大数据-消息队列-Kafka:Producer(生产者)发送消息采用的是异步发送两个线程:main线程和Sender线程线程共享变量:双端队列RecordAccumulator
Posted u013250861
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据-消息队列-Kafka:Producer(生产者)发送消息采用的是异步发送两个线程:main线程和Sender线程线程共享变量:双端队列RecordAccumulator相关的知识,希望对你有一定的参考价值。
一、生产者消息发送流程
1、发送原理
Kafka的Producer发送消息采用的是异步发送的方式。
在消息发送的过程中,涉及到了两个线程:main线程和Sender线程,以及一个线程共享变量:RecordAccumulator。
- ①main线程中创建了一个双端队列RecordAccumulator,将消息发送给RecordAccumulator。
- ②Sender线程不断从RecordAccumulator中拉取消息发送到Kafka broker。
2、生产者重要参数列表
大数据消息中间件之Kafka02
一.Kafka生产者
1.1什么是生产者
生产者就是producer,负责生产消息,并把消息放入到队列中
1.2Kafka分区策略
分区原因
- 方便在集群中扩展,因为每个topic中有多个partition,partition可以适应相对应的机器,从而适应任意大小的数据
- 提高并发度,可以以partition为单位进行读写
分区原则
- 首先将生产者producer生产的数据封装成一个ProducerRecord 对象

- 指明 partition 的情况下,直接将指明的值作为 partition 值;
- 没有指明 partition 值但有 key 的情况下,将 key 值的 hash 值与 topic 的 partition 数进行取余得到 partition 值;
- 既没有 partition 又没有 key 值的情况下,第一次调用时随机生成一个整数(后面每次调用在这个整数上自增),将这个值与 topic 可用的 partition 总数取余得到 partition 值,也就是常说的 round-robin (轮询)算法。
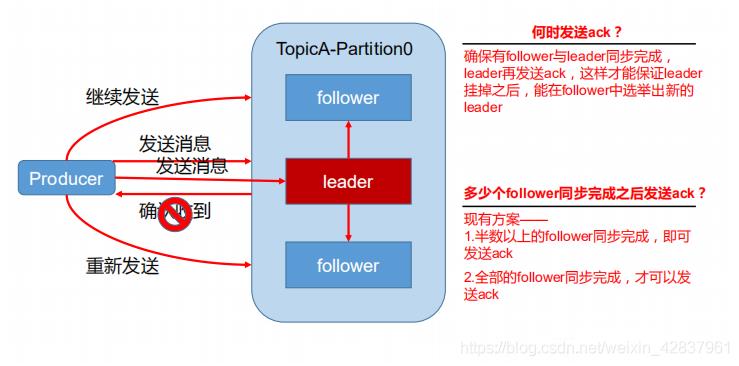
如何保证数据传输的可靠性
为保证 producer 发送的数据,能可靠的发送到指定的 topic,topic 中的每个 partition 收到 producer 发送的数据后,都需要向 producer 发送 ack (acknowledgement 确认收到),如果 producer 收到 ack,就会进行下一轮的发送,否则重新发送数据。
二.消费者
消费方式
consumer 采用 pull(拉)模式从 broker 中读取数据。
push(推)模式很难适应消费速率不同的消费者,因为消息发送速率是由 broker 决定的。它的目标是尽可能以最快速度传递消息,但是这样很容易造成 consumer 来不及处理消息。典型的表现是拒绝服务以及网络拥塞。而 pull 模式则可以根据 consumer 的消费能力以适当的速率消费消息。
pull 模式不足之处是, 如果 kafka 没有数据,消费者可能陷入循环中,一直返回空数据。针对这一点,kafka 的消费者在消费数据时会传入一个时长参数 timeout,如果当前没有数据提供消费,consumer 会等待一段时间之后再返回,这段时长即 timeout。
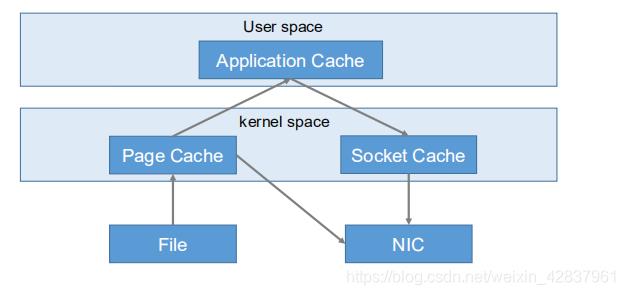
Kafka高效读取数据
- 顺序写磁盘
Kafka 的 producer 生产数据,要写到 log 文件中,写的过程是一直追加到文件末尾,为顺序写。顺序写之所以快,是因为其省去了大量磁头寻址时间。 - 零复制技术
下一篇讲述Java操作Kafka
以上是关于大数据-消息队列-Kafka:Producer(生产者)发送消息采用的是异步发送两个线程:main线程和Sender线程线程共享变量:双端队列RecordAccumulator的主要内容,如果未能解决你的问题,请参考以下文章
Kafka消息队列大数据实战教程-第四篇(Kafka客户端Producer API)
Kafka消息队列大数据实战教程-第四篇(Kafka客户端Producer API)
大数据技术之_10_Kafka学习_Kafka概述+Kafka集群部署+Kafka工作流程分析+Kafka API实战+Kafka Producer拦截器+Kafka Streams