paper reading----Xception: Deep Learning with Depthwise Separable Convolutions
Posted qingliu411
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了paper reading----Xception: Deep Learning with Depthwise Separable Convolutions相关的知识,希望对你有一定的参考价值。
背景以及问题描述:
Inception-style models的基本单元是Inception module。Inception model是Inception module堆砌而成,这与VGG-style network这种由简单的conv layer堆砌而成的网络不一样。虽然Inception modules在概念上还是卷积,用于卷积特征的提取,能够利用更少的参数来学习更加richer的表达。那么他们到底是怎么做到的呢?他们与regular convolution有什么不同呢?Inception之后应该跟那些strategies呢?
Inception Hypothesis:
卷积层学习的是3D空间中的filters,两个spatial dimension,一个channel dimension。single filter kernel既要mapping cross-channel correlations,又要mapping spatial correlation。Inception背后的想法是将这个过程简化,使之更有效,采取的策略是,对cross-channel correlation mapping和spatial correlation mapping进行分离,首先通过1*1的conv探索cross-channel correlation,然后把数据在channel这个维度上进行划分,分成三四个segment,对每个segment单独进行3*3的卷积操作,来同时探索spatial correlation和cross-channel correlation。这样能够减少参数的个数,同时能够对corss-channel correlation和spatial correlation进行有效的decouple。
Regular Conv和Separable Conv之中
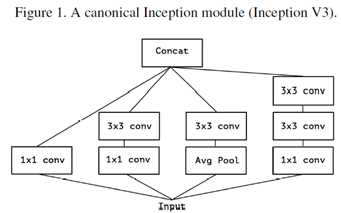
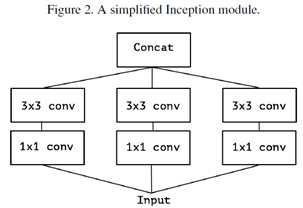
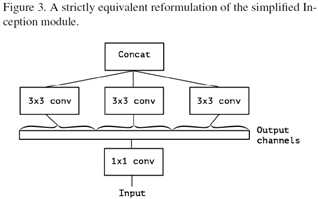
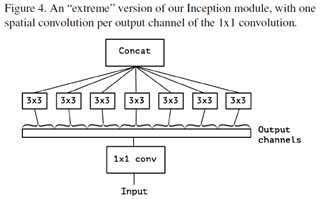
Inception module有不同的形式,考虑Inception V3中的典型的形式如图1,去掉avgpooling后,可简化为图2的形式。简化形式完全等价于图3的形式, 图3的一个极端形式(extreme inception, i.e. Xception)如图4所示。值得注意的是,图4几乎与depthwise separable conv identical。差别在于:
l 操作顺序有区别:depthwise separable conv 通常先执行channel-wise spatial conv,然后再执行1*1的卷积;而Inception则是先执行1*1的卷积;
l 第一个操作后有无ReLU. Inception中两个卷积操作后均有ReLU; 而channel-waise separable conv在第一个操作后没ReLU。
作者认为第一个差别并不重要,第二个差异可能是关键。而且作者认为在regular conv与depthwise separable conv之间存在一个discrete spectrum,parameterized by 用于执行spatial convolution的独立的channel-space segments。regular conv(先于1*1convolution)对应于所有的channel捆在一起当成一个segment的情况;depthwise separable conv是一个channel对应一个segment的情况,这两类情况属于两个极端,而Inception位于两者之间,将channels分成少数几个segments,然后分别进行卷积。这种中间状态的属性至今没有被探索过。
基于这个观察,可以认为用depthwise separable conv替换Inception Module可能会对Inception family of architectures有提升。本文的主要工作就是present a CNN architecture based on this idea.
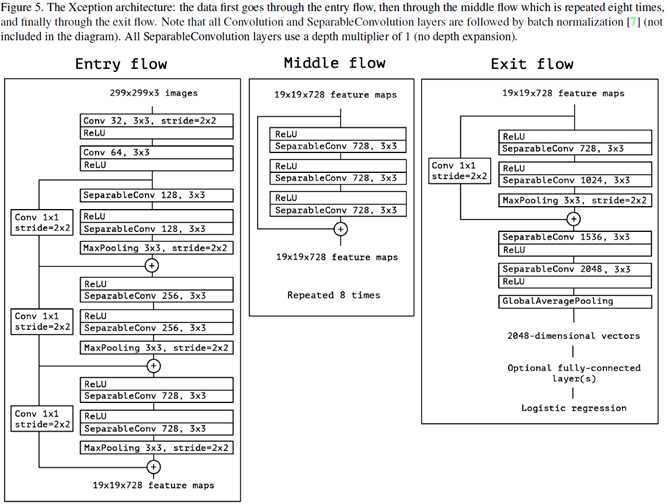
The Xception architecture
一言以蔽之,一个用depthwise separable conv堆砌的,加了residual connection的architecture. 如图5所示。coding: https://github.com/kwotsin/TensorFlow-Xception
实验设置:
Dropout: ImageNet上训练的时候,在logistic regression之前包含一个dropout layer,rate=0.5,但是在JFT数据集(包含350million个图像)上,没有dropout,理由是 数据集很大,in any reasonable amount of time下,不可能overfitting,事实上,这么大的数据集,在60 NVIDIA K80 GPUs这样的硬件条件下,要把网络训练到full convergence, 需要三个多月的时间了,本文才训练了一个月,当然不可能overfitting.
以上是关于paper reading----Xception: Deep Learning with Depthwise Separable Convolutions的主要内容,如果未能解决你的问题,请参考以下文章