深度学习之图像抠图 Image Matting算法调研
Posted 明月醉窗台
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度学习之图像抠图 Image Matting算法调研相关的知识,希望对你有一定的参考价值。
目录
3.7 MMNet:Towards Real-Time Automatic Portrait Matting on Mobile Devices
3.8 Fast Deep Matting for Portrait Animation on Mobile Phone
3.9 MODNet: Trimap-Free Portrait Matting in Real Time
1.Trimap和Strokes
Trimap和Strokes都是一种静态图像抠图算法,现有静态图像抠图算法均需对给定图像添加手工标记以增加抠图问题的额外约束。
- Trimap,三元图,是对给定图像的一种粗略划分,即将给定图像划分为前景、背景和待求未知区域
- Strokes则采用涂鸦的方式在图像上随意标记前景和背景区域,剩余未标记部分则为待求的未知区域

Trimap是最常用的先验知识,多数抠图算法采用了Trimap作为先验知识,顾名思义Trimap是一个三元图,每个像素取值为0,128,255其中之一,分别代表前景、未知与背景,如图

2. 相关数据集
- Adobe Composition-1K
- matting_human_datasets : https://github.com/aisegmentcn/matting_human_datasets
- VideoMatte240K
- PhotoMatte85
- RealWorldPortrait-636
- https://github.com/thuyngch/Human-Segmentation-PyTorch
- Automatic Portrait Segmentation for Image Stylization: 1800 images
- Supervisely Person: 5711 images
3.论文算法调研
3.1 Deep Image Matting
Paper:https://arxiv.org/pdf/1703.03872.pdf
GitHub: https://github.com/Joker316701882/Deep-Image-Matting
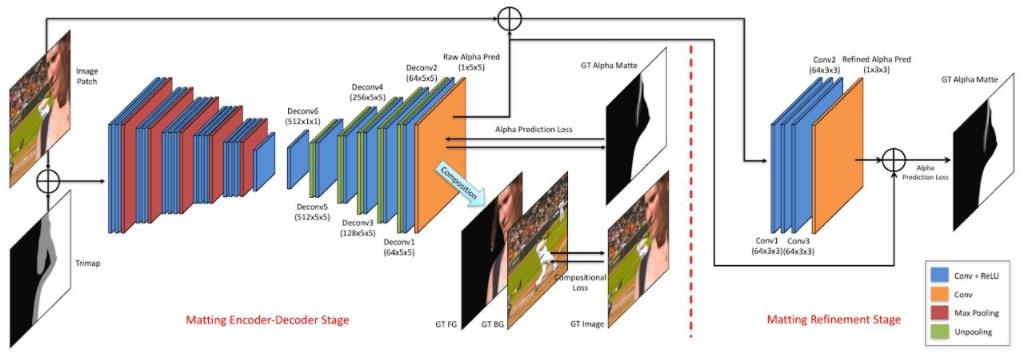
Adobe在17年提出了Deep Image Matting,这是首个端到端预测alpha的算法;整个模型分Matting encoder-decoder stage与Matting refinement stage两个部分,Matting encoder-decoder stage是第一部分,根据输入图像与对应的Trimap,得到较为粗略的alpha matte。Matting refinement stage是一个小的卷积网络,用来提升alpha matte的精度与边缘表现。
说明:网络输入是一个patch图像(经过crop)和相应的 trimap, 通过concat, 共4通道输入网络,推理时也要提供trimap图,现实中不太方便
3.2 Semantic Image Matting
Paper: https://arxiv.org/abs/2104.08201
Github: https://github.com/nowsyn/SIM
与Deep Image Matting类似,需要加入trimap进行抠图

3.3 Background Matting
Paper:https://arxiv.org/abs/2004.00626
GitHub: https://github.com/senguptaumd/Background-Matting
这篇文章要介绍的是一篇基于深度学习的无交互的抠图方法。它的特点是不需要Trimap图,但要求用户手动提供一张无前景的纯背景图,如图1所示,这个方法往往比绘制三元图更为简单,尤其是在视频抠图方向 。这个要求虽然不适用于所有场景,但在很多场景中纯背景图还是很容易获得的。

说明: 不需要Trimap图,但需要提供一张无前景的纯背景图
3.4 Background Matting V2
Paper: https://arxiv.org/abs/2012.07810
GitHub: https://github.com/PeterL1n/BackgroundMattingV2
Background Matting得到了不错的效果,但该项目无法实时运行,也无法很好的处理高分辨率输入。所以项目团队又推出了Background Matting V2,该项目可以以30fps的速度在4k输入上得到不错的结果。

说明: 与Background Matting类似,V2不需要Trimap图,但需要提供一张无前景的纯背景图
3.5 Semantic Human Matting
Paper: https://arxiv.org/pdf/1809.01354.pdf
GitHUb: https://github.com/lizhengwei1992/Semantic_Human_Matting
阿里巴巴提出的Semantic Human Matting:
- 首次实现无需Trimap方式生成alpha图
- 提出了新的fusion的策略,用概率估计alpha matte
- 构造了新的数据集
将网络分成两个部分。
- TNet: 对前景、背景、未知区域做像素级别的分类(相当于预测Trimap了)。
- MNet: 将TNet的输出当做输入,生成更加精细的alpha matte。
- 两个网络的输出经过Fusion Module生成最终的结果
T-Net对像素三分类得到Trimap,与图像concat得到六通道输入送入M-Net,M-Net通过encoder-decoder得到较为粗糙的alpha matte,最后将T-Net与M-Net的输出送入融合模块Fusion Module,最终得到更精确的alpha matte。

3.6 HAttMatting
Paper: https://wukaoliu.github.io/HAttMatting/
GitHub:https://github.com/wukaoliu/CVPR2020-HAttMatting (仅有效果图,连测试模型都没有,存在很大的质疑)
Attention-Guided Hierarchical Structure Aggregation for Image Matting
这也是一篇不需要提供trimap或者其他交互的抠图方法(可认为是自动化抠图),核心思想是抑制高级特征中的冗余语义,并消除空间线索中无用的背景细节,然后对其进行聚合以预测准确的alpha 通道。
为此,该文使用通道注意力(channel-wise attention)模型来蒸馏金字塔特征,并对空间线索使用空间注意力(spatial attention ),以同时消除前景以外的图像纹理细节。

说明:该文声称可以无trimap或者其他交互辅助的条件下,进行完全自动化抠图!! 实质上,存在很多矛盾,就比如上去,上述效果图,模型怎么知道要抠图是那个球球,而不是那条马呢?
更多质疑:[质疑][CVPR2020]只有强者才能“抠”脚 - 知乎
3.7 MMNet:Towards Real-Time Automatic Portrait Matting on Mobile Devices
Paper: https://arxiv.org/abs/1904.03816
Github: https://github.com/hyperconnect/MMNet
Mobile Matting Network (MMNet)采用了标准的编码-解码框架。其中,编码器通过多次下采样,逐步减小输入特征的尺寸,在捕获更高级语义信息的同时,也在丢失空间/位置信息。另一方面,解码器对特征图进行上采样,逐步恢复空间/位置信息,同时使其放大为原先的输入分辨率。另外,作者将来自跳连接的信息与上采样信息相串联,还采用了增强块来改善解码效果。如此,输出的alpha抠图就能与原始图像的尺寸保持一致了。MMNet的具体结构图1所示。
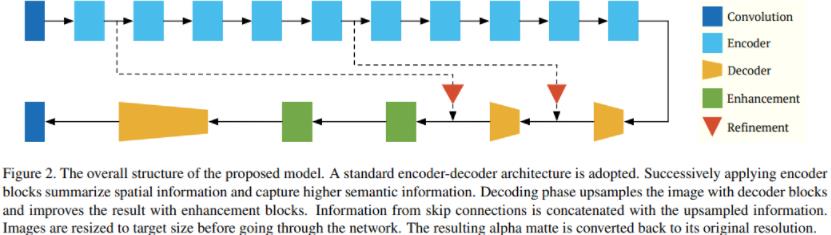
说明:17年的Paper,无需Trimap,在移动设备上实现了实时自动抠图功能,网络的体积较小, 效果有待验证
3.8 Fast Deep Matting for Portrait Animation on Mobile Phone
Paper: https://arxiv.org/abs/1707.08289
GitHub: https://github.com/huochaitiantang/pytorch-fast-matting-portrait
网络由两个阶段组成。
第一阶段是人像分割网络,它以一幅图像为输入,获得一个粗二进制mask。第二阶段是feathering模块(羽化模块),将前景/背景mask细化为最终的alpha matte。第一阶段用轻全卷积网络快速提供粗二进制mask,第二阶段用单个滤波器细化粗二进制mask,大大降低了误差。
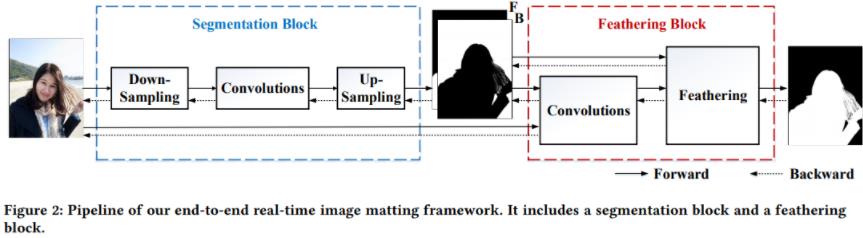
说明:无需Trimap,输入RGB图像,输出是matte, 效果有待验证
3.9 MODNet: Trimap-Free Portrait Matting in Real Time
Paper: https://arxiv.org/pdf/2011.11961.pdf
Github: https://github.com/ZHKKKe/MODNet
在线体验:Portrait Matting
MODNet模型学习分为三个部分,分别为:语义部分(S),细节部分(D)和融合部分(F)。
- 在语义估计中,对high-level的特征结果进行监督学习,标签使用的是下采样及高斯模糊后的GT,损失函数用的L2-Loss,用L2loss应该可以学到更soft的语义特征;
- 在细节预测中,结合了输入图像的信息和语义部分的输出特征,通过encoder-decoder对人像边缘进行单独地约束学习,用的是交叉熵损失函数。为了减小计算量,encoder-decoder结构较为shallow,同时处理的是原图下采样后的尺度。
- 在融合部分,把语义输出和细节输出结果拼起来后得到最终的alpha结果,这部分约束用的是L1损失函数。
个人觉得结构设计上较为清晰,监督信息与方式利用合理
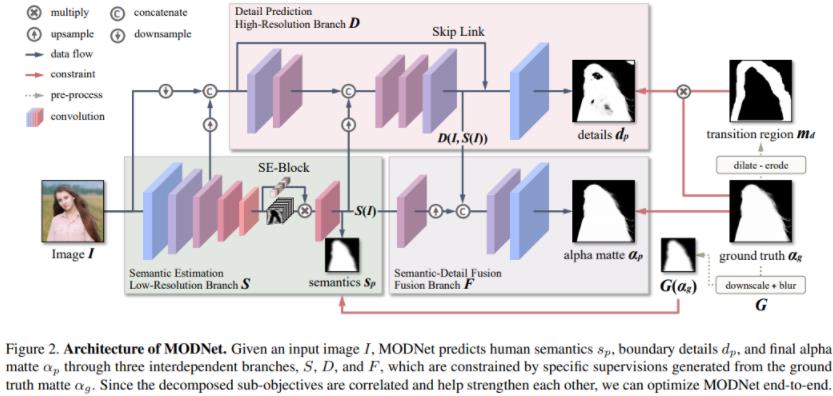
说明:无需Trimap, MODNet整体Matting效果,相当不错
Alpha matting算法发展
一、抠图算法简介
Alpha matting算法研究的是如何将一幅图像中的前景信息和背景信息分离的问题,即抠图。这类问题是数字图像处理与数字图像编辑领域中的一类经典问题,广泛应用于视频编缉与视频分割领域中。Alpha matting的数学模型是
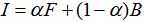
由Porter 和 Duff于1984 年提出[1]。他们首先引入了α 通道的概念,即它是一种前景和背景颜色的线性混合表示方法。一张图片包含前景信息、背景信息,将该图片看成是前景图和背景图的合成图,于是便有了以上的混合模型。前景α为1, 背景α为 0,α的取值介于0-1之间,表示前后背景图的线性组合。在大多数自然图像中,大多数像素点都属于绝对前景或者绝对背景,如何将其它混合点的α 值准确的估计出来是alpha matting的关键。

给定一个输入图像,对于所有像素点,它的(F,B, α)都是未知的,需要进行估计,如果图片是灰度图片,每个像素点包含3个未知数,这样的问题是一个欠约束问题。大多数抠图问题需要用户交互的先验条件,使得我们对已知输入图像的颜色统计有预先的估计和假设,从而能够更加准确的估计出未知量的值,常见的人工添加的约束条件有三区标注图(trimap)和草图(scribble)两种。
预先提供的约束条件(trimap图或scribble图)越精确,未知区域内的点就越少,更多前景和背景信息就更容易利用。然而,在实践中,要求预先输入非常准确的 trimap 是一件异常繁琐的工作,不现实也不必要的,如何在预先提供的trimap以及最终算法所求得的抠图结果之间寻求一个最佳答案,不同的抠图算法对于这个问题有着不同的阐述。
二、Alpha matting 算法的发展
通常,alpha matting算法要解决两个问题,一个是求解图像像素点颜色分布模型,一个是求解像素点颜色和α 值的关系。一些经典的抠图算法会预先假设好局部像素点颜色分布模型和像素点颜色α 值模型,再通过采样(例如贝叶斯抠图[2])或传播(例如封闭式(closed-form)抠图[3])的方法拟合模型,求解α 值,另一些抠图算法将抠图问题视为一个半监督的学习过程,用学习的方法拟合模型求解α 值[4]。以上这些方法中关联像素点是从待定像素的邻域中取的,除了这些局部抠图算法之外,一些学者根据非局部原理提出非局部抠图算法,例如K近邻抠图[5]、全局采样抠图[6]等。近年来深度学习如火如荼,最近比较热门的发展方向是基于CNN的抠图方法[7]。
2003年Chuang Y Y等提出贝叶斯抠图(Bayes matting)[2]算法,核心是通过领域采样,从待定像素的领域像素中采样关联像素,利用图像像素点的颜色值特征,以定向高斯模型建立像素颜色模型,再用极大似然发估计α 值。贝叶斯方法从条件概率的角度去考虑抠图问题,以贝叶斯公式建立F、B和α的联合概率分布,抠图问题就可以被转化为已知图片像素颜色I的情况下,为了最大化后验概率P(F,B,α|I),求 F、B和α估计值的问题。
2006年Levin A等提出封闭式抠图(Closed formed matting)[3],核心思想是通过传播的方法来利用图像的颜色特征,即允许α值从已知区域传播到领域未知域。封闭式抠图基于两个假设:一是颜色分布遵循颜色线性模型;二是前景背景颜色值局部平滑,并由此推知未知像素的alpha值和该像素点的颜色I呈线性相关关系,经过矩阵计算之后,代价函数表达式转化为关于α的二次型形式:
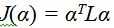
其中L为拉普拉斯矩阵(matting Laplacian matirx),可以由图像局部像素点颜色计算得到。由此,待定点的α值可以在没有明确估计该像素点前景和背景颜色的情况下以封闭的形式求解。
封闭式抠图方法提出的拉普拉斯矩阵被广泛地于各种抠图方法中。例如,K近邻抠图(KNN matting,2012)[5]就是通过在特征空间取k个最邻近点计算得拉普拉斯矩阵计算α值,这种非局部抠图关注于可以处理更稀疏的trimap,甚至不需要附加的约束条件输入,直接通过图像自身的前景与背景属性的区别来进行分割。
贝叶斯算法基于图像局部颜色一致性的假设前提,封闭式抠图预先假设了颜色线性模型,这两种经典方法都预先假设了颜色分布模型,考虑到颜色分布不一定服从一个确定的模型,2009年有学者提出了基于学习的抠图算法(learning based matting)[4],将抠图问题视为一个半监督的学习问题,以更通用的学习的方法拟合颜色模型求解α值,并且这种算法模型,除了颜色之外还可以融入其他图像特征。较早期的抠图算法中图像特征只考虑颜色,例如贝叶斯抠图(2003)和封闭式抠图(2006)采用的图像特征是颜色,K近邻抠图(2012)采用的特征是HSV颜色和像素点坐标两种[5],随着抠图算法的发展,算法模型中渐渐融入其他图像特征。例如2017年Chao L[9]设计了一个新的特征,称为SUMD特征,以增加像素识别能力。这种特征是一种纹理特征,功能是使具有相似纹理的像素点具有相似的特征值。
传统alpha matting 方法通常只使用低层次的特征,基于深度学习的算法可以考虑更高层次的图像特征,并且可以通过创建大型图像数据集来自动优化算法。2017年Xu N等 [7]提出一种基于深度学习的新抠图算法,使用的CNN模型分为两个阶段:第一阶段是深卷积编码器,将原图和对应的trimap图作为输入,预测图像的α;第二阶段是一个小型卷积神经网络,作用是对第一个网络的输出进行精修优化。由于CNN网络可以捕捉到更高阶的图像结构和语义特征,并且可以通过大数据集进行优化,基于深度学习的抠图方法可以更好的适用于真实图像。
三、抠图公式-图像去雾
图像去雾的研究算法有很多,但是主要分为两类,基于图像增强的去雾算法和基于图像复原的去雾算法。基于图像增强的去雾算法主要是通过去除图像的噪声,提高图像的对比度,从而恢复出无雾清晰图像。而基于图像复原的去雾算法,主要是采用雾化图像模型。
2009年何凯明[14]提出暗通道去雾算法,将抠图算法应用到图像去雾算法中,以优化透射率计算。何的暗通道去雾算法是基于图像复原的去雾算法,采用雾化图像模型,其数学表达为:
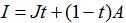
其中I(x)为观测到的雾化图像,J(x)是景物的实际图像,t(x)是透射率,A 为大气光成分。

图像去雾的目标就是从I(x)中恢复J(x) 、A、 t(x),在雾化图像模型中,大气光成分A虽然是未知量,但一般情况下,它是一个三通道强度值均接近于255的全局常量,唯一的未知是散射率t(x),而在求得t(x)的情况下,可以很容易恢复出实际图像J。
雾化图像模型与抠图公式数学表达形式是一样的,J、A、t分别与前景F、背景B、透明度通道α对应。何参考封闭式抠图[3]的代价函数提出去雾算法透射率的代价函数:
E(t) = tTLt
其中L为拉普拉阿斯矩阵,与封闭式抠图[3]中的拉普拉斯矩阵有着相似的形式,这样就可以采用图像软抠图的方法,对计算得到的透射率图t(x)进行精细优化。
采用封闭式抠图算法优化图像去雾透射率的方法计算速度较慢,为了解决这个问题,2013年何凯明[15]提出了一种新型的图像滤波方法——引导滤波器,将封闭式抠图算法应用在图像滤波中。
参考文献
[1] T. Duff, T. Porter. Compositing Digital Images[C]//Proceedings of the 11th Annual Conference on Computer Graphics and Interactive Techniques. 1984:253–259.
[2] Chuang Y Y, Curless B, Salesin D H, et al. A Bayesian approach to digital matting[C]// IEEE Computer Society Conference on Computer Vision & Pattern Recognition. 2003.
[3] Levin A , Lischinski D , Weiss Y. A Closed Form Solution to Natural Image Matting[C]// null. IEEE Computer Society, 2006:61-68.
[4] Zheng Y , Kambhamettu C . Learning based digital matting[C]// 2009 IEEE 12th International Conference on Computer Vision (ICCV). IEEE Computer Society, 2009.
[5] Chen Q , Li D , Tang C K . KNN Matting[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2013, 35(9):2175-2188.
[6] He K, Rhemann C, Rother C, et al. A global sampling method for alpha matting[J]. 2011.
[7] Xu N , Price B , Cohen S , et al. Deep Image Matting[J]. 2017.
[8] He K , Rhemann C , Rother C , et al. A global sampling method for alpha matting[J]. 2011.
[9] Chao L, Ping W, Zhu X, et al. Three-layer graph framework with the sumD feature for alpha matting[J]. Computer Vision & Image Understanding, 2017, 162:S1077314217301236.
[10] 姚桂林. 数字图像抠图关键技术研究[D].哈尔滨工业大学,2013.
[11] 杨仙魁. 闭合型抠图的研究与应用[D].云南大学,2013.
[12] 崔兆华,高立群,马红宾,李洪军.改进alpha-matting算法及其在军事红外目标提取中的应用[J].渤海大学学报(自然科学版),2013,34(02):225-231+95.
[13] Al Y Y B E. Interactive Graph Cuts for Optimal Boundary & Region Segmentation of Objects in N-D Images[J]. Iccv, 2001, 1:105-112.
[14] He K, Jian S, Tang X. Single image haze removal using dark channel prior[C]// IEEE Conference on Computer Vision & Pattern Recognition. 2009.
[15] He K, Sun J, Tang X. Guided Image Filtering[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2013, 35(6):1397-1409.
以上是关于深度学习之图像抠图 Image Matting算法调研的主要内容,如果未能解决你的问题,请参考以下文章
paper 116:自然图像抠图/视频抠像技术梳理(image matting, video matting)
基于阿里Semantatic Human Matting算法,实现精细化人物抠图