Python(黄金时代)——正则与简单web服务器
Posted 程序猿知秋
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python(黄金时代)——正则与简单web服务器相关的知识,希望对你有一定的参考价值。
正则表达式
re模块
-
在 Python中,可以通过使用 re 模块的正则表达式来匹配字符串
语法
import re
# 使用match方法进行匹配操作
result=re.match(正则表达式,要匹配的字符串)
# 如果上面匹配到数据的话,要以使用group方法来提取数据
result.group()单个字符匹配规则
| 字符 | 功能 |
| . | 匹配任意1个字符(除了\\n) |
| [ ] | 匹配 [ ] 中列举的字符 |
| \\d | 匹配数字,即 0~9 |
| \\D | 匹配非数字 |
| \\s | 匹配空白字符,即 空格、tab键 |
| \\S | 匹配非空白 |
| \\w | 匹配单词字符,即 a~z 、A~Z、0~9、_、中文 |
| \\W | 匹配非单词字符 |
多个字符匹配规则
| 字符 | 功能 |
| * | 匹配前一个字符出现0次或无限次,即可有可无 |
| + | 匹配前一个字符出现1次或者无限次,即 至少1次 |
| ? | 匹配前一个字符出现0次或1次,即 要么1次,要么没有 |
| m | 匹配前一个字符出现m次 |
| m,n | 匹配前一个字符出现从m到n次 |
匹配分组
| 字符 | 功能 |
| | | 匹配左右任意一个表达式 |
| (ab) | 将括号中的字符作为一个分组 |
| \\num | 引用分组 num匹配到字符串 |
| (?P<name>) | 分组起别名 |
| (?P=name) | 引用别名为name分组匹配到的字符串 |
示例
import re
# 匹配单个字符
str_content="生化危机2"
t1=re.match(r"生化危机\\d",str_content)
print(t1.group())
# 匹配多个字符
str_content="孙悟空的手机是:13388888888"
t1=re.match(r"孙悟空的手机是:\\d1,11",str_content)
print(t1.group())
# 分组, 匹配邮箱,126、qq、163邮箱都可以, 邮箱中的 .需要使用 \ 转义
str_content="孙悟空的邮箱是:sunwukong@163.com"
t1=re.match(r"孙悟空的邮箱是:\\w+@(126|163|qq)\\.com",str_content)
print(t1.group())
re模块的高级用法
-
search、findall、sub、split
示例
# search 用法
str_content="孙悟空会72变"
t1=re.search(r"\\d+",str_content)
print(t1.group())
# 输出结果:72
# findall 用法
str_content="孙悟空会72变,猪八戒会36变,二郎神会36变"
t1=re.findall(r"\\d+",str_content)
print(t1)
# 输出结果:['72', '36', '36']
# sub 将匹配到的字符串进行替换
str_content="孙悟空会 36 变"
t1=re.sub(r"\\d+","72",str_content)
print(t1)
# 输出结果:孙悟空会 72 变
# split 根据匹配切割字符串,返回一个字符列表
str_content="孙悟空,猪八戒,沙和尚"
t1=re.split(r",",str_content)
print(t1)
# 输出结果:['孙悟空', '猪八戒', '沙和尚']注:Python 中字符串前面加上 r 表示原生字符串
-
与大多数编程语言相同,正则表达式里使用 "\\" 作为转义字符,这就可能会有反斜杠困扰。 如果你需要匹配的文本中有两个 "\\" ,那么使用正则表达式里面就需要使用四个 "\\" (即 "\\\\\\\\")
str_content="c:\\\\a"
# 不使用 r
t1=re.match("c:\\\\\\\\a",str_content)
print(t1.group())
# 使用 r
t1=re.match(r"c:\\\\a",str_content)
print(t1.group())输出结果

web服务器
http协议
- 在Web应用中,服务器把网页传递给浏览器,实际上就是把网页的html代码发送给浏览器,让浏览器显示出来,而浏览器和服务器之间的传输协议是HTTP
-
HTTP 是在网络上传输html的协议,用于浏览器和服务器之间的通信
-
HTML 是一种用来定义网页的文本,编写网页的代码就是html语言
-
访问百度的示例
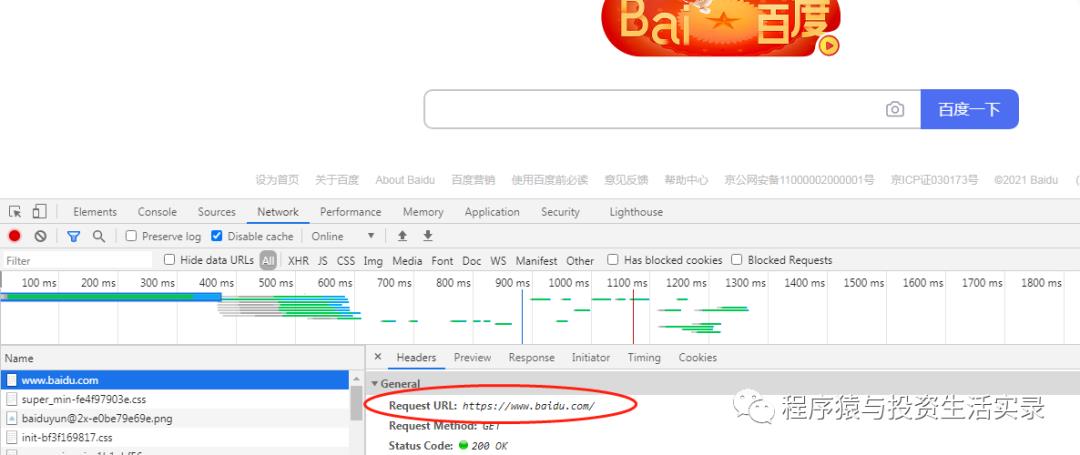
简单web服务器
import socket
def main():
# 创建tcp套接字
so_server=socket.socket(socket.AF_INET,socket.SOCK_STREAM)
# 绑定端口
so_server.bind(("",33333))
# 监听套接字
so_server.listen(128)
# 等待新客户端接连
new_socket,client_addr=so_server.accept()
#接收浏览器发过来的请求
request=new_socket.recv(1024)
print(request)
# 发送给浏览器数据
content="HTTP/ 1.2 xxx\\r\\n"
content+='\\r\\n'
content+="hello world!!"
new_socket.send(content.encode("utf-8"))
# 关闭
new_socket.close()
so_server.close()
if __name__ == '__main__':
main()请求示例
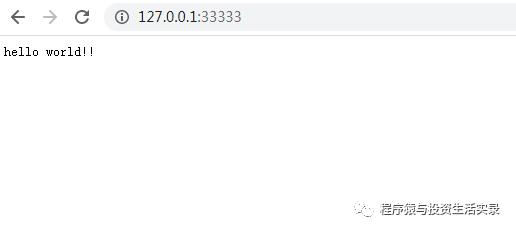
程序猿与投资生活实录已改名为 程序猿知秋,WX同款,欢迎关注!
使用PuTTy在CentOS下安装web.py与简单的文件传输
两周前,出于帮朋友忙的目的,尝试了一下微信公众号的菜单自定义与自动回复功能的实现,成了。
两周后,需要将代码转移至朋友新购的服务器上,发现基本操作全忘记了,麻瓜!所以记一笔,希望也能对大家也有帮助。
腾讯云买的服务器,系统为CentOS 7.2 64位,自带python2.75。
第一步,安装web.py
网上推荐的用这个 easy install 下载管理 python 的包,所以先安装 easy install:
yum install python-setuptools
安装完成,输入:
easy_install web.py
第二步,安装libxml2, libxslt, lxml python
yum install + 名称
我试过后发现libxml2是已经存在的。
第三步,测试web.py是否安装成功
附上教程里的测试用main.py。
import web urls = ( \'/wx\', \'Handle\', ) class Handle(object): def GET(self): return "hello, this is a test" if __name__ == \'__main__\': app = web.application(urls, globals()) app.run()
在终端输入sudo python main.py 80 服务开启了,在浏览器中输入ip+/wx,网页输出hello, this is a test
表示测试成功,运行正常。
第四步,完成
需要注意的是,Putty的Session关闭会导致服务停止,百度得不挂断运行命令, nohup :
sudo nohup python main.py 80 这样会生成一个nohup.out文件,记录Console的内容。
PS:因为不熟悉Linux,更不熟悉SSH,涉及到文件转移时,选择了简单的psftp.exe。
open in + ip ->login
put + filename 向服务器上传文件,默认到root目录。
get + filename 从服务器上下载,cd指令进入目录为所欲为。
附图一张(一个一个复制,惨!),下载地址一个(putty,psftp一系列exe)。

下载地址:https://www.chiark.greenend.org.uk/~sgtatham/putty/latest.html
以上是关于Python(黄金时代)——正则与简单web服务器的主要内容,如果未能解决你的问题,请参考以下文章