CPU 架构SMP/NUMA,调优
Posted xiaoshiwang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了CPU 架构SMP/NUMA,调优相关的知识,希望对你有一定的参考价值。
CPU 架构SMP/NUMA,调优
SMP:全称是“对称多处理”(Symmetrical Multi-Processing)技术 。
是指在一个计算机上汇集了一组处理器(多CPU),各CPU之间共享内存以及总线。
弱点:CPU变多后,但是内存和内存控制器只有一个,CPU是通过内存控制器访问内存的,所以多个CPU对内存控制器就会产生竞争,为了避免竞争就出现了NUMA架构。
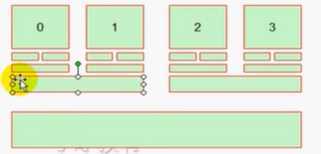
NUMA:Non Uniform Memory Access
各个CPU有自己专用的内存(学名叫node),但是也可以访问别的CPU的专业内存,这时性能就会下降。
Linux下NUMA相关的命令
numastat:查看节点的状态。
可以看到自己CPU下的进程命中了自己的内存(node)多少次,没命中多少次,如果没命中的次数多了怎么办?就要强制把这进程绑定到自己的CPU上。
经典的应用场景:把nginx的worker进程绑定到numa架构下的特定的CPU上,性能会大幅度提升。
numactl:可以实现把进程绑定到特定的CPU上
但是,当机器重新启动后,绑定就失效了。如何解决呢,使用numad
numad:守护进程
numademo
非numa架构,如何把进程绑定到特定的CPU上呢,使用taskset
$ taskset -p -c 0,1,2-4,5,9 1234上面命令的意思:把进程ip为1234的进程,绑定到0号,1号,2号,3号,4号,5号,9号CPU上。
这只是个例子,一般都绑定到1个CPU上,但是当系统重启后,还需要重新绑定,因为pid也变了。
Nginx比较厉害,可以配置哪个worker绑定到哪个CPU,事先写到配置nginx的配置文件里。
用上面的方法可以让某个进程专门让某几个CPU执行,但是这几个CPU除了要执行这个进程外,还要执行内核,怎么避免不让这些CPU不执行内核,只执行这个进程呢?
解决办法:假设有6个CPU,系统启动时,只让2个CPU执行内核的指令,其余4个不让执行内核指令。
编辑/etc/default/grub 文件,在 quiet splash ?后面加上 ?isolcpus=2,3。回到终端执行update-grub 。其将自动依照刚才编辑的配置文件(/etc/default/grub)生成为引导程序准备的配置文件(/boot/grub/grub.cfg)
即便预留了CPU,被预留的CPU不处理内核的指令了,但是也要处理中断啊,那么如何把中断也不让这些CPU处理呢?
修改/proc/irq/
$ echo cpu_mask > /proc/irq/<irq_num>/smp_affinitycpu_mask:用比特位表示。
0001:代表1号CPU
0011:代表1号和2号CPU
0101:代表1号和3号CPU非numa架构,如何判断要把哪些进程绑定到特定CPU上呢?如何判断哪些线程被频繁的切换了呢?有如下命令
sar -q
使用sar之前要配置一下
1,修改:/etc/default/sysstat, 将 ENABLED=“false“ 改为ENABLED=“true“
2,执行:sudo /etc/init.d/sysstat restart
top
w
uptime
wmstat 1 5
下面的是查看CPU的使用率
mpstat 1 2
sar -P 1 2
iostat -c 1
cat /proc/stat命令iostat -c 1的截图,含义查看CPU的占用率
- %user:用户进程的CPU占用率
- %system:内核的CPU占用率
- %iowait:io处理的CPU占用率
- %steal:虚拟机的CPU占用率
- %idle:CPU空闲
ys:~$ iostat -c 1
Linux 4.15.0-20-generic (ys-VirtualBox) 2019年09月27日 _x86_64_ (1 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
0.26 0.03 0.08 0.05 0.00 99.57
avg-cpu: %user %nice %system %iowait %steal %idle
0.00 0.00 0.00 0.00 0.00 100.00
avg-cpu: %user %nice %system %iowait %steal %idle
0.00 0.00 0.00 0.00 0.00 100.00
avg-cpu: %user %nice %system %iowait %steal %idle
0.00 0.00 0.00 0.00 0.00 100.00命令【dstat】比较强大,可以直观的得到如下信息:
--top-bio
show most expensive block I/O process
显示最消耗blockI/O的进程
--top-bio-adv
show most expensive block I/O process (incl. pid and other stats)
显示最消耗blockI/O的进程
--top-childwait
show process waiting for child the most
显示等待子进程时间最长的父进程
--top-cpu
show most expensive CPU process
显示最消耗CPU的进程
--top-cpu-adv
show most expensive CPU process (incl. pid and other stats)
显示最消耗CPU的进程
--top-cputime
show process using the most CPU time (in ms)
显示最消耗CPU时间片的进程
--top-cputime-avg
show process with the highest average timeslice (in ms)
显示最消耗CPU时间片的进程
--top-int
show most frequent interrupt
显示最经常发生的中断信号
--top-io
show most expensive I/O process
显示最消耗I/O的进程
--top-io-adv
show most expensive I/O process (incl. pid and other stats)
显示最消耗I/O的进程
--top-latency
show process with highest total latency (in ms)
显示等待时间最长的进程
--top-latency-avg
show process with the highest average latency (in ms)
显示等待时间最长的进程
--top-mem
show process using the most memory
显示使用内存最多的进程命令【sar -w 1(秒为单位)】比较强大,可以直观的得到进程在指定秒数里的平均切换次数
c/c++ 学习互助QQ群:877684253

本人微信:xiaoshitou5854
以上是关于CPU 架构SMP/NUMA,调优的主要内容,如果未能解决你的问题,请参考以下文章