检查的大小
for y in xrange(0, image.shape[0], stepSize): for x in xrange(0, image.shape[1], stepSize): yield (x, y, image[y:y + windowSize[1], x:x + windowSize[0]])
test_pyramid.py
示例:python test_pyramid.py --image florida_trip.png --scale 1.5
#对金字塔函数的使用
from pyimagesearch.object_detection.helpers import pyramid import argparse import cv2 ap = argparse.ArgumentParser() ap.add_argument("-i", "--image", required=True, help="path to the input image") ap.add_argument("-s", "--scale", type=float, default=1.5, help="scale factor size") #每次图像缩小比例 args = vars(ap.parse_args()) image = cv2.imread(args["image"]) for (i, layer) in enumerate(pyramid(image, scale=args["scale"])): cv2.imshow("Layer {}".format(i + 1), layer) cv2.waitKey(0)
3.2、滑动窗户
test_sliding_window.py
作用:金字塔与滑动窗口的联合的运用
运行指令:python test_sliding_window.py --image florida_trip.png --width 64 --height 64
from pyimagesearch.object_detection.helpers import sliding_window from pyimagesearch.object_detection.helpers import pyramid import argparse import time import cv2 ap = argparse.ArgumentParser() ap.add_argument("-i", "--image", required=True, help="path to the input image")#需要处理的图像 ap.add_argument("-w", "--width", type=int, help="width of sliding window")#滑动窗口的宽度 ap.add_argument("-t", "--height", type=int, help="height of sliding window")#滑动窗口的高度 ap.add_argument("-s", "--scale", type=float, default=1.5, help="scale factor size")#图像金字塔的调整大小因子 args = vars(ap.parse_args()) image = cv2.imread(args["image"]) (winW, winH) = (args["width"], args["height"]) for layer in pyramid(image, scale=args["scale"]): for (x, y, window) in sliding_window(layer, stepSize=32, windowSize=(winW, winH)): if window.shape[0] != winH or window.shape[1] != winW: continue clone = layer.copy() cv2.rectangle(clone, (x, y), (x + winW, y + winH), (0, 255, 0), 2) cv2.imshow("Window", clone) cv2.waitKey(1) time.sleep(0.025)
4.1构建自定义检测框架的6个步骤
哈尔级联的问题(Viola-Jones探测器(2)):OpenCV中检测到面孔/人物/对象/任何东西,将花费大量时间调整cv2.detectMultiScale参数。
Viola-Jones探测器不是我们唯一的物体检测选择。我们可以使用关键点对象检测,局部不变描述符和一系列的视觉词模型。
六步框架:
步骤1:从想要检测的对象的训练数据中取样p个正样本,并从这些样本中提取HOG描述符。将提取对象的边界框(包括图像的训练数据),然后在该ROI上计算HOG特征,HOG功能将作为正面例子。
步骤2:负面训练集不包含任何要检测的对象,并从这些样品中提取HOG描述为好。实践中负面样本远远大于正样本
步骤3:在正负样本上训练线性支持向量机。
步骤4:应用硬阴极开采。对于负面训练集中的每个图像和每个图像的每个可能的比例(即图像金字塔),应用滑动窗口技术将窗口滑过图像。减少我们最终检测器中的假阳性数量。
步骤5:采取在硬阴极开采阶段发现的假阳性样本,以其置信度(即概率)进行排序,并使用这些阴性样本重新训练分类器
步骤6:分类器现在已经受过培训,可以应用于测试数据集。再次,就像在步骤4中,对于测试集中的每个图像,并且对于图像的每个比例,应用滑动窗口技术。在每个窗口中,提取HOG描述符并应用分类器。如果分类器以很大的概率检测到对象,记录窗口的边界框。完成扫描图像后,应用非最大抑制来删除冗余和重叠的边界框。
扩展和其他方法:
在物体检测中使用HOG+线性SVM方法简单易懂。与使用的标准6步框架略有不同。
第一个变化是关于HOG滑动窗口和非最大抑制方法。代替从提取特征的二者的正和负数据集,所述方法DLIB优化HOG滑动窗口使得上的错误的数目 的每个训练图像。这意味着 整个 训练图像都用于(1)提取正例,和(2) 从图像的所有其他区域提取 负样本。这完全减轻 了负面培训的需要和强烈的消极采矿的要求。这是Max-Margin Object 检测方法如此之快的原因之一 。
其次,在实际的训练阶段,dlib也考虑到非最大的压制。我们通常只应用NMS来获得最终的边界框,但在这种情况下,我们实际上可以在训练阶段使用NMS。这有助于减少误报 实质上并再次减轻了硬负开采的需要。
最后,dlib使用非常精确的算法来找到分离两个图像类的最优超平面。该方法比许多其他最先进的对象检测器获得更高的精度(具有较低的假阳性率)。
5、准备实验和培训数据
框架的完整目录结构:(pyimagesearch同级目录还有conf目录存放json文件,datasets目录,存放数据集)

实验配置:运用JSON配置文件
json配置文件优势:
1、不需要明确定义一个永无止尽的命令行参数列表,只需要提供的是我们配置文件的路径。
2、配置文件允许将所有相关参数整合到一个 位置。
3、确保我们不会忘记为每个Python脚本使用哪些命令行选项。所有选项将在我们的配置文件中定义。
4、允许我们为每个要创建的对象检测器配置一个配置文件 。这是一个巨大的优势,允许我们通过修改单个文件来定义对象检测器 。
cars.json:
{ ####### # DATASET PATHS ####### "image_dataset": "datasets/caltech101/101_ObjectCategories/car_side",#我们的“正例”图像的路径,需要训练的基础数据 "image_annotations": "datasets/caltech101/Annotations/car_side",#包含与image_dataset中每个图像相关联的边界框的目录的路径 "image_distractions": "datasets/sceneclass13",#不包含我们想要检测的对象的任何示例的“否定示例” }
explore_dims.py
作用:在caltech101数据中提取.mat文件信息,遍历所有图片轮廓信息,同时获取滑动活动窗口尺寸
涉及到知识点:1、处理caltech101数据集方法及提取.mat文件信息
2、用用golb.golb()函数遍历文件夹中的文件方法
运行指令:python explore_dims.py --conf conf/cars.json
from __future__ import print_function from pyimagesearch.utils import Conf from scipy import io import numpy as np import argparse import glob ap = argparse.ArgumentParser() ap.add_argument("-c", "--conf", required=True, help="path to the configuration file") args = vars(ap.parse_args()) conf = Conf(args["conf"])#加载配置文件 widths = []#初始化检测对象的宽度 heights = []#初始化检测对象的高度 for p in glob.glob(conf["image_annotations"] + "/*.mat"):#循环检测对象的注释文件 (y, h, x, w) = io.loadmat(p)["box_coord"][0] widths.append(w - x) heights.append(h - y)#加载每个检测对象的注释文件相关联的边界框,并更新相应的宽度和高度列表。 #计算平均宽度和高度 (avgWidth, avgHeight) = (np.mean(widths), np.mean(heights)) print("[INFO] avg. width: {:.2f}".format(avgWidth)) print("[INFO] avg. height: {:.2f}".format(avgHeight)) print("[INFO] aspect ratio: {:.2f}".format(avgWidth / avgHeight))
conf.py:解析命令行参数
作用:解析car.json文件的类
python内置函数__getitem__的作用:
在类中定义了__getitem__()方法,那么他的实例对象(假设为P)就可以这样P[key]取值。当实例对象做P[key]运算时,就会调用类中的__getitem__()方法
import commentjson as json class Conf: def __init__(self, confPath): conf = json.loads(open(confPath).read()) self.__dict__.update(conf) def __getitem__(self, k): return self.__dict__.get(k, None)
6、构建HOG描述符
cars.json:
{ ####### # DATASET PATHS ####### "image_dataset": "datasets/caltech101/101_ObjectCategories/car_side", "image_annotations": "datasets/caltech101/Annotations/car_side", "image_distractions": "datasets/sceneclass13", ####### # FEATURE EXTRACTION ####### "features_path": "output/cars/car_features.hdf5", "percent_gt_images": 0.5, "offset": 5, "use_flip": true, "num_distraction_images": 500, "num_distractions_per_image": 10, ####### # HISTOGRAM OF ORIENTED GRADIENTS DESCRIPTOR 使用的方向梯度直方图 ####### "orientations": 9, "pixels_per_cell": [4, 4], #能被滑动窗口尺寸整除 "cells_per_block": [2, 2], "normalize": true, ####### # OBJECT DETECTOR 定义滑动窗口大小 ####### "window_step": 4, "overlap_thresh": 0.3, "pyramid_scale": 1.5, "window_dim": [96, 32], "min_probability": 0.7 }
dataset.py
作用:定义h5py数据库运用的方法
涉及到知识点:1、对h5py数据库的运用
疑问:create_dataset()函数参数作用:
参数:数据库的名字,参数2:数据库维度,参数3:数据类型
扩展:h5py文件是存放两类对象的容器,数据集(dataset)和组(group),dataset类似数组类的数据集合,和numpy的数组差不多。group是像文件夹一样的容器,它好比python中的字典,有键(key)和值(value)。group中可以存放dataset或者其他的group。”键”就是组成员的名称。
import numpy as np import h5py #从磁盘上的数据集加载特征向量和标签 def dump_dataset(data,labels,path,datasetName,writeMethod="w"):#参数1:要写入HDF5数据集的特征向量列表。参数2:标签,与每个特征向量相关联的标签列表。参数3:HDF5数据集在磁盘上的存储位置。参数5:HDF5文件中数据集的名称。参数5:HDF5数据集的写入方法 db = h5py.File(path, writeMethod) dataset = db.create_dataset(datasetName, (len(data), len(data[0]) + 1), dtype="float") dataset[0:len(data)] = np.c_[labels, data] db.close() def load_dataset(path, datasetName):#加载与datasetName相关联的特征向量和标签 db = h5py.File(path, "r") (labels, data) = (db[datasetName][:, 0], db[datasetName][:, 1:]) db.close() return (data, labels)
helpers.py:
作用:返回每张图片的ROI,(最小包围矩阵)
import imutils import cv2 def crop_ct101_bb(image, bb, padding=10, dstSize=(32, 32)): (y, h, x, w) = bb (x, y) = (max(x - padding, 0), max(y - padding, 0)) roi = image[y:h + padding, x:w + padding] roi = cv2.resize(roi, dstSize, interpolation=cv2.INTER_AREA) return roi
extract_features.py:
作用:提取图片的hog特征向量,为SVC数据分类提供数据
涉及到知识点:1、运用imutils中的paths模块遍历文件
疑惑:1、 progressbar模块的作用:
创建一个进度条显示对象
widgets可选参数含义:
‘Progress: ‘ :设置进度条前显示的文字
Percentage() :显示百分比
Bar(‘#‘) : 设置进度条形状
ETA() : 显示预计剩余时间
Timer() :显示已用时间
2、HOG函数的详解
3、random.sample函数作用?
sample(seq, n) 从序列seq中选择n个随机且独立的元素;
4、random.choice函数的作用?
choice(seq) 从序列seq中返回随机的元素
random模块拓展:
1 )、random() 返回0<=n<1之间的随机实数n;
2)、getrandbits(n) 以长整型形式返回n个随机位;
3)、shuffle(seq[, random]) 原地指定seq序列;
5、sklearn.feature_extraction.image模块中extract_patches_2d函数的作用?
6)提示信息:Default value of `block_norm`==`L1` is deprecated and will be changed to `L2-Hys` in v0.15 比Py中特征少?
运行指令:python extract_features.py --conf conf/cars.json
# import the necessary packages from __future__ import print_function from sklearn.feature_extraction.image import extract_patches_2d from pyimagesearch.object_detection import helpers from pyimagesearch.descriptors import HOG from pyimagesearch.utils import dataset from pyimagesearch.utils import Conf from imutils import paths from scipy import io import numpy as np import progressbar import argparse import random import cv2 ap = argparse.ArgumentParser() ap.add_argument("-c", "--conf", required=True, help="path to the configuration file") args = vars(ap.parse_args()) conf = Conf(args["conf"])#加载配置文件 #调用函数初始化HOG描述符 hog = HOG(orientations=conf["orientations"], pixelsPerCell=tuple(conf["pixels_per_cell"]), cellsPerBlock=tuple(conf["cells_per_block"]), normalize=conf["normalize"]) data = [] labels = [] #随机抽取车测试图 trnPaths = list(paths.list_images(conf["image_dataset"])) trnPaths = random.sample(trnPaths, int(len(trnPaths) * conf["percent_gt_images"])) print("[INFO] describing training ROIs...") widgets = ["Extracting: ", progressbar.Percentage(), " ", progressbar.Bar(), " ", progressbar.ETA()] pbar = progressbar.ProgressBar(maxval=len(trnPaths), widgets=widgets).start() #训练每个图像 for (i, trnPath) in enumerate(trnPaths): image = cv2.imread(trnPath) image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) imageID = trnPath[trnPath.rfind("_") + 1:].replace(".jpg", "")#提取文件名 p = "{}/annotation_{}.mat".format(conf["image_annotations"], imageID) bb = io.loadmat(p)["box_coord"][0] roi = helpers.crop_ct101_bb(image, bb, padding=conf["offset"], dstSize=tuple(conf["window_dim"])) #确定我们是否应该使用ROI的水平翻转作为额外的训练数据 rois = (roi, cv2.flip(roi, 1)) if conf["use_flip"] else (roi,) #中提取HOG特征,并更新 数据 和 标签 列表 for roi in rois: features = hog.describe(roi) data.append(features) labels.append(1) pbar.update(i) dstPaths = list(paths.list_images(conf["image_distractions"])) pbar = progressbar.ProgressBar(maxval=conf["num_distraction_images"], widgets=widgets).start() print("[INFO] describing distraction ROIs...") #训练负图像样本 for i in np.arange(0, conf["num_distraction_images"]): image = cv2.imread(random.choice(dstPaths)) image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) patches = extract_patches_2d(image, tuple(conf["window_dim"]), max_patches=conf["num_distractions_per_image"]) for patch in patches: features = hog.describe(patch) data.append(features) labels.append(-1) pbar.update(i) pbar.finish() print("[INFO] dumping features and labels to file...") dataset.dump_dataset(data, labels, conf["features_path"], "features")
7、初始训练阶段
car.json:
{ ####### # DATASET PATHS ####### "image_dataset": "datasets/caltech101/101_ObjectCategories/car_side", "image_annotations": "datasets/caltech101/Annotations/car_side", "image_distractions": "datasets/sceneclass13", ####### # FEATURE EXTRACTION ####### "features_path": "output/cars/car_features.hdf5", "percent_gt_images": 0.5, "offset": 5, "use_flip": true, "num_distraction_images": 500, "num_distractions_per_image": 10, ####### # HISTOGRAM OF ORIENTED GRADIENTS DESCRIPTOR ####### "orientations": 9, "pixels_per_cell": [4, 4], "cells_per_block": [2, 2], "normalize": true, ####### # OBJECT DETECTOR ####### "window_step": 4, "overlap_thresh": 0.3, "pyramid_scale": 1.5, "window_dim": [96, 32], "min_probability": 0.7, ####### # LINEAR SVM ####### "classifier_path": "output/cars/model.cpickle",#分类器被储存的位置 "C": 0.01, }
train_model.py
作用:对获取的图像hog特征向量,运用SVC线性分类处理
疑问:1、sklearn函数模块详解?
2、args["hard_negatives"]参数作用?
3、numpy.stack()函数作业用:
改变列表数据维度
参数1:列表数据,参数2:设置列表维度
4、numpy.hstack()函数作用
水平(按列顺序)把数组给堆叠起来,vstack()函数正好和它相反
参数tup可以是元组,列表,或者numpy数组,返回结果为numpy的数组。
运行指令:python train_model.py --conf conf/cars.json
from __future__ import print_function from pyimagesearch.utils import dataset from pyimagesearch.utils import Conf from sklearn.svm import SVC import numpy as np import argparse import cPickle ap = argparse.ArgumentParser() ap.add_argument("-c", "--conf", required=True, help="path to the configuration file") ap.add_argument("-n", "--hard-negatives", type=int, default=-1, help="flag indicating whether or not hard negatives should be used") args = vars(ap.parse_args()) print("[INFO] loading dataset...") conf = Conf(args["conf"]) (data, labels) = dataset.load_dataset(conf["features_path"], "features")#抓取提取的特征向量和标签 if args["hard_negatives"] > 0: print("[INFO] loading hard negatives...") (hardData, hardLabels) = dataset.load_dataset(conf["features_path"], "hard_negatives") data = np.vstack([data, hardData]) labels = np.hstack([labels, hardLabels]) print("[INFO] training classifier...") model = SVC(kernel="linear", C=conf["C"], probability=True, random_state=42) model.fit(data, labels) print("[INFO] dumping classifier...") f = open(conf["classifier_path"], "w") f.write(cPickle.dumps(model))#将分类器转储成档 f.close()
objectdetector.py:
作用:经过滑动窗口和金字塔处理后的图像,提取符合概率的轮廓列表。
疑惑:改变概率参数,符合要求的轮廓数量没有发生改变?
pyramid函数(3.1)、sliding_window函数(3.2)写到helpers.py中
iimport helpers class ObjectDetector: def __init__(self, model, desc): self.model = model self.desc = desc def detect(self, image, winDim, winStep=4, pyramidScale=1.5, minProb=0.7):#image:需要检测的图像,winDim:滑动窗口尺寸大小 boxes = [] probs = [] for layer in helpers.pyramid(image, scale=pyramidScale, minSize=winDim):#循环金子塔中的图像 scale = image.shape[0] / float(layer.shape[0]) for (x, y, window) in helpers.sliding_window(layer, winStep, winDim): (winH, winW) = window.shape[:2] if winH == winDim[1] and winW == winDim[0]: features = self.desc.describe(window).reshape(1, -1) prob = self.model.predict_proba(features)[0][1] if prob > minProb: (startX, startY) = (int(scale * x), int(scale * y)) endX = int(startX + (scale * winW)) endY = int(startY + (scale * winH)) boxes.append((startX, startY, endX, endY)) probs.append(prob) return (boxes, probs)
test_model_no_nms.py(与pyimagesearch同级目录下)
作用:测试通过轮廓列表寻找到轮廓是否正确
疑问:
1、sklearn.svm模块中SVC的详解
参数解释链接:https://blog.csdn.net/szlcw1/article/details/52336824
2、提示错误信息:Default value of `block_norm`==`L1` is deprecated and will be changed to `L2-Hys` in v0.15
运行指令:python test_model_no_nms.py --conf conf/cars.json--image datasets/caltech101/101_ObjectCategories/car_side/image_0004.jpg
from pyimagesearch.object_detection import ObjectDetector from pyimagesearch.descriptors import HOG from pyimagesearch.utils import Conf import imutils import argparse import cPickle import cv2 ap = argparse.ArgumentParser() ap.add_argument("-c", "--conf", required=True, help="path to the configuration file") ap.add_argument("-i", "--image", required=True, help="path to the image to be classified") args = vars(ap.parse_args()) conf = Conf(args["conf"]) model = cPickle.loads(open(conf["classifier_path"]).read()) #SVC线性值 hog = HOG(orientations=conf["orientations"], pixelsPerCell=tuple(conf["pixels_per_cell"]), cellsPerBlock=tuple(conf["cells_per_block"]), normalize=conf["normalize"]) #hog特征向量值提取方法 od = ObjectDetector(model, hog) image = cv2.imread(args["image"]) image = imutils.resize(image, width=min(260, image.shape[1])) gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) (boxes, probs) = od.detect(gray, conf["window_dim"], winStep=conf["window_step"], pyramidScale=conf["pyramid_scale"], minProb=conf["min_probability"]) for (startX, startY, endX, endY) in boxes: cv2.rectangle(image, (startX, startY), (endX, endY), (0, 0, 255), 2) cv2.imshow("Image", image) cv2.waitKey(0)
问题1:修改感兴趣概率,获取的敏感区域一样?
8、非最大抑制
作用:解决重叠边界框,寻找到最佳匹配轮廓
nms.py(object_detection目录下):
疑问:1、numpy模块中argsort()函数的作用:
获取数组从小到的大索引值
2、numpy模块中concatenate()函数作用:
对数组进行拼接
3、while里面对idx的处理逻辑?语法规则?
讲解示例:https://blog.csdn.net/scut_salmon/article/details/79318387
nms.py
import numpy as np def non_max_suppression(boxes, probs, overlapThresh):#参数1:边界框列表,参数2:每个框相关的概率,参数3:重叠的阀值 if len(boxes) == 0:#判断边界框列表是否为空 return [] if boxes.dtype.kind == "i": boxes = boxes.astype("float")#将边界框数据由整型转换成浮点型 #获取边界框每个角的坐标 pick = [] x1 = boxes[:, 0] y1 = boxes[:, 1] x2 = boxes[:, 2] y2 = boxes[:, 3] #获取边界框的面积 area = (x2 - x1 + 1) * (y2 - y1 + 1) idxs = np.argsort(probs) #获取列表的长度,并将其保留在边框列表中 while len(idxs) > 0: last = len(idxs) - 1 i = idxs[last] pick.append(i) #获取边最大坐标的界框和最小的坐标边界宽 xx1 = np.maximum(x1[i], x1[idxs[:last]]) yy1 = np.maximum(y1[i], y1[idxs[:last]]) xx2 = np.minimum(x2[i], x2[idxs[:last]]) yy2 = np.minimum(y2[i], y2[idxs[:last]]) w = np.maximum(0, xx2 - xx1 + 1) h = np.maximum(0, yy2 - yy1 + 1) # 计算重叠比例 overlap = (w * h) / area[idxs[:last]] idxs = np.delete(idxs, np.concatenate(([last], np.where(overlap > overlapThresh)[0]))) return boxes[pick].astype("int")
test_model.py(与pyimagesearch目录同级):
作用:测试解决重叠轮廓的边界效果
运行指令:python test_model.py --conf conf/cars.json--image datasets/caltech101/101_ObjectCategories/car_side/image_0004.jpg
from pyimagesearch.object_detection import non_max_suppression from pyimagesearch.object_detection import ObjectDetector from pyimagesearch.descriptors import HOG from pyimagesearch.utils import Conf import numpy as np import imutils import argparse import cPickle import cv2 ap = argparse.ArgumentParser() ap.add_argument("-c", "--conf", required=True, help="path to the configuration file") ap.add_argument("-i", "--image", required=True, help="path to the image to be classified") args = vars(ap.parse_args()) conf = Conf(args["conf"]) model = cPickle.loads(open(conf["classifier_path"]).read()) hog = HOG(orientations=conf["orientations"], pixelsPerCell=tuple(conf["pixels_per_cell"]), cellsPerBlock=tuple(conf["cells_per_block"]), normalize=conf["normalize"]) od = ObjectDetector(model, hog) image = cv2.imread(args["image"]) image = imutils.resize(image, width=min(260, image.shape[1])) gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) (boxes, probs) = od.detect(gray, conf["window_dim"], winStep=conf["window_step"], pyramidScale=conf["pyramid_scale"], minProb=conf["min_probability"]) pick = non_max_suppression(np.array(boxes), probs, conf["overlap_thresh"]) orig = image.copy() for (startX, startY, endX, endY) in boxes: cv2.rectangle(orig, (startX, startY), (endX, endY), (0, 0, 255), 2) for (startX, startY, endX, endY) in pick: cv2.rectangle(image, (startX, startY), (endX, endY), (0, 255, 0), 2) cv2.imshow("Original", orig) cv2.imshow("Image", image) cv2.waitKey(0)
9、坚硬的负面特征采集
作用:训练与需要提取的特征完全不相关的特征,一般是物体的背面场景,所以一般应用sceneclass13数据集,训练负面特征变量,减少误判情况。将负面数据也写入h5py数据库中。
运行指令:python hard_negative_mine.py --conf conf/cars.json
hard_negative_mine.py
from __future__ import print_function from pyimagesearch.object_detection.objectdetector import ObjectDetector from pyimagesearch.descriptors.hog import HOG from pyimagesearch.utils import dataset from pyimagesearch.utils.conf import Conf from imutils import paths import numpy as np import progressbar import argparse import cPickle import random import cv2 ap = argparse.ArgumentParser() ap.add_argument("-c", "--conf", required = True, help = "path to the configuration file") args = vars(ap.parse_args()) conf =Conf(args["conf"]) data =[] model =cPickle.loads(open(conf["classifier_path"]).read()) hog =HOG(orientations = conf["orientations"], pixelsPerCell = tuple(conf["pixels_per_cell"]), cellsPerBlock = tuple(conf["cells_per_block"]), normalize = conf["normalize"]) od = ObjectDetector(model, hog) dstPaths = list(paths.list_images(conf["image_distractions"])) dstPaths =random.sample(dstPaths, conf["hn_num_distraction_images"]) widgets = ["Mining:", progressbar.Percentage(), " ", progressbar.Bar(), "", progressbar.ETA()] pbar = progressbar.ProgressBar(maxval = len(dstPaths), widgets = widgets).start() myindex = 0 for (i, imagePath) in enumerate(dstPaths): image = cv2.imread(imagePath) gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) (boxes, probs) = od.detect(gray, conf["window_dim"], winStep = conf["hn_window_step"], pyramidScale = conf["hn_pyramid_scale"], minProb = conf["hn_min_probability"]) for (prob, (startX, startY, endX, endY)) in zip(probs, boxes): roi = cv2.resize(gray[startY:endY, startX:endX], tuple(conf["window_dim"]), interpolation = cv2.INTER_AREA) features = hog.describe(roi) data.append(np.hstack([[prob], features])) pbar.update(i) pbar.finish() print("[INFO] sorting by probability...") data = np.array(data) data = data[data[:, 0].argsort()[::-1]] print("[INFO] dmping hard negatives to file...") dataset.dump_dataset(data[:, 1:], [-1] * len(data), conf["features_path"], "hard_negatives", writeMethod = "a")
10、重新训练对象检测器
作用:将坚硬的负面特征加入到SVM中,减少虚假轮廓的出现
运行指令:python train_model.py --conf conf/cars.json --hard-negatives 1
train_model.py
from __future__ import print_function from pyimagesearch.utils import dataset from pyimagesearch.utils.conf import Conf from sklearn.svm import SVC import argparse import pickle import numpy as np ap = argparse.ArgumentParser() ap.add_argument("-c", "--conf", required = True, help = "path to the configuration file") ap.add_argument("-n", "--hard-negatives", type = int, default = -1, help="flag indicating whether or not hard negatives should be used") args = vars(ap.parse_args()) print("[INFO] loading dataset...") conf = Conf(args["conf"]) (data, labels) = dataset.load_dataset(conf["features_path"], "features") if args["hard_negatives"] > 0: print("[INFO] loading hard negatives...") (hardData,hardLabels) = dataset.load_dataset(conf["features_path"], "hard_negatives") data = np.vstack([data, hardData]) labels = np.hstack([labels, hardLabels]) print("[INFO] training classifier...") model = SVC(kernel = "linear", C = conf["C"], probability = True, random_state = 42) model.fit(data, labels) print("[INFO] dumping classifier...") f = open(conf["classifier_path"], "wb") f.write(pickle.dumps(model)) f.close()
11、imglab的运用
前期准备工作:生成xml文件,运用imglab生成器,选取特征轮廓。
步骤1:imglab -c 文件夹路径 生成xml文件路径 步骤2:imglab xml文件 手动框选特征区域
作用:将提取图片的边界框,并且将其特征运用svm分类。
运行指令:python train_detector.py --xml face_detector/faces_annotations.xml --detector face_detector/detector.svm
from __future__ import print_function import argparse import dlib ap = argparse.ArgumentParser() ap.add_argument("-x", "--xml", required = True, help = "path to input XML file") ap.add_argument("-d", "--detector", required = True, help = "path to output director") args = vars(ap.parse_args()) print("[INFO] training detector....") options = dlib.simple_object_detector_training_options() options.C = 1.0 options.num_threads = 4 options.bei_verbose = True dlib.train_simple_object_detector(args["xml"], args["detector"], options) print("[INFO] training accuracy:{}".format(dlib.test_simple_object_detector(args["xml"], args["detector"]))) detector = dlib.simple_object_detector(args["detector"]) win = dlib.image_window() win.set_image(detector) dlib.hit_enter_to_continue()
test_detector.py
作用:测试训练出来SVM线性向量
运行指令:python test_detector.py --detector face_detector/detector.svm--testing face_detector/testing
from imutils import paths import argparse import dlib import cv2 ap = argparse.ArgumentParser() ap.add_argument("-d", "--detector", required = True, help = "Path to train object detector") ap.add_argument("-t", "--testing", required = True, help = "Path to directory of testing images") args = vars(ap.parse_args()) detector = dlib.simple_object_detector(args["detector"]) for testingPath in paths.list_images(args["testing"]): image = cv2.imread(testingPath) boxes = detector(cv2.cvtColor(image, cv2.COLOR_BGR2RGB)) for b in boxes: (x, y, w, h) = (b.left(), b.top(), b.right(), b.bottom()) cv2.rectangle(image, (x, y), (w, h), (0, 255, 0), 2)
以上是关于计算机视觉-自定义对象检测器的主要内容,如果未能解决你的问题,请参考以下文章