elasticsearch 跨索引联合多条件查询
Posted 鱼找水需要时间
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了elasticsearch 跨索引联合多条件查询相关的知识,希望对你有一定的参考价值。
文章目录

Elasticsearch
Elasticsearch 是一个免费且开放的分布式搜索和分析引擎。适用于包括文本、数字、地理空间、结构化和非结构化数据等在内的所有类型的数据。Elasticsearch 在 Apache Lucene 的基础上开发而成,以其简单的 REST 风格 API、分布式特性、速度和可扩展性而闻名,是 Elastic Stack 的核心组件;Elastic Stack 是一套适用于数据采集、扩充、存储、分析和可视化的免费开源工具。人们通常将 Elastic Stack 称为 ELK Stack(代指 Elasticsearch、Logstash 和 Kibana),目前 Elastic Stack 包括一系列丰富的轻量型数据采集代理,这些代理统称为 Beats,可用来向 Elasticsearch 发送数据。
Elasticsearch 用来收集大量日志和检索文本是个不错的选择,可以在承载了 PB 级数据的成百上千台服务器上运行。
关键字:
- 实时
- 分布式
- 搜索
- 分析
需求
如果既要对一些字段进行分词查询,同时要对另一些字段进行精确查询,就需要使用布尔查询来实现了。同时索引是按照一定规则建立的,例如按照时间段,此时查询的时候会涉及到联合索引查询。布尔查询对应于Lucene的BooleanQuery查询,实现将多个查询组合起来,有三个可选的参数:
must: 文档必须匹配must所包括的查询条件,相当于 “AND”
should: 文档应该匹配should所包括的查询条件其中的一个或多个,相当于 “OR”
must_not: 文档不能匹配must_not所包括的该查询条件,相当于“NOT”
使用版本
elasticsearch:7.1.1
spring-boot-starter-data-elasticsearch:2.5.4
联合索引多条件查询示例
@Autowired
private RestHighLevelClient client;
ObjectMapper mapper = new ObjectMapper();
@Override
public Page<Book> search(Pageable pageable, Set<String> indexNameList)
BoolQueryBuilder queryBuilder = QueryBuilders.boolQuery();
//must中的条件,必须全部匹配。需要将字段的type设置为keyword 或者 指定字段时用 `字段.keyword`(实际测试并不生效,可能还和analyzer有关)
queryBuilder.must(QueryBuilders.termQuery("title", "杨"));
//匹配should中的条件(匹配1个或多个,根据需求配置)
queryBuilder.should(QueryBuilders.termQuery("address", "山西"));
//matchPhraseQuery 通配符搜索查询,支持 * 和 ?, ?匹配任意单个字符,这么查询可能慢
queryBuilder.must(QueryBuilders.matchPhraseQuery("remark", "*" + "你好" + "*"));
//必须匹配的 should条件数量
queryBuilder.minimumShouldMatch(1);
//数据集合
List<Book> hits = new ArrayList<>();
//总数
long total = 0L;
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder()
.query(queryBuilder)
.from(pageable.getPageNumber())
.size(pageable.getPageSize());
//es中存在的索引
List<String> arrayList = getExistIndex(indexNameList);
SearchRequest searchRequest = new SearchRequest(indexArray).source(searchSourceBuilder);
try
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
// 搜索结果
org.elasticsearch.search.SearchHits searchHits = searchResponse.getHits();
// 匹配到的总记录数
total = searchHits.getTotalHits().value;
org.elasticsearch.search.SearchHit[] searchHitsHits = searchHits.getHits();
for (SearchHit searchHitsHit : searchHitsHits)
//如果es中字段比定义的实体类中多,反序列化会提示异常,需要加以下注解
//忽略无法识别的属性:@JsonIgnoreProperties(ignoreUnknown = true)
Book book = mapper.readValue(searchHitsHit.getSourceRef().utf8ToString(), Book.class);
hits.add(book);
catch (IOException e)
e.printStackTrace();
//检测每个索引是否存在,只返回存在的索引
private List<String> getExistIndex(Set<String> indexNameList)
List<String> existsIndex = new ArrayList<>();
for (String indexName : indexNameList)
try
GetIndexRequest existsRequest = new GetIndexRequest();
existsRequest.indices(indexName);
boolean exists = client.indices().exists(existsRequest, RequestOptions.DEFAULT);
//返回索引集合中存在的索引,避免传入不存在的索引,导致查询异常
if (exists)
existsIndex.add(indexName);
catch (Exception e)
return existsIndex;
相关API
//查看索引结构
GET : http://127.0.0.1:9200/索引/_mapping
相关资料
https://blog.csdn.net/u011821334/article/details/100979286
https://www.cnblogs.com/coderxz/p/13268417.html
https://www.cnblogs.com/keatsCoder/p/11341835.html
https://blog.csdn.net/weixin_43847283/article/details/123616890
https://blog.csdn.net/weixin_43847283/article/details/123933244
超详细Postman 操作 ElasticSearch笔记梳理
文章目录
前言
该技术博客基于Postman工具操作ES,因为ES支持Restful风格
该技术博客阅读还是需要一定的门槛,首先我们需要明白ES中索引、文档等常见名词所代表的意思。
而且还需要掌握Postman工具的基本操作。
如果你已经启动ElasticSearch和Postman,那我们就可以开始学习了!
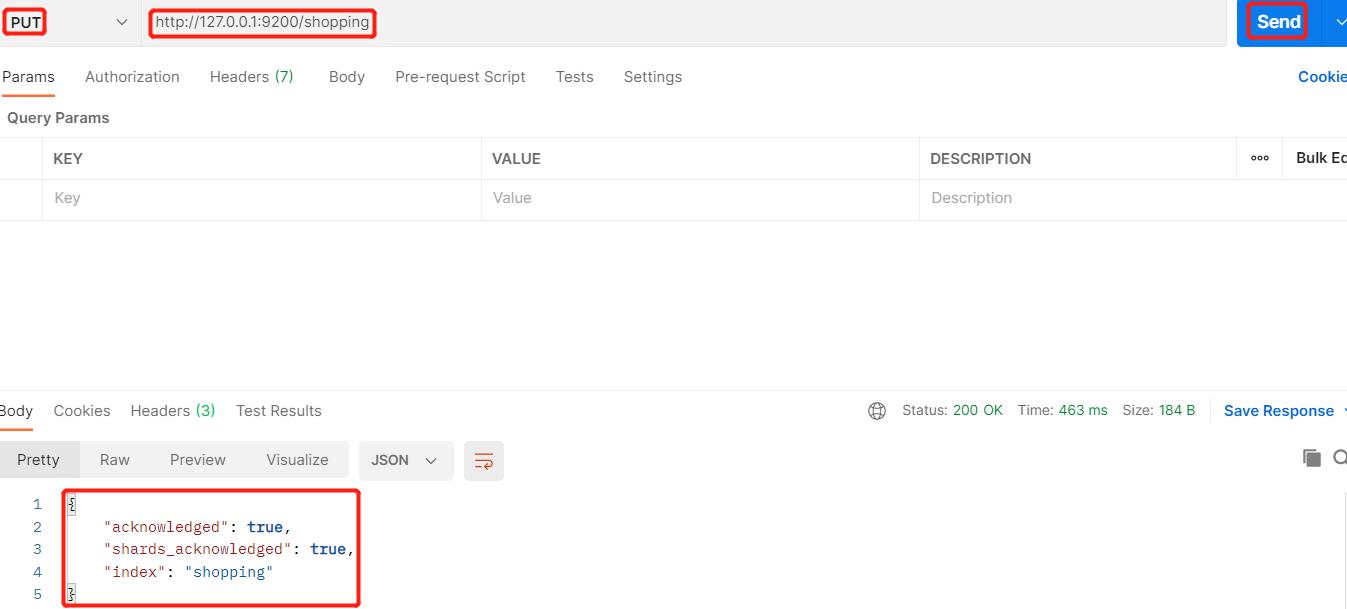
1、创建索引
索引在ES中的含义类似于MySQL中的数据库
在ES中创建一个名为shopping的索引(ES默认端口为9200):
2、查询索引
只需要将请求方式改为GET即可:
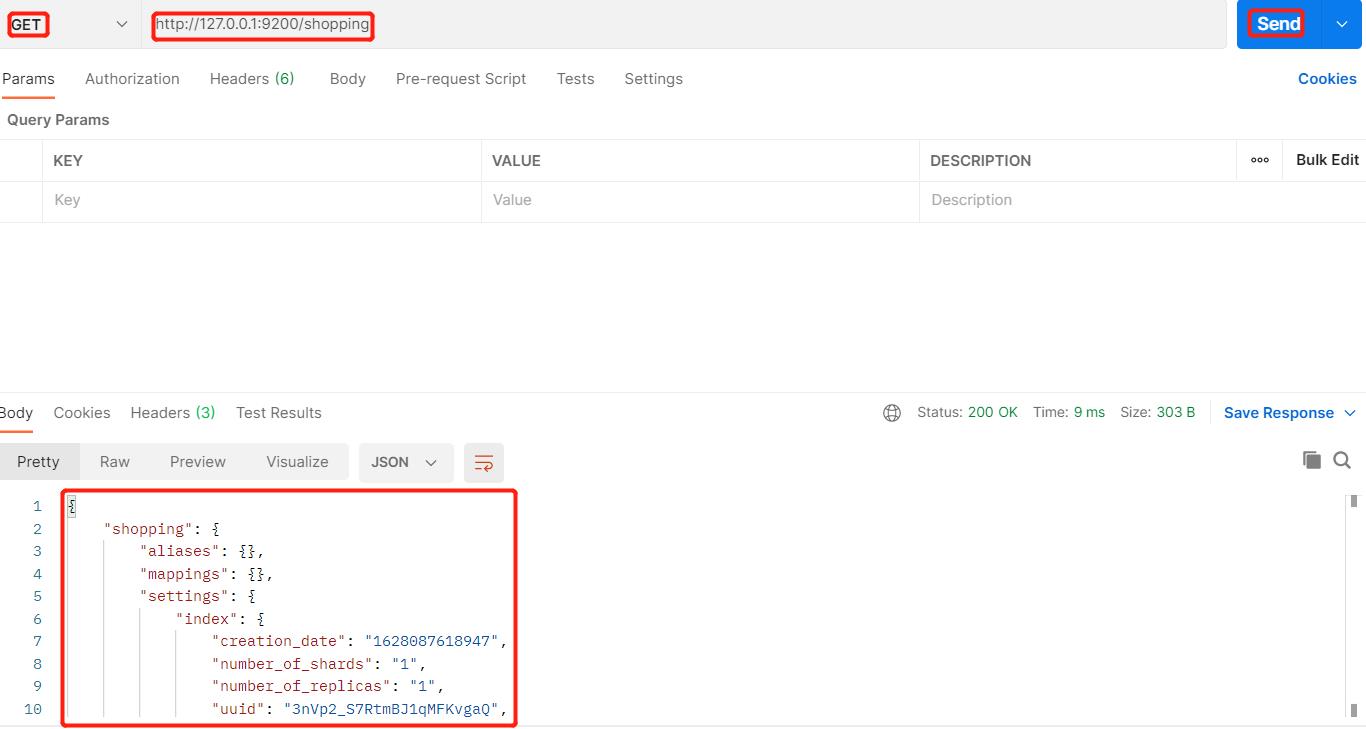
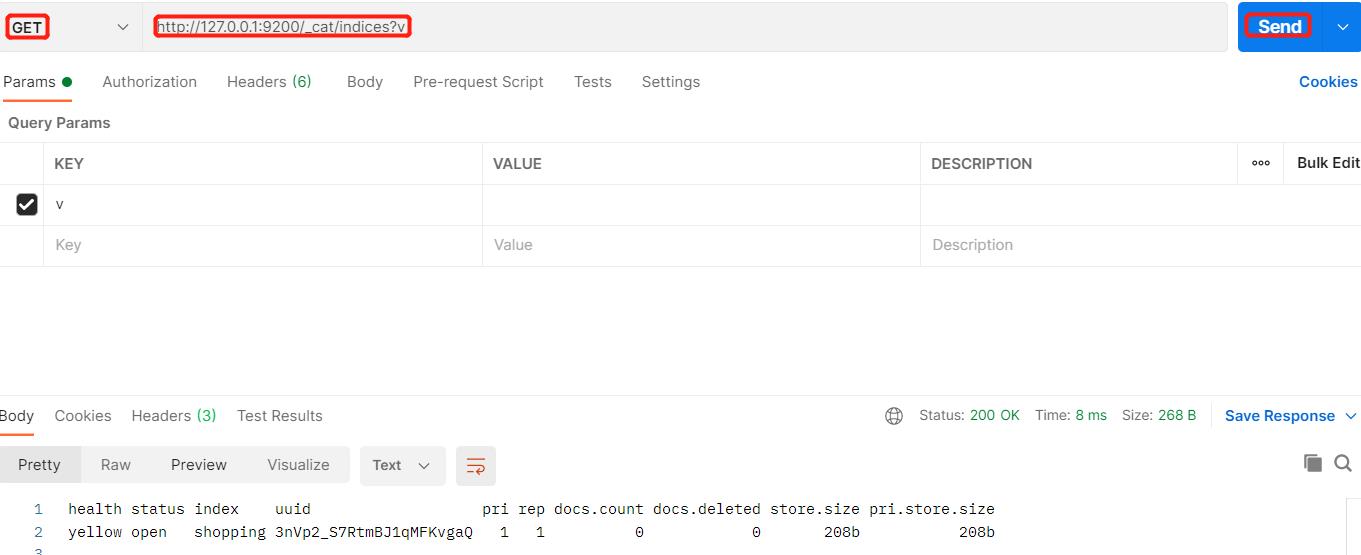
当然了我们也可以查询所有的索引:
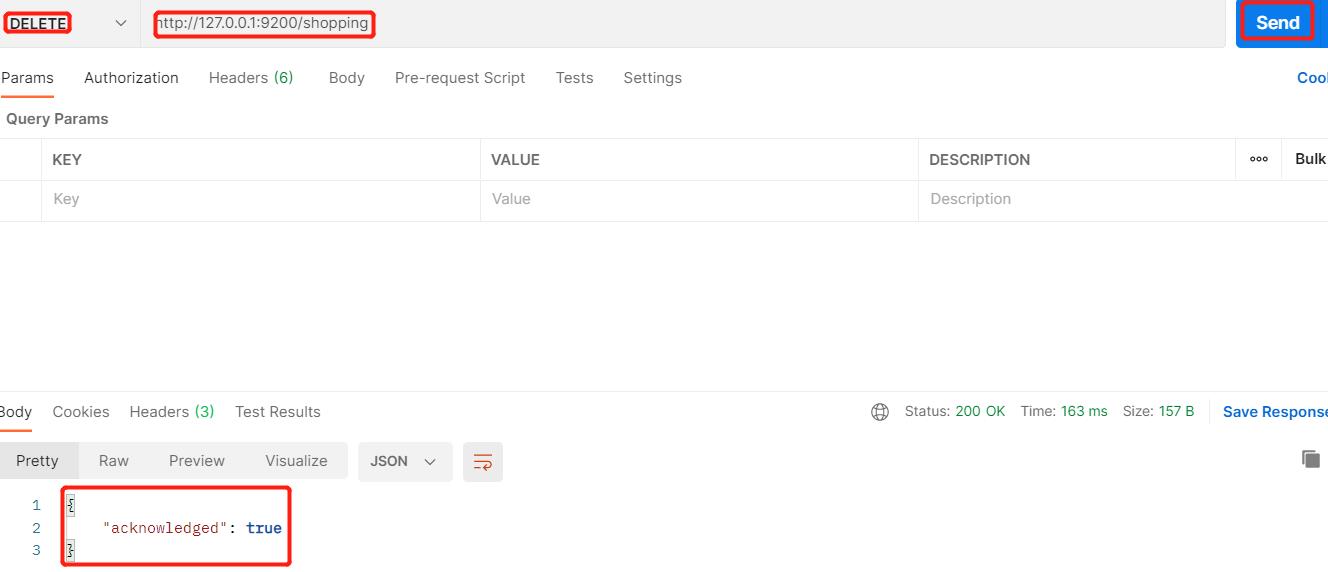
3、删除索引
4、创建文档
索引创建好了之后,我们接下来需要创建文档,文档可以看成MySQL中的行,用于存储数据(ES在7版本之后,没有表的概念)
接下来我们在shopping索引中创建一个_doc的文档,并插入数据:
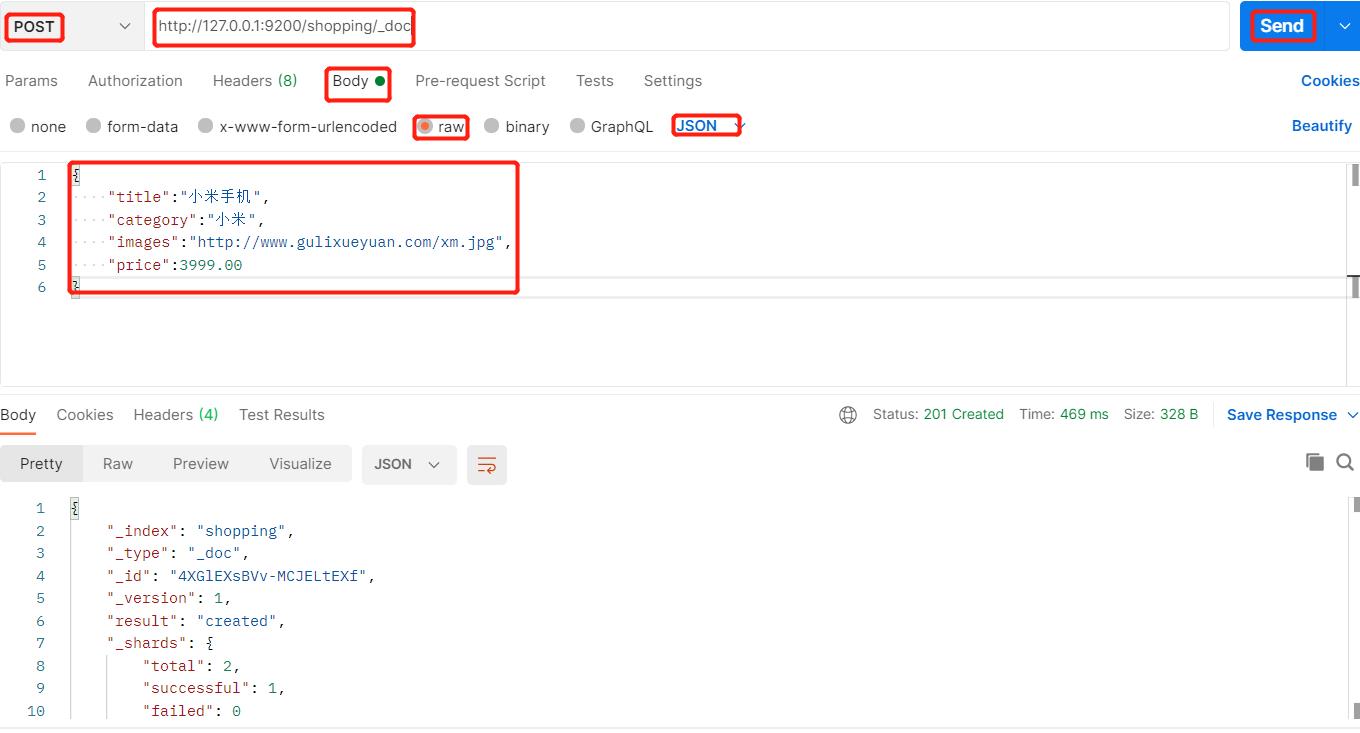
注意:这里的请求方式不能用PUT,因为上述请求发出多次返回的_id不同,说明POST操作不是幂等性,然而PUT是幂等性,所以这里不能使用PUT
当然我们可以在创建文档时候,添加对应的id:
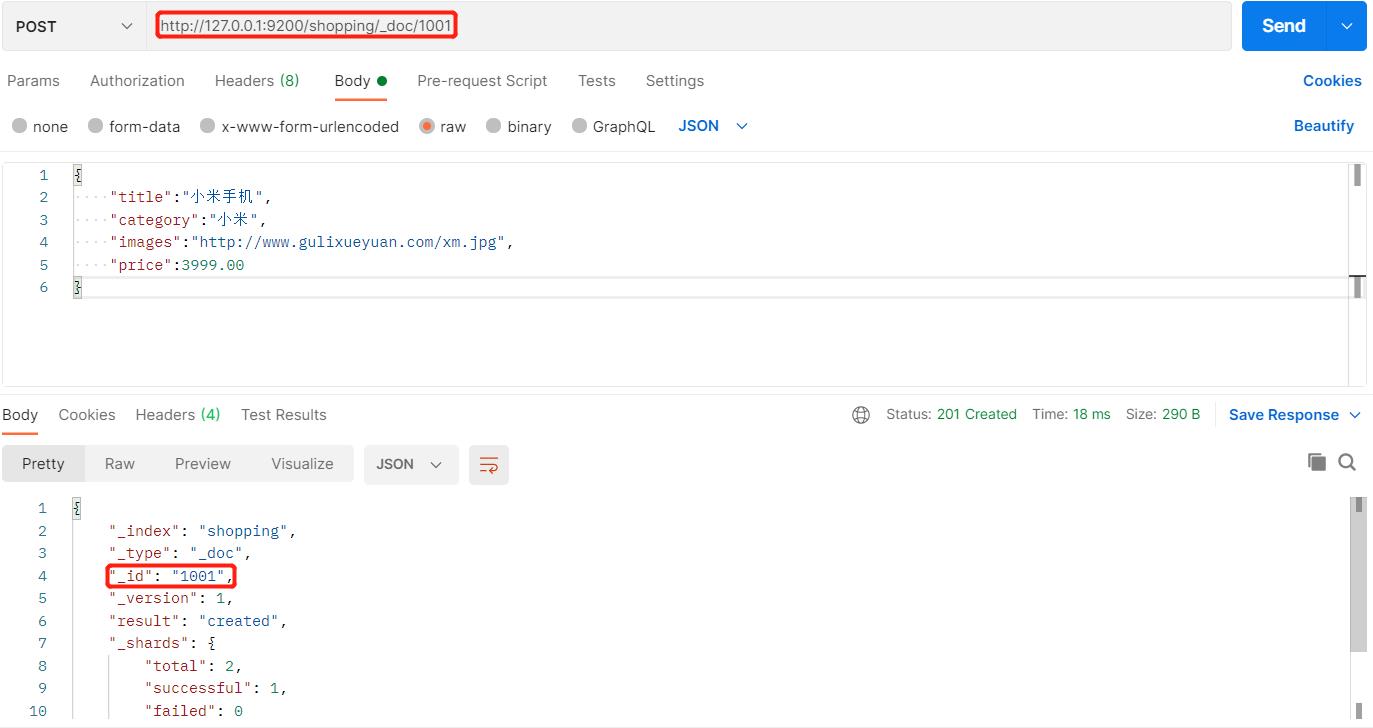
5、主键查询
根据主键1001查询出数据:

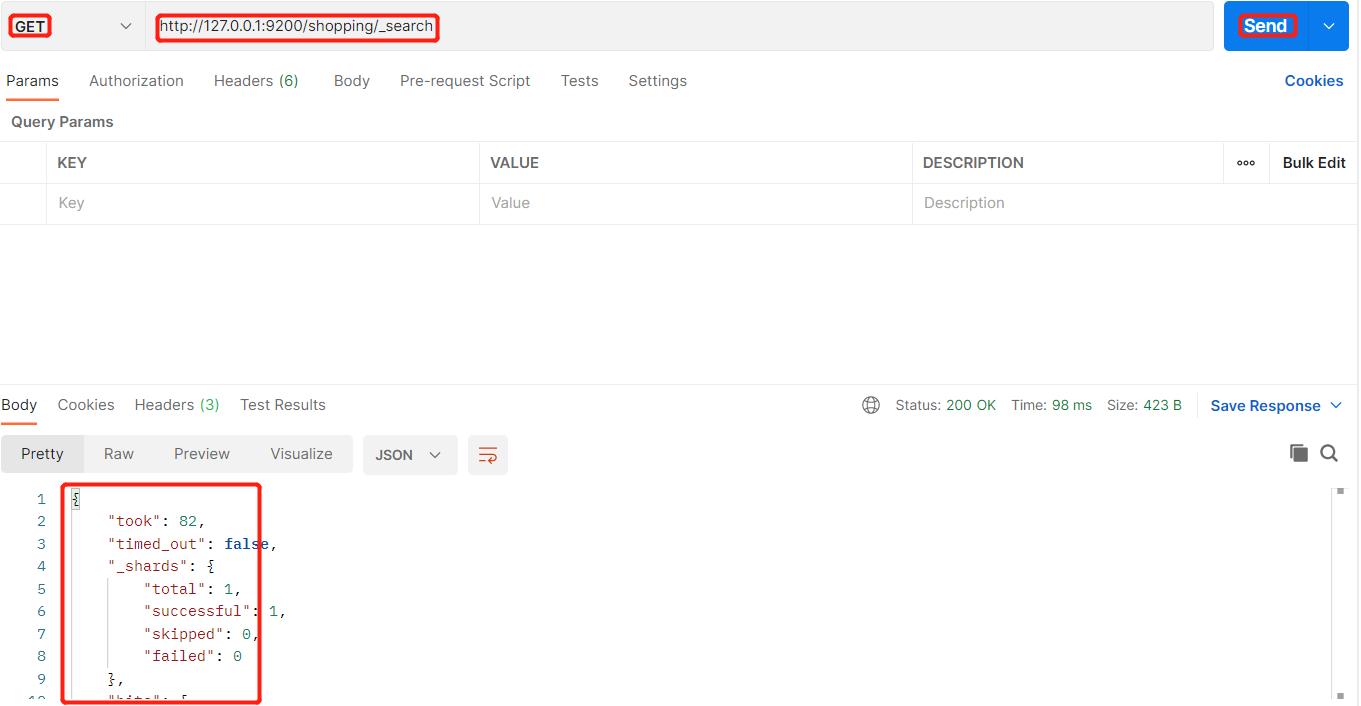
6、全查询
上述主键查询只能查询索引中一条数据,如果我们想要查询索引shopping中的所有数据,应该使用 _search 进行全查询:
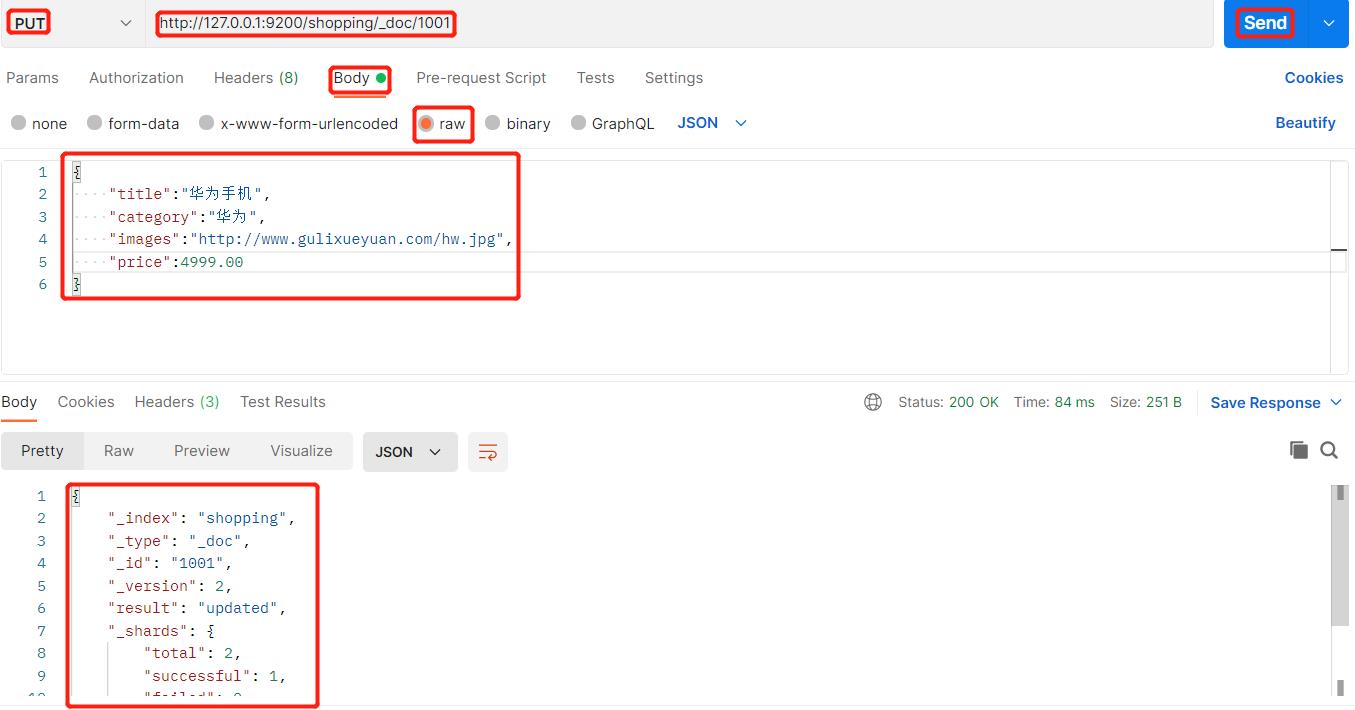
7、全量修改
对文档中索引为1001的数据进行全量修改:
8、局部修改
对数据中的title属性就行修改:
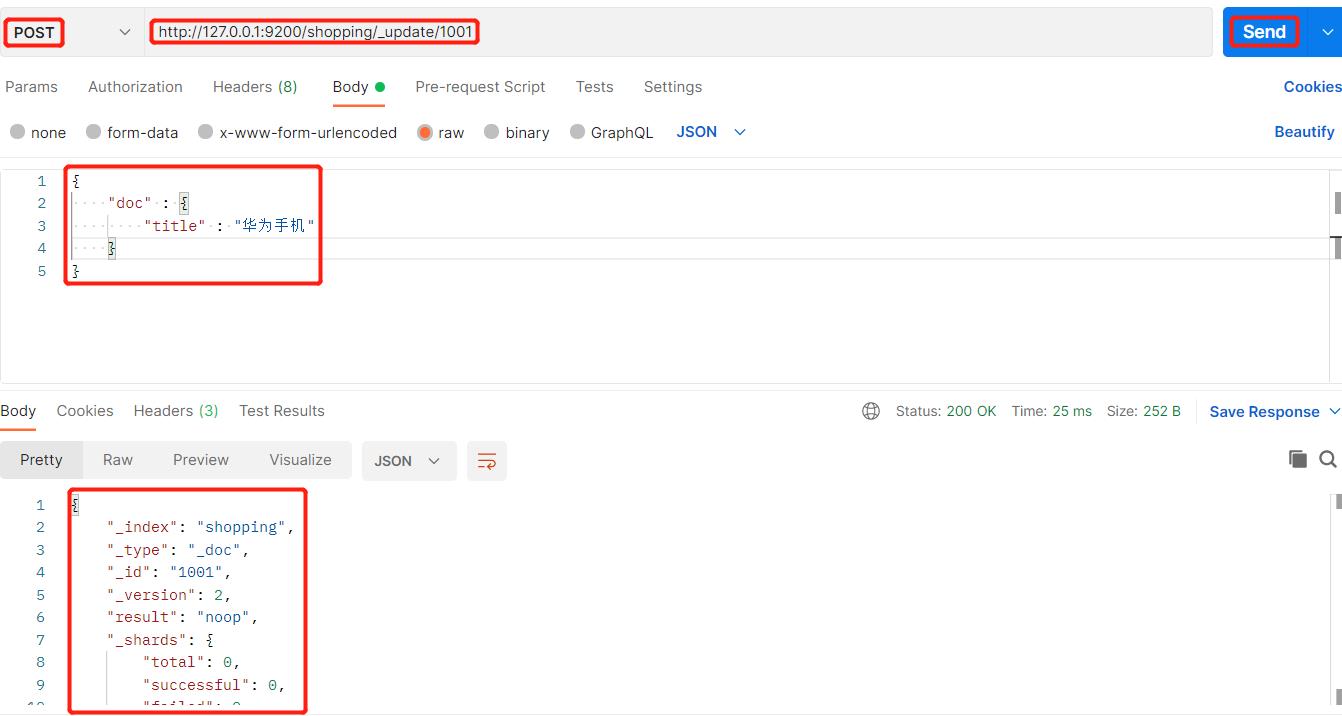
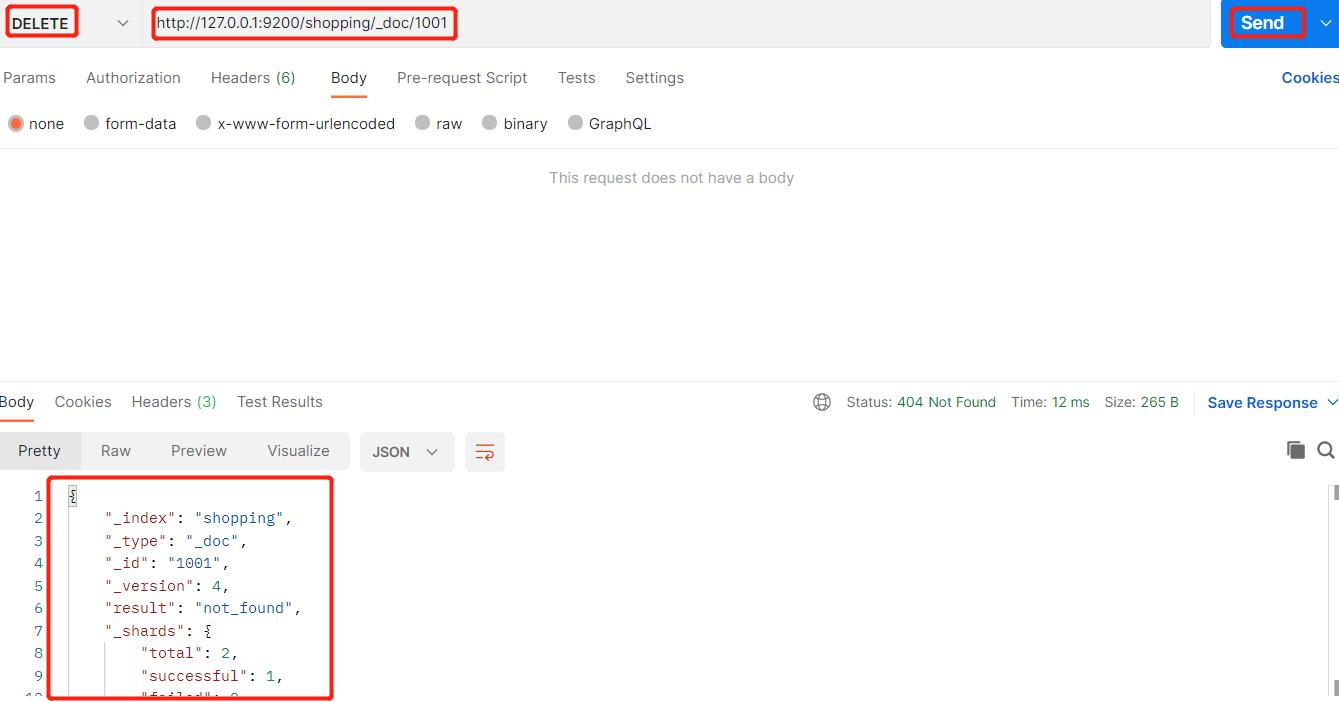
9、删除数据
我们同样可以把1001数据进行删除:
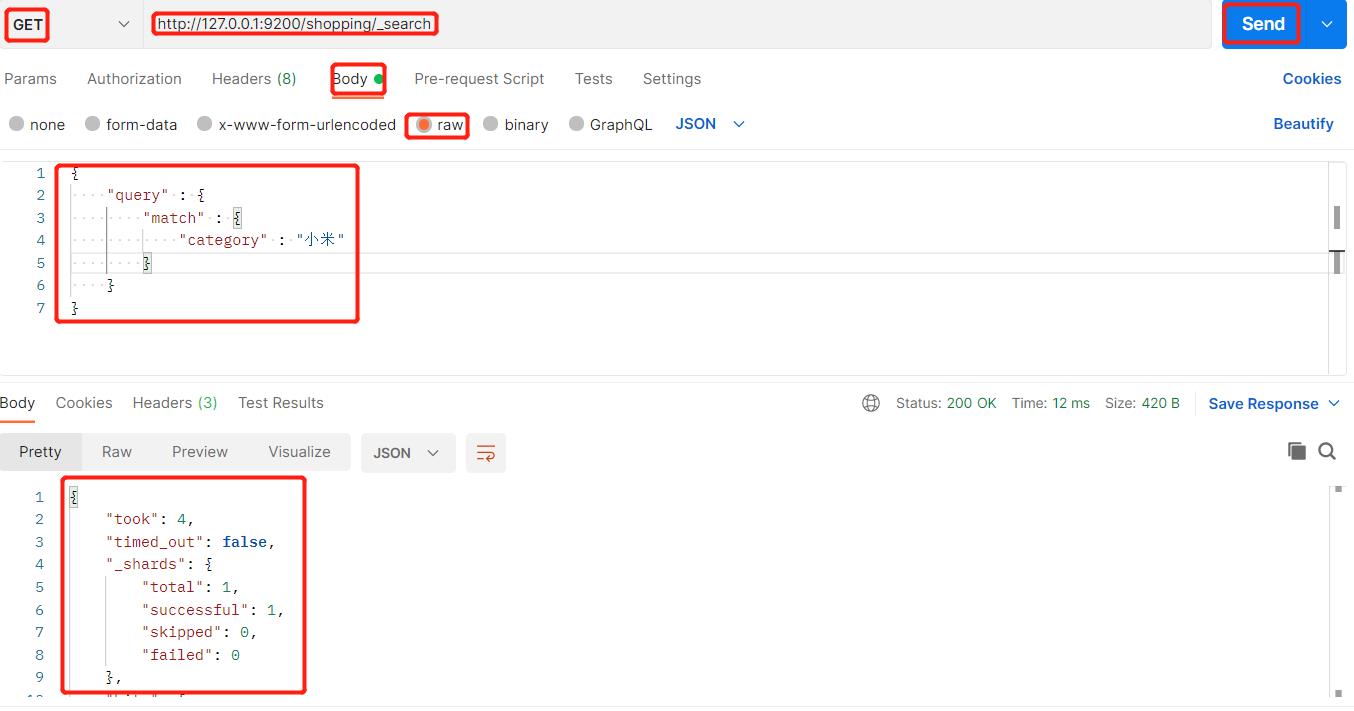
10、条件查询
查询shopping索引中category = 小米的数据:
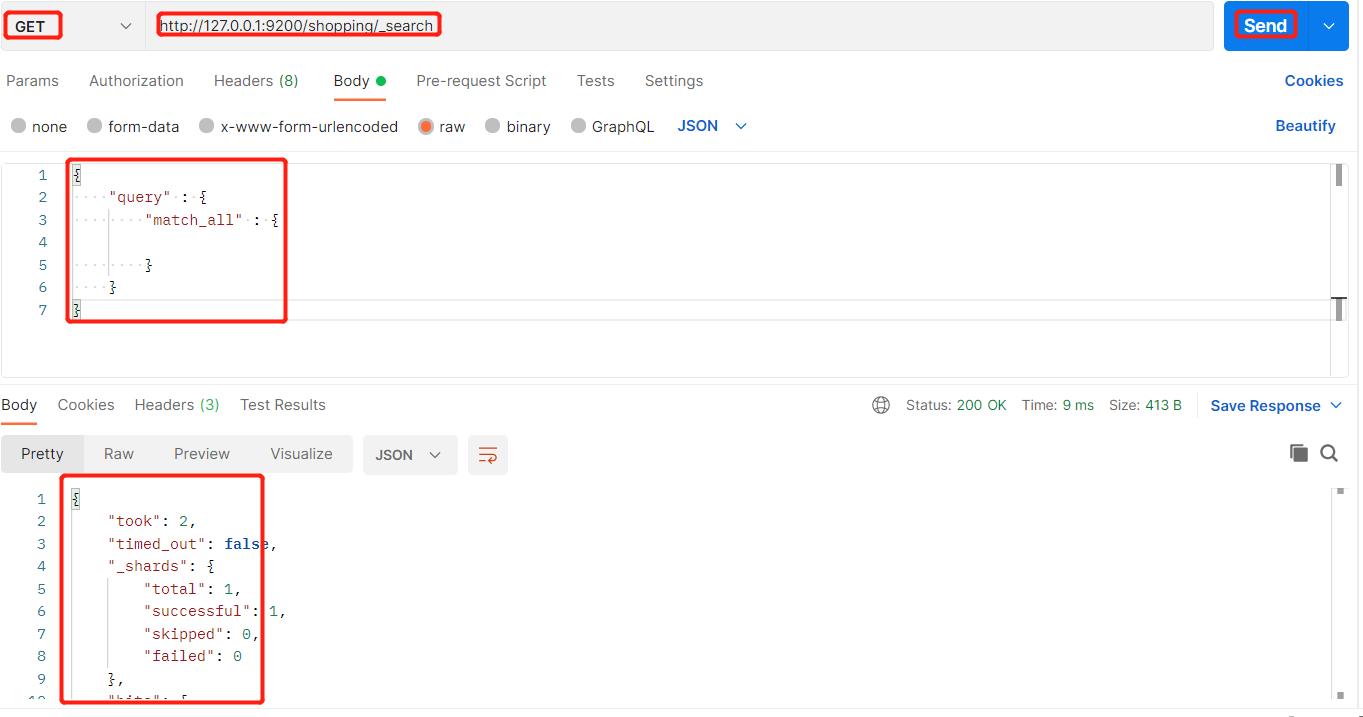
当然我们也可以不使用条件进行全查询:
11、分页查询
我们可以从第一页开始,每页查询两条数据:
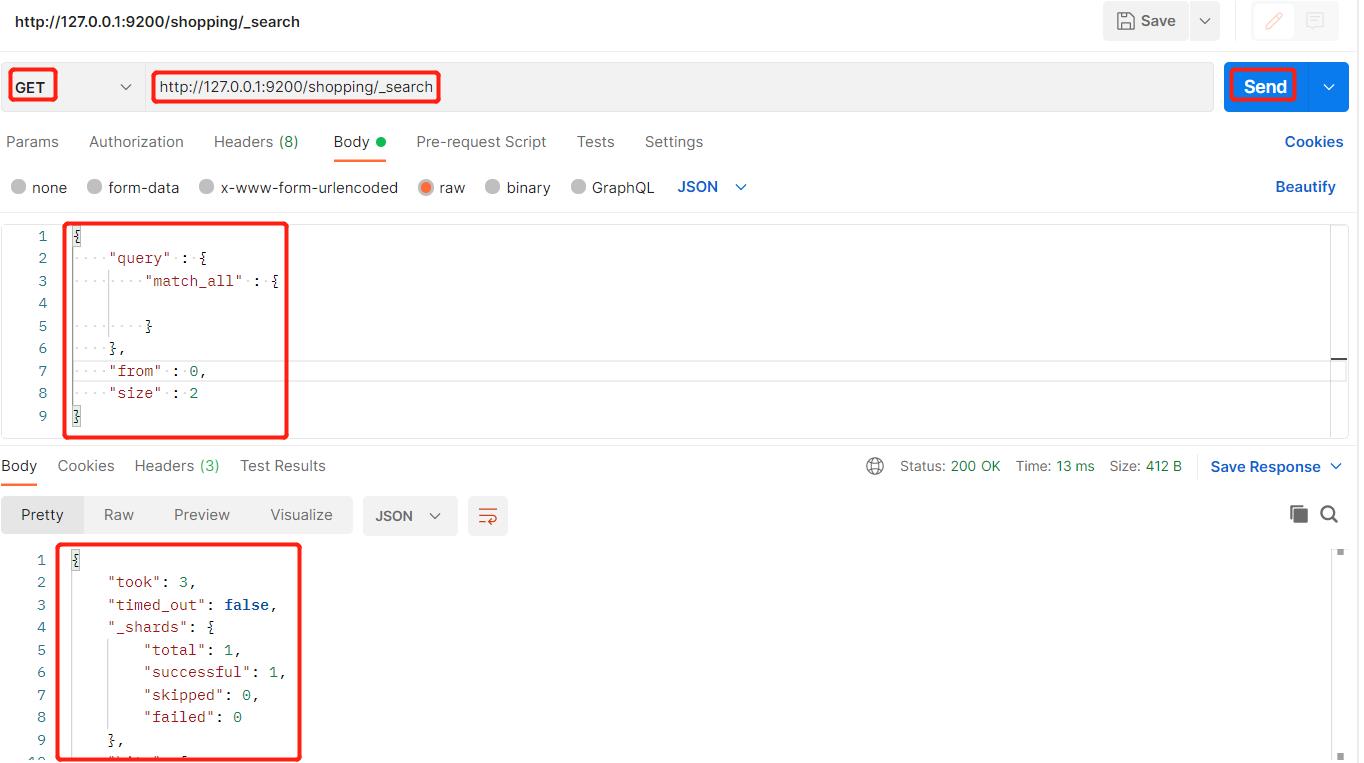
当然,如果我们查询出来的内容不都是我们想要的,我们可以指定我们显示的内容,例如只显示title:
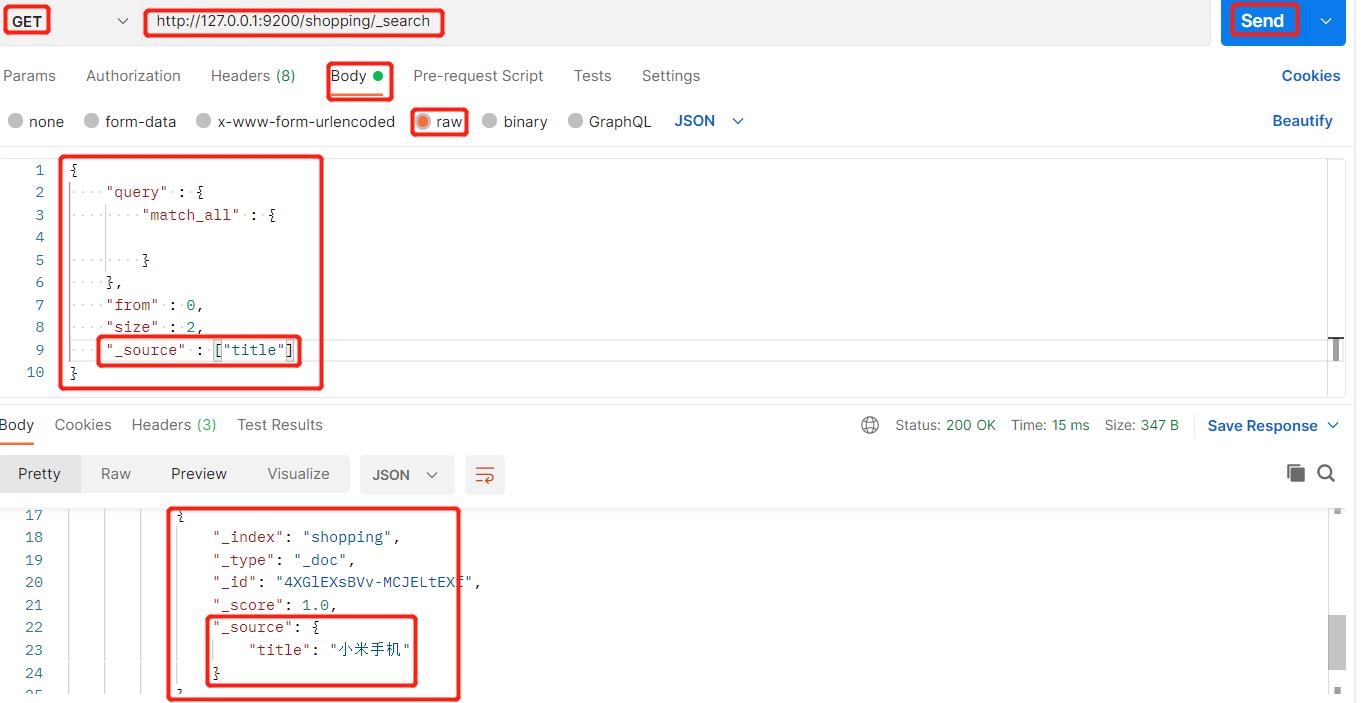
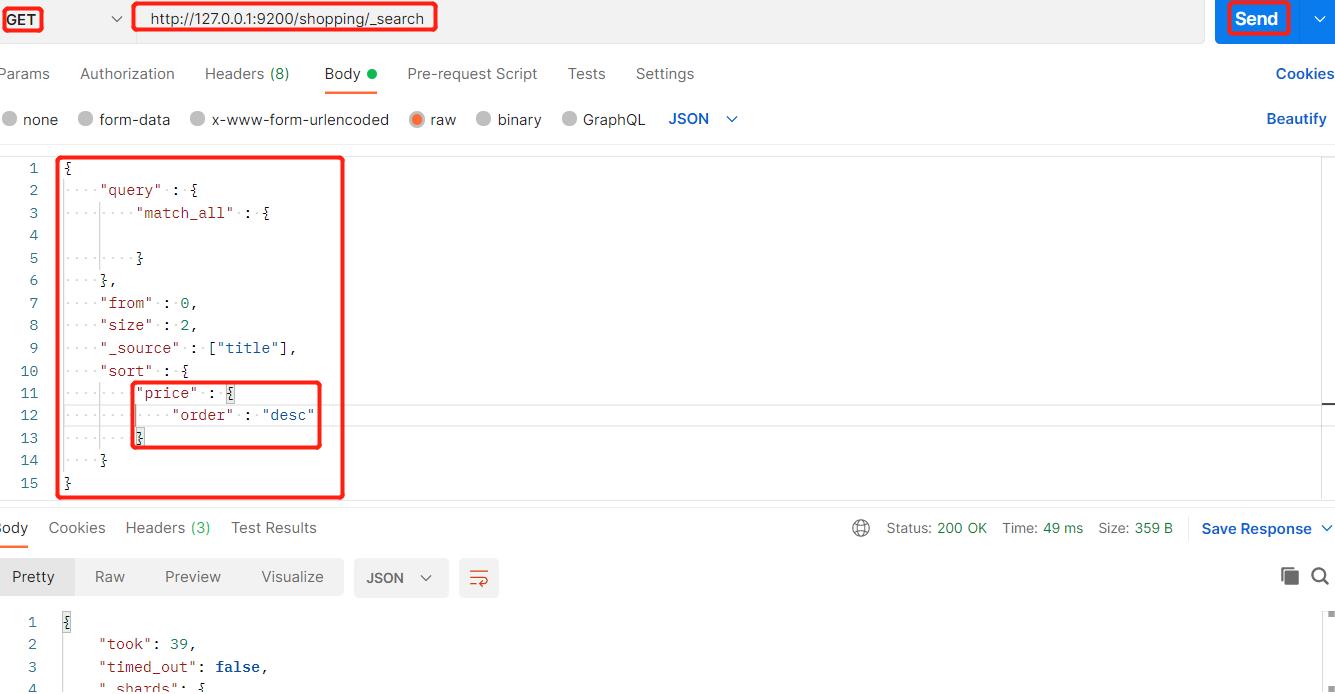
12、查询排序
我们也可以将查询出来的结果进行排序,例如根据价格进行倒数排列:
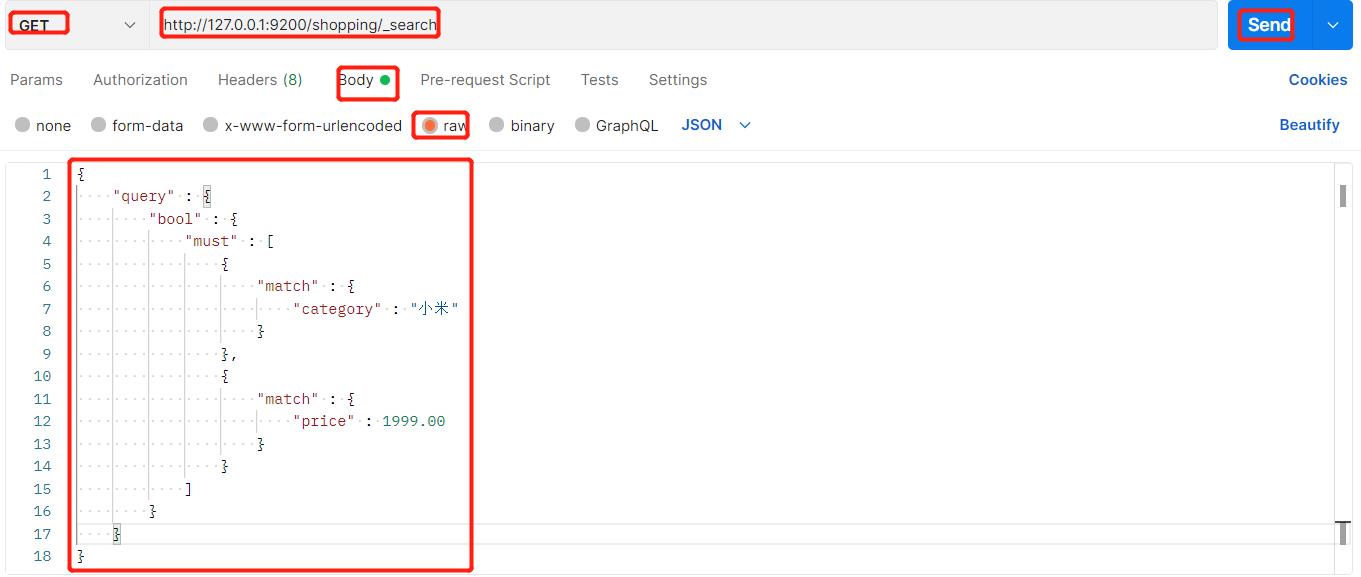
13、多条件查询
这种查询方式叫做多条件查询,must类似于and,根据category和price两个条件同时成立进行查询:
上述查询是两个条件同时成立,当然我们也可以任意一个成立进行查询,使用should,类似于or:
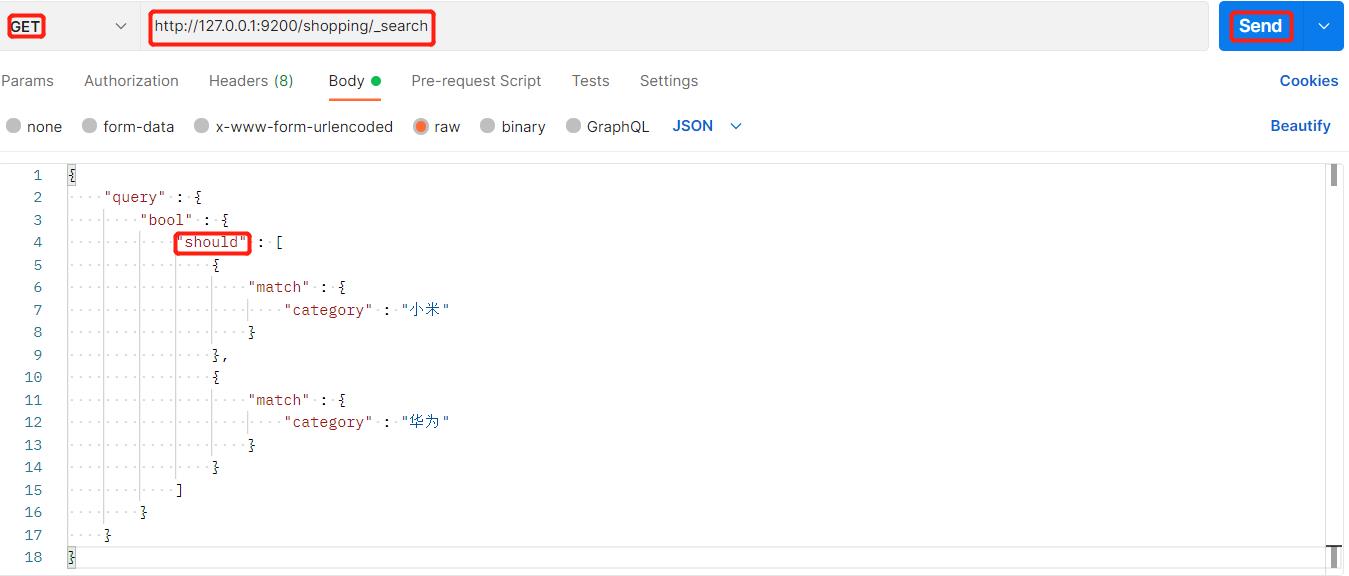
14、范围查询
我们可以在上述多条件查询基础上,增加一个范围查询,把价格大于5000的数据查询出来:
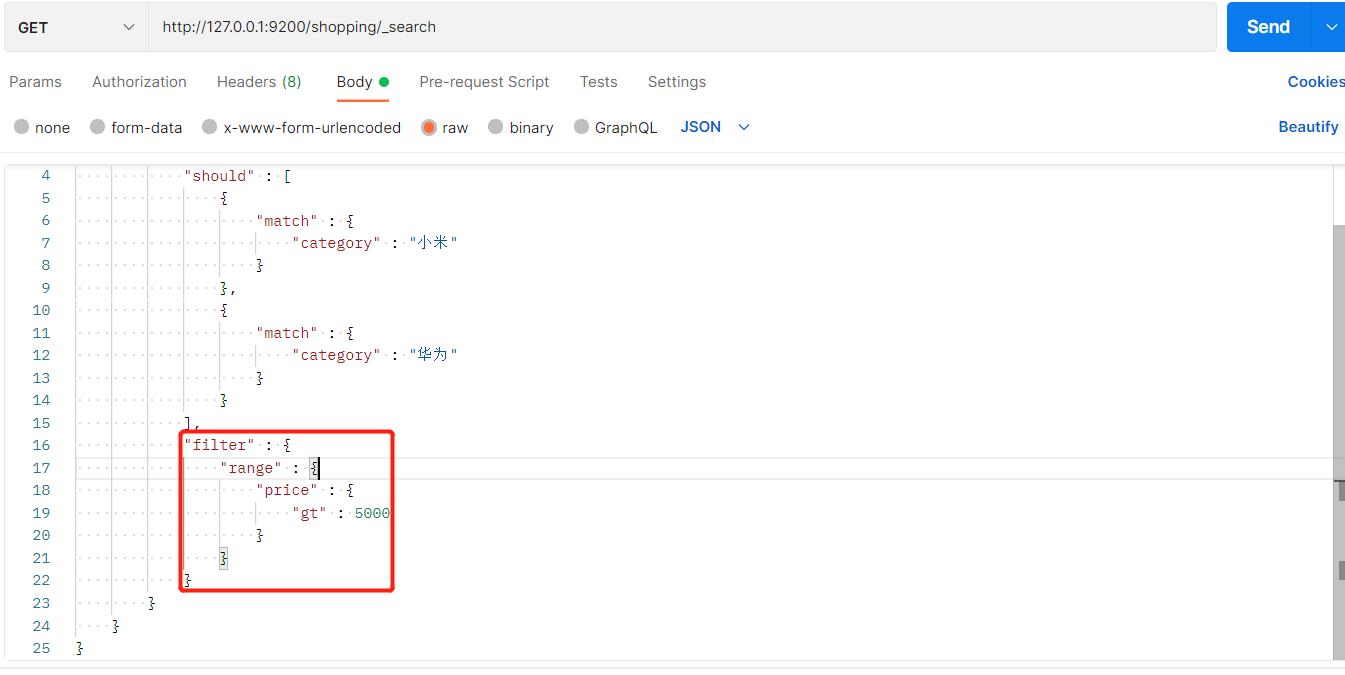
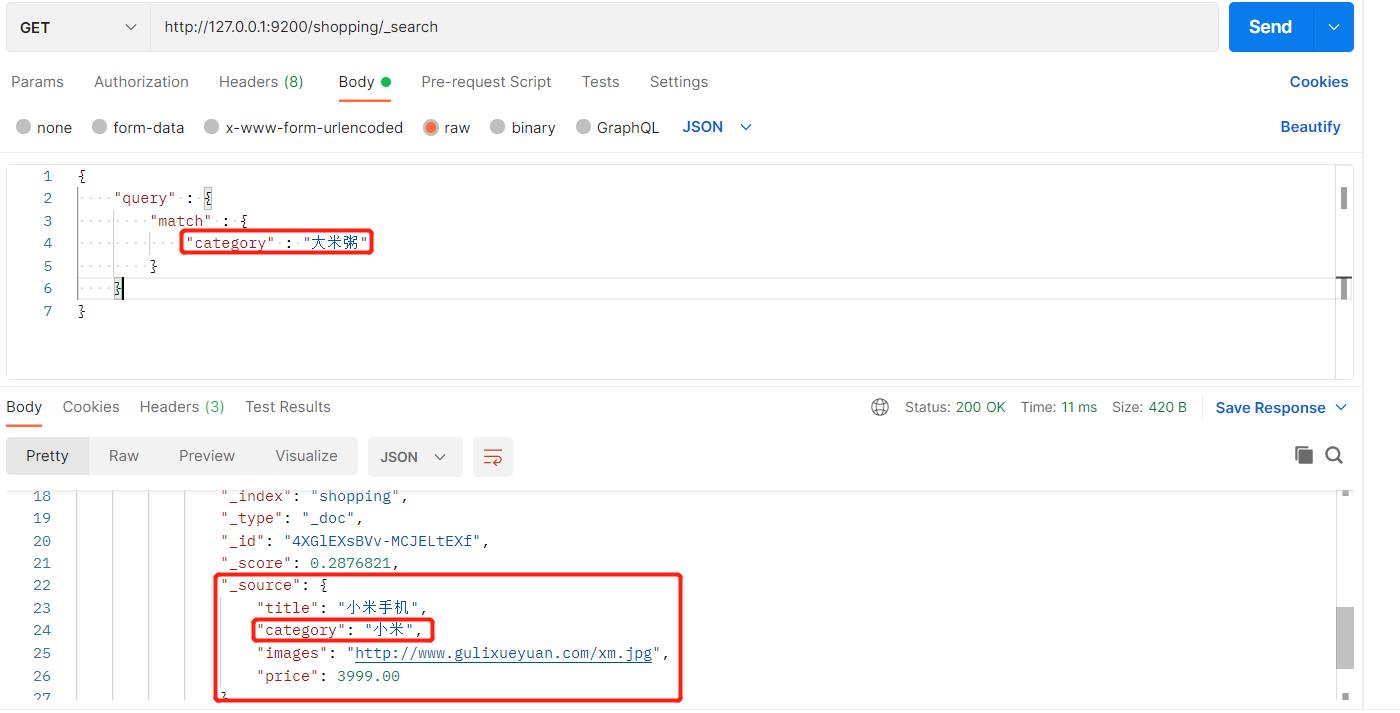
15、全文检索
全文检索就是看似我们查询大米粥三个字除了米其他的跟我们数据没有任何关系,但是依旧可以查询成功,原因就是底层会将三个字进行拆解,形成一个个关键字,进行倒排索引匹配,匹配成功就将数据查询出来:
16、完全匹配
虽然底层进行分词,即使我们输入数据中某一个字也能查询出结果,当然还有一个完全匹配查询的方式,使用match_phrase:

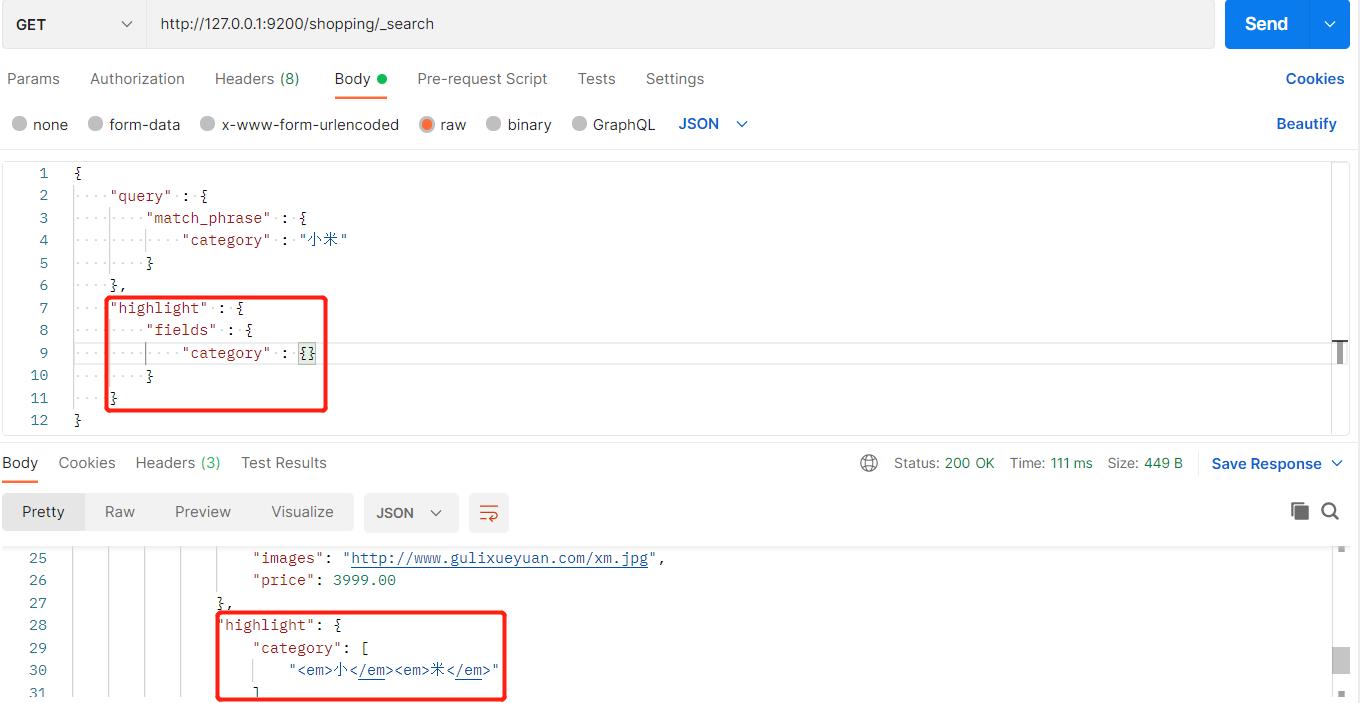
17、高亮查询
我们可以将查询出的结果像百度一样,进行高亮显示:
18、聚合查询
我们可以根据价格进行分组,聚合查询:
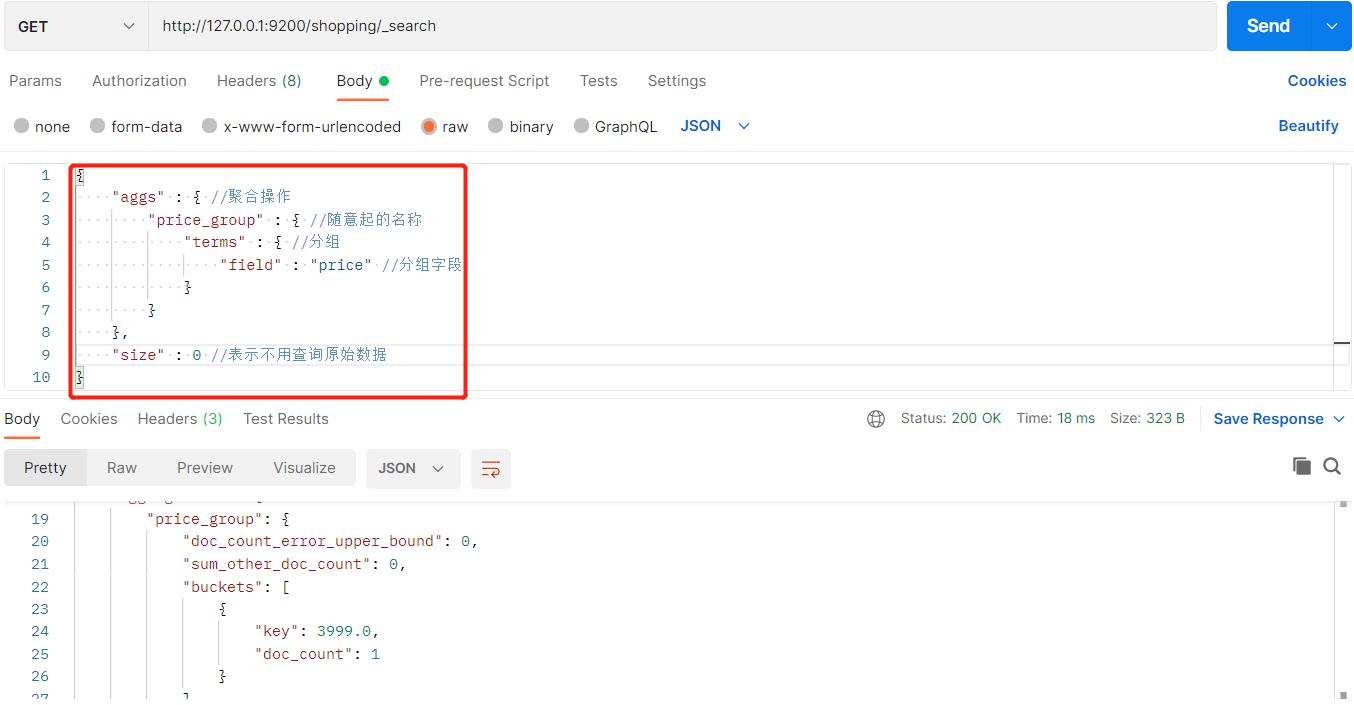
也可以通过平均价格进行聚合查询:
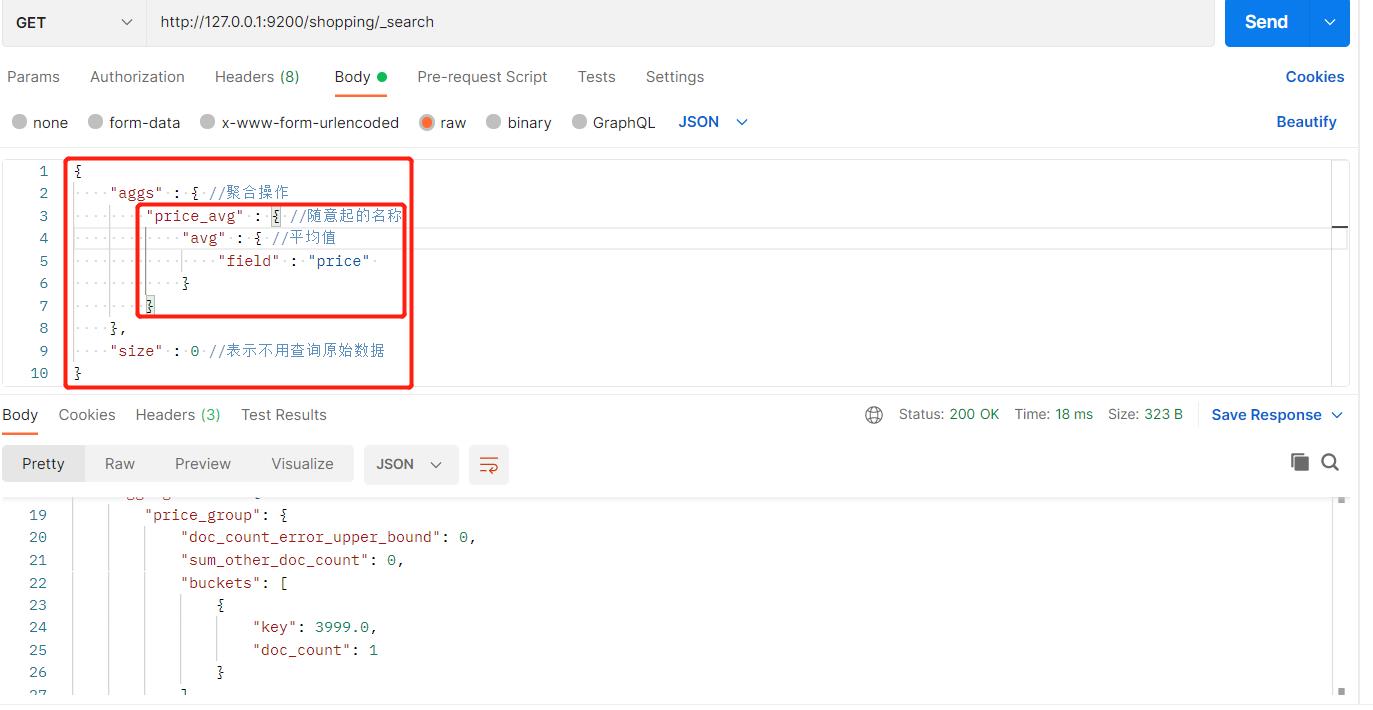
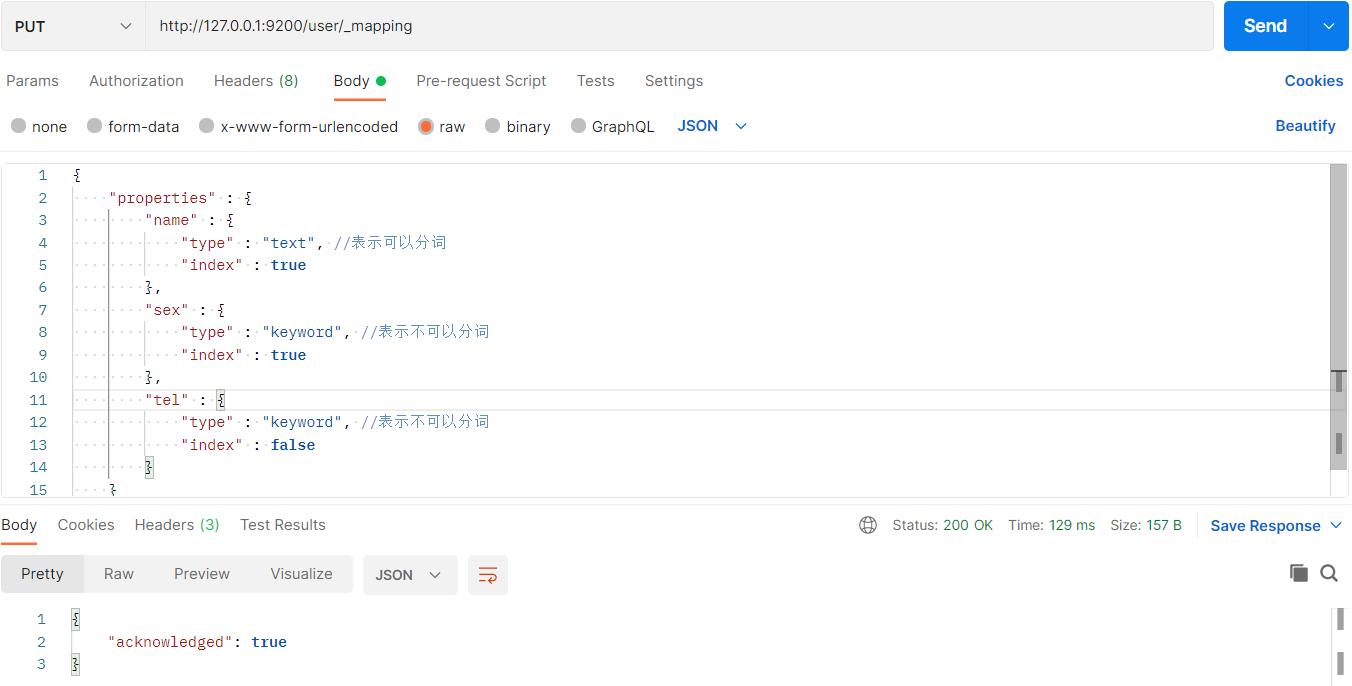
19、映射条件
首先创建一个user索引,文档名为_mapping:
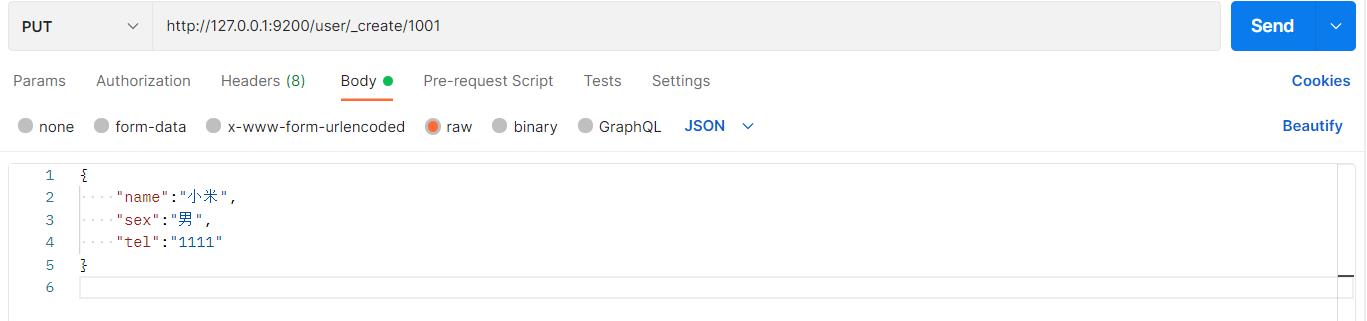
接下来多插入数据:
然后进行查询name,发现可以查询name,说明有分词效果:
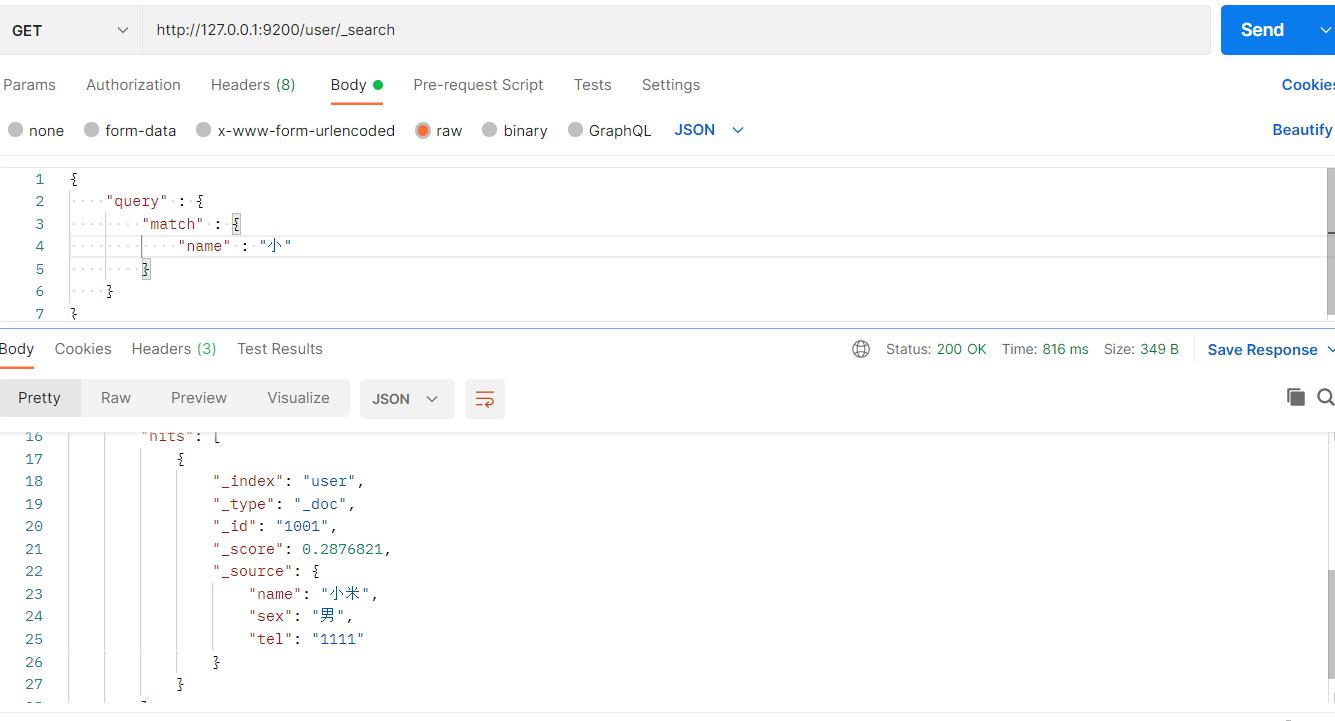
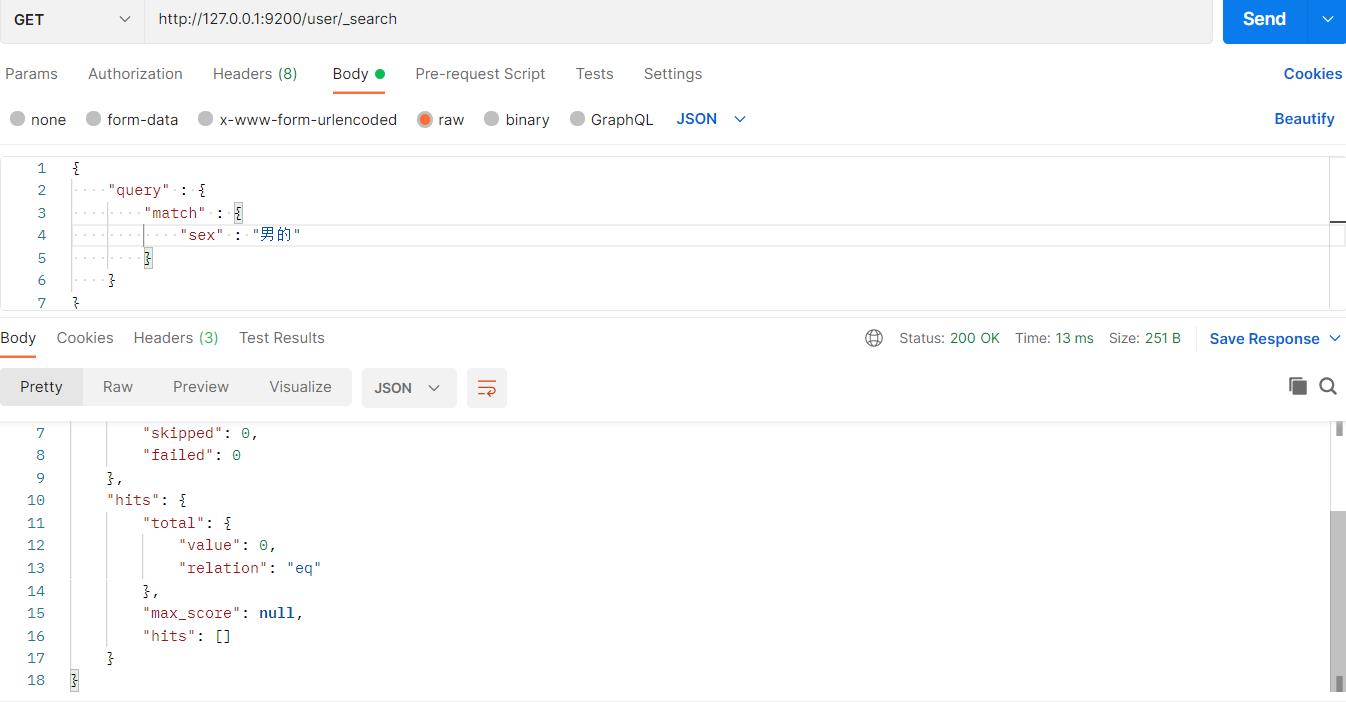
然后查询sex,发现查不到,因为sex使用keyword,是个关键字不可以分词,所以查询不到,必须要完全匹配才能查到:
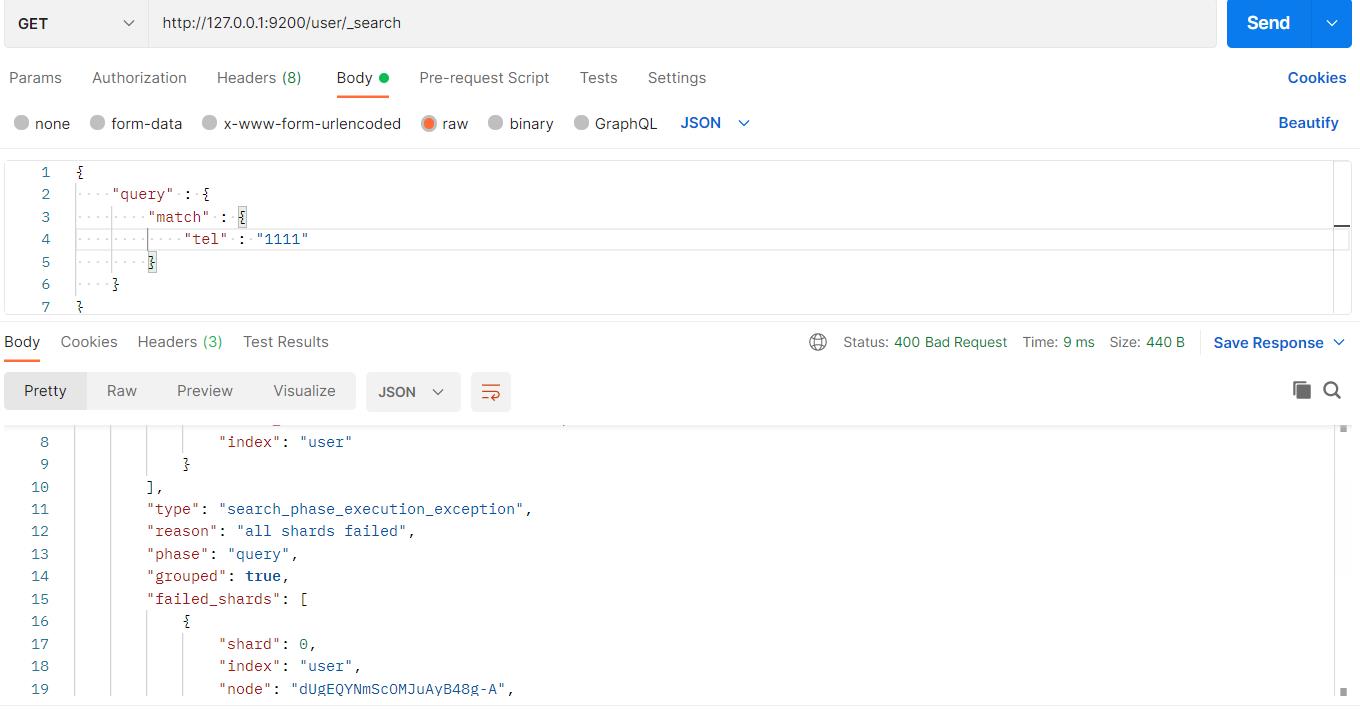
最后查询 tel,index为false,不能被索引,所以不能被查询,所以查询就会失败:
以上是关于elasticsearch 跨索引联合多条件查询的主要内容,如果未能解决你的问题,请参考以下文章