分页原理浅析
Posted tele-share
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分页原理浅析相关的知识,希望对你有一定的参考价值。
1.关于分页
只讨论分页,即显示数据,不做任何过滤(搜索)和排序,仅仅是显示数据
1.1hibernate的分页
mysql用limit来作分页,核心参数有两个,start与size,即开始的位置与每页显示的数量,但是我们在用hibernate时发现使用他提供的
setFirstResult((page-1)*pageSize).setMaxResults(pageSize)也可以完成分页
解释下page和pageSize,page表示当前页,也就是当前是第多少页,pageSize依然表示本页的数据量
page与start的关系为start=(page-1)*pageSize,以每页2条数据为例,
select * from table limit 0,2 ---->第一页数据是 1,2 start=0,page=1
select * from table limit 2,2 ---->第二页数据是 3,4 start=2,page=2
select * from table limit 4,2 ---->第三页数据是 5,6 start=4,page=3
.....
setFirstResult() -->从哪开始查
setMaxResults() -->查多少
1.2 实际使用
1.2.1 以jquery DataTable分页为例
真正开发的时候我们显示数据的时候,往往使用各种分页插件,他们的分页略有不同,但原理都是一样的,即通过点击页码,触发ajax,发送当前页码(page)以及本页要显示的数据量(pageSize)给
后台处理,以jquery DataTable为例, 其发送给后台的参数就有start,代表第一条数据的起始位置比如 0代表第一条数据,当然还有length,但是你可能会见到这种写法,这种写法是公式的反推:page=(start / length) +1,先利用DataTable的ajax向servlet发送请求,发送的信息如下图
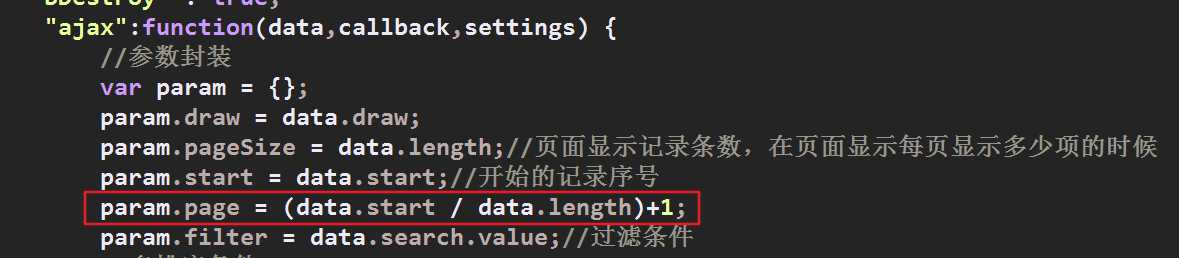
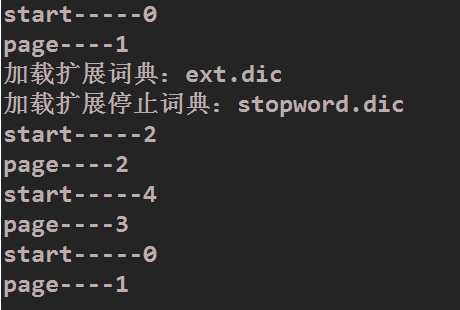
事实上没有必要再去计算出page,因为DataTable主动提供了start参数,这里通过打印的形式来再次证明start与page的关系,(每页显示数据设置为2) 与我们上面1.1所写的相互对照,发现打印的结果没什么问题
具体使用请参考https://www.cnblogs.com/tele-share/p/8667434.html
1.2.2 以bootstrap-paginator为例
然而大多数情况下,分页插件不会直接提供start,只会提供page参数(因为对于一个插件来说,告诉你现在是第几页更加直接明了),比如bootstrap-paginator,这个时候你可以现在前台计算出start然后传递start和size或者传递page和size,在后台进行计算
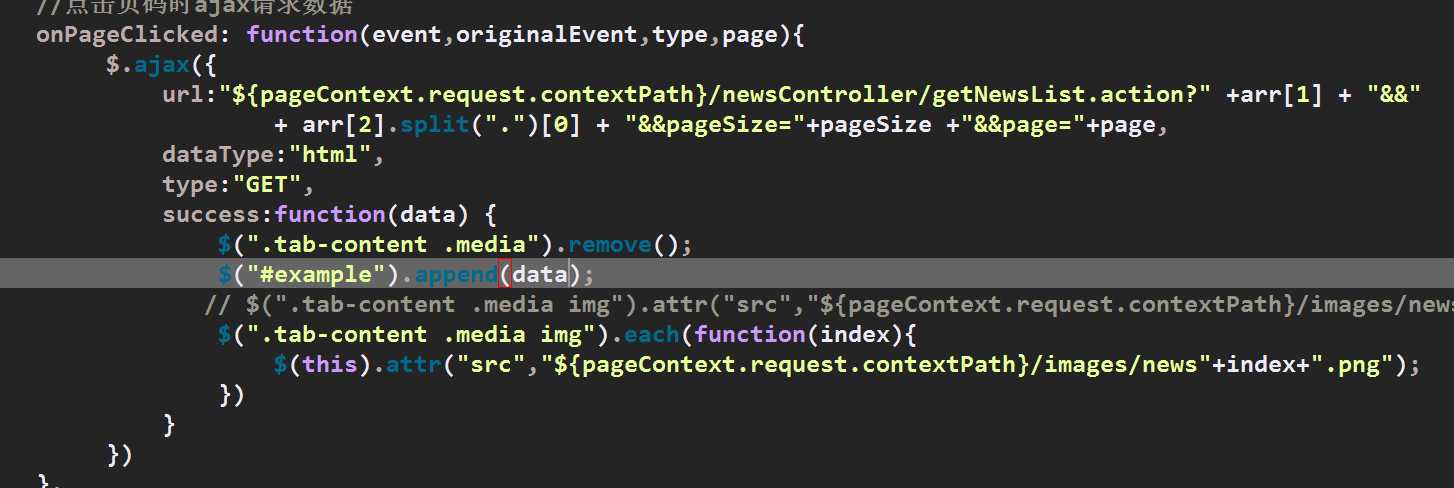
(事实上在使用bootstrap-paginator的时候你需要两次ajax,第一次查询数据量,第二次才是显示数据)
具体使用请参考http://www.cnblogs.com/tele-share/p/8982910.html
通过上面的分析我们可以发现分页的核心参数是start和size,page,但是仅仅有这两个参数显然还不够
1.2.3封装Page类(显示用的DataTable)
当你使用分页插件的时候,不可避免的要去显示""共计有多少条记录","共计多少页",此外你必须告诉你的分页插件,你的数据总量,总页数以及你每次查询到的本页的结果集,用户输入的关键词在切换到下一页
时是要仍然需要显示在搜索框中,经过以上的分析我们发现这个时候封装一个Page类就很有必要了(当然不封装也可以),这个page类通常包括这些属性:总页数,总页码,当前页,每页显示数据,关键词,搜索的域
以及查询到的结果集.
1 /*
2 * 分页对象
3 *
4 */
5 public class Page<T> {
6 private Integer pageSize;//每页显示条数
7 private Integer page;//当前页
8 private Integer pageTotal;//总页数----->用于显示当前共多少页
9 private Integer recordsTotal;//总记录数----->显示当前共有多少条记录
10 private String keywords;//关键字 假设只有一个
11 private String[] fields;
12 private List<T> list = new ArrayList<T>();
13
14 public Integer getPageTotal() {
15 return pageTotal;
16 }
17 public void setPageTotal(Integer pageTotal) {
18 this.pageTotal = pageTotal;
19 }
20 public Integer getRecordsTotal() {
21 return recordsTotal;
22 }
23 public void setRecordsTotal(Integer recordsTotal) {
24 this.recordsTotal = recordsTotal;
25 }
26 public List<T> getList() {
27 return list;
28 }
29 public void setList(List<T> list) {
30 this.list = list;
31 }
32 public Integer getPageSize() {
33 return pageSize;
34 }
35 public void setPageSize(Integer pageSize) {
36 this.pageSize = pageSize;
37 }
38 public Integer getPage() {
39 return page;
40 }
41 public void setPage(Integer page) {
42 this.page = page;
43 }
44 public String getKeywords() {
45 return keywords;
46 }
47 public void setKeywords(String keywords) {
48 this.keywords = keywords;
49 }
50 public String[] getFields() {
51 return fields;
52 }
53 public void setFields(String[] fields) {
54 this.fields = fields;
55 }
56 }
在servlet中要接收page,pageSize,keywords(关键字),fields(搜索域),这二者构成了查询条件,接下来首先要根据关键字和域对象去查询总量,得到总数据量后要来计算总页数
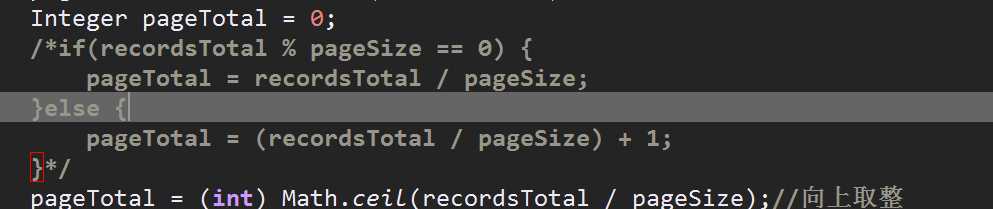
总页数可以用Math中的ceil()方法来计算,当热if else也可以
1 //封装page对象
2 @Override
3 public <T> Page<T> getPage(String keywords, String[] fields, Class clazz, int page, int pageSize) {
4 Page<T> pageBean = new Page<T>();
5 pageBean.setKeywords(keywords);
6 pageBean.setFields(fields);
7 pageBean.setPageSize(pageSize);
8 pageBean.setPage(page);
9 int start = (page-1)*pageSize;
10 List list = this.Page(keywords, fields, clazz,start,pageSize);//查询的每页的结果集
11 pageBean.setList(list);
12 Integer recordsTotal = bookDao.getCount(keywords, fields);
13 pageBean.setRecordsTotal(recordsTotal);
14 Integer pageTotal = 0;
15 /*if(recordsTotal % pageSize == 0) {
16 pageTotal = recordsTotal / pageSize;
17 }else {
18 pageTotal = (recordsTotal / pageSize) + 1;
19 }*/
20 pageTotal = (int) Math.ceil(recordsTotal / pageSize);//向上取整
21 pageBean.setPageTotal(pageTotal);
22 return pageBean;
23 }
如果你是从数据库取数据的话到这个地方难点已经解决完了,因为这些分页参数你都有了,接下来只要传参数给数据库就好了,但如果你没有使用数据库,你的数据是采集到本地磁盘上,然后用lucene建立索引库查询的话,你还要自己实现底层的分页方法,底层的分页处理,应当是遍历查询出的结果集然后封装每一页的数据,以下是伪代码
1 List list = new ArrayList();
2 List<Document> docList = search(query);//docList是查询的总数据集
3 int end = Math.min(start+size,docList.size());//也可以用if else判断
4 for(int i=start;i<end;i++){
5 Document document = docList.get(i);
6 Object object = document2javabean(document, clazz);
7 list.add(object);
8 }
这样做完之后,这个list里面就是每一页的数据了
总结:
1.封装page类有时并不是很必要,里面的一些属性,也是看情况添加,但只要你封装Page对象,那么page和pageSize这两个属性少不了的
2.分页插件多种多样,各种参数眼花缭乱,但一些参数很固定,如总数据量,总页数,当前页,每页数据量等,把这些参数处理好,分页基本就ok了
以上是关于分页原理浅析的主要内容,如果未能解决你的问题,请参考以下文章