Spark集群-Standalone 模式
Posted zyzdisciple
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark集群-Standalone 模式相关的知识,希望对你有一定的参考价值。
Spark 集群相关
来源于官方, 可以理解为是官方译文, 外加一点自己的理解. 版本是2.4.4
本篇文章涉及到:
- 集群概述
- master, worker, driver, executor的理解
- 打包提交,发布 Spark application
- standalone模式
- SparkCluster 启动 及相关配置
- 资源, executor分配
- 开放网络端口
- 高可用(Zookeeper)
名词解释
| Term(术语) | Meaning(含义) |
|---|---|
| Application | 用户构建在 Spark 上的程序。由集群上的一个 driver 程序和多个 executor 组成。 |
| Driver program | 该进程运行应用的 main() 方法并且创建了 SparkContext。 |
| Cluster manager | 一个外部的用于获取集群上资源的服务。(例如,Standlone Manager,Mesos,YARN) |
| Worker node | 任何在集群中可以运行应用代码的节点。 |
| Executor | 一个为了在 worker 节点上的应用而启动的进程,它运行 task 并且将数据保持在内存中或者硬盘存储。每个应用有它自己的 Executor。 |
| Task | 一个将要被发送到 Executor 中的工作单元。 |
| Job | 一个由多个任务组成的并行计算,并且能从 Spark action 中获取响应(例如 save,collect); 您将在 driver 的日志中看到这个术语。 |
| Stage | 每个 Job 被拆分成更小的被称作 stage(阶段)的 task(任务)组,stage 彼此之间是相互依赖的(与 MapReduce 中的 map 和 reduce stage 相似)。您将在 driver 的日志中看到这个术语。 |
概述
参考链接: Cluster Mode Overview
中文链接: 集群模式概述
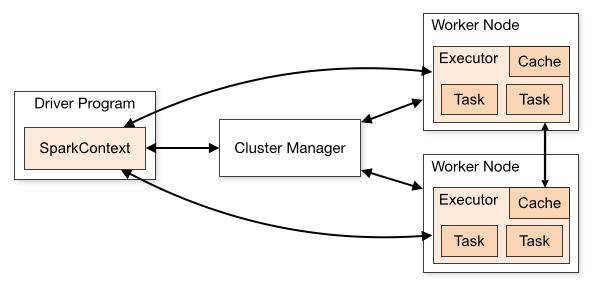
Spark Application 在集群上作为独立的进程组来运行,在 main程序(称之为 driver 程序) 中通过 SparkContext 来协调。
具体来说,为了运行在集群上,SparkContext 可以连接至几种类型的 Cluster Manager(既可以用 Spark 自己的 Standlone Cluster Manager,或者 Mesos,也可以使用 YARN),用以在 applications 之间 分配资源。
一旦连接上,Spark 获得集群中节点上的 Executor,这些进程可以运行计算并且为应用存储数据。
接下来,它将发送 application 的代码(通过 JAR 或者 Python 文件定义传递给 SparkContext)至 Executor。 而这一点大概也是 在 work目录下, 每个application中都有对应的 jar包的原因. 最终,SparkContext 将发送 Task 到 Executor 以运行。
有这么几点要注意的地方:
每个application拥有它自身的 executor 进程. 它们会保持在整个 application 的生命周期中并且在多个线程中运行 task. 这样做的优点是 可以将 application 之间相互隔离, 无论是在 任务调度 层面(即driver, driver 负责任务调度.) 又或者是 executor的层面. 这意味着 如果没有外部存储机制, 各个 application之间是无法进行数据共享的.
Spark并不关心究竟是 基于怎样的 集群模式, 它只关心 能够获取自身的 executor进程, 并且彼此之间可以相互通信即可.
Driver 程序必须在自己的生命周期内监听和接受来自它的 Executor 的连接请求。(配置: spark.driver.port) 同样的, 对于 worker node 而言, driver 程序也必须能够从网络中连接到.
因为 driver 负责在 整个集群上 调度任务, 因此能够与 worker node 处于同一局域网下是更优的选择(否则的话, 网络通信可能就成为了 整个Spark最大的时间开销)。如果你不喜欢发送请求到远程的集群,倒不如打开一个 RPC 至 driver 并让它就近提交操作而不是从很远的节点上运行一个 driver。
在这里解决这样一个比较问题: master, worker, driver, executor之间是什么样的关系?
可以参考:
上面的博客是我看了几篇之后, 觉得描述的比较准确的.
那么一点点来说: spark的application 运行需要一个环境, 也即spark本身.
而往往我们使用的就是集群环境, 集群环境中有多台机器, 多个进程, 这就需要一个管理器, 管理 多个master 和 多个 worker节点. 这个就是 cluster manager. 而我们直接通信的对象, 也就是 application 直接通信的对象 就是 master. 由master 来告诉我们 application 的可用资源在哪里.
一个集群中, 可以运行多个application.
当我们提交application之后, 会接入master, master分配给我们资源, 也即executor, main程序所在的进程. 就被称作是 driver. driver 分配任务, 协调各个executor, 运行各个 task的就是 executor.
注意在这里并没有指定driver究竟会运行在哪个节点上.
与选取的模式有关.
而master呢? 在master中注册 application, driver, worker这三种资源, 而 executor资源是注册在 driver中的, 新的worker加入, driver状态变化, worker状态变化 都会通告给 master 以重新协调资源.
我们会发现, executor在分配之后是与master无关的, 程序是运行在executor中的, driver并不一定运行在master中, 因此即使master挂掉, 程序也并不是就不能够运行了.
master worker是集群中的物理资源分配, driver , executor 是对物理资源的使用. 在申请新的资源时, 需要向master申请, 在任务调度运行时, 则无需向master通报.
其实仔细想想, 在大多数集群的处理中, 都是采用这种模式, cluster manager负责集群的资源管理, 相互通信, master节点负责资源调度, 资源状态变更处理, 而 application 是独立于它们运行的, 一旦获取到自己需要的资源, 就不和master进行通信了.
Cluster Manager 类型
系统目前支持三种 Cluster Manager:
Standalone – 包含在 Spark 中, 简单易使用。
Apache Mesos – 一个通用的 Cluster Manager,它也可以运行 Hadoop MapReduce 和其它服务应用。
Hadoop YARN – Hadoop 2 中的 resource manager(资源管理器)。
Kubernetes (experimental)
Nomad: 存在第三方的项目(并非受到Spark项目支持的) 可以添加对应的集群支持.
提交应用程序
官方链接: Submitting Applications
中文链接: Submitting Applications
在 Spark的 bin 目录中的spark-submit 脚本 用于 在集群上启动应用程序。它可以通过一个统一的接口使用所有 Spark 支持的 cluster managers,所以您不需要专门的为每个cluster managers配置您的应用程序。
打包
打包的时候, 需要将程序自身的jar与 程序的 依赖jar一起进行打包, 这一点可以通过maven 的 shade / assembly 来实现. 在 项目中 将 spark 和 hadoop 的包 范围权限定义为 provided即可.它们不需要被打包,因为在运行时它们已经被 Cluster Manager 提供了.
启动
打包完成之后, 就可以通过 bin/spark-submit 进行提交了.
这个脚本负责设置 Spark 和它的依赖的 classpath,并且可以支持 Spark 所支持的不同的 Cluster Manager 以及 deploy mode(部署模式):
./bin/spark-submit --class <main-class> --master <master-url> --deploy-mode <deploy-mode> --conf <key>=<value> ... # other options
<application-jar> [application-arguments]常用的参数有:
- --class:您的应用程序的入口点(例如 org.apache.spark.examples.SparkPi)
- --master:集群的 master URL(例如 spark://23.195.26.187:7077)
- --deploy-mode:是在 worker 节点(cluster)上还是在本地作为一个外部的客户端(client)部署您的 driver(默认:client)
- --conf:按照 key=value 格式任意的 Spark 配置属性。对于包含空格的 value(值)使用引号包 “key=value” 起来。
- application-jar:包括您的应用以及所有依赖的一个打包的 Jar 的路径。该 URL 在您的集群上必须是全局可见的,例如,一个 hdfs:// path 或者一个 file:// 在所有节点是可见的。
- application-arguments:传递到您的 main class 的 main 方法的参数,如果有的话。
其中 参数顺序并没有严格要求, 但要求 jar路径 必须在倒数第二 或 最后一个参数位置(如果不通过 application-jar 来指定的话).
有一些特定于所使用的集群管理器的可用选项 。例如,对于具有部署模式的Spark standalone Cluster,您还可以指定--supervise以确保驱动程序在非零退出代码失败的情况下自动重新启动。要枚举所有可用的此类选项,请使用来spark-submit运行它--help.
其中 StandaloneCluster的 可配置参数在稍后会有所说明.
Master URLS
| Master URL | Meaning |
|---|---|
| local | 使用一个线程本地运行 Spark(即,没有并行性)。 |
| local[ K ] | 使用 K 个 worker 线程 在本地运行 Spark(理想情况下,设置这个值的数量为你的机器的 core 数量)。 |
| local[K, F] | 使用 K 个 worker 线程本地运行 Spark并允许最多失败 F次(对于任意job失败会进行重试, 重试次数等 F - 1) |
| local[ * ] | 使用与机器的 逻辑 core数量相等的 worker线程. |
| local[*, F] | 使用与机器的 逻辑 core数量相等的 worker线程. 并允许最多失败 F次。 |
| spark://HOST:PORT | 连接至给定的 Spark standalone cluster master. master。该 port(端口)必须有一个作为您的 master 配置来使用,默认是 7077。 |
| spark://HOST1:PORT1,HOST2:PORT2 | 连接至给定的 Spark standalone cluster with standby masters with Zookeeper。该列表必须包含由zookeeper设置的高可用集群中的所有master主机。该 port(端口)必须有一个作为您的 master 配置来使用,默认是 7077。 |
| mesos://HOST:PORT | 连接至给定的 Mesos 集群。该 port(端口)必须有一个作为您的配置来使用,默认是 5050。或者,对于使用了 ZooKeeper 的 Mesos cluster 来说,使用 mesos://zk://...。使用 --deploy-mode cluster,来提交,该 HOST:PORT 应该被配置以连接到 MesosClusterDispatcher。 |
| yarn | 以 client 或 cluster 模式 连接至一个 YARN cluster, 模式取决于 --deploy-mode. 该 cluster 的位置将根据 HADOOP_CONF_DIR 或者 YARN_CONF_DIR 变量来找到。 |
| k8s://HOST:PORT | 以集群模式 连接至 k8s 集群, 在目前版本不支持设定客户端模式(在将来会提供), HOST PORT 指向对应 k8s API服务, 默认使用 TSL连接. 如果不想使用 TSL, 需要强制指定 k8s://http://HOST:PORT. |
配置
spark-submit 脚本可以从一个 properties 文件加载默认的 Spark configuration values。默认情况下,它将从 Spark 目录下的 conf/spark-defaults.conf 读取配置.
加载默认的 Spark 配置,可以在提交时省略一部分参数, 例如,如果 spark.master 属性被设置了,您可以在 spark-submit 中安全的省略 --master 配置. 一般情况下,明确设置在 SparkConf 上的配置值的优先级最高,然后是传递给 spark-submit的值,最后才是 default value(默认文件)中的值。
如果你不是很清楚其中的配置设置来自哪里,您可以通过使用 --verbose 选项来运行 spark-submit 打印出细粒度的调试信息.
高级依赖管理
并非只有把所有的需要的jar包都打包在一起这一种方式.
通过 --jars 选项包括的应用程序的 jar 和任何其它的 jar 都将被自动的传输到集群. --jars 后面提供的 URL 必须用逗号分隔。该列表会被包含到 driver 和 executor 的 classpath 中。 --jars 不支持目录的形式。
URL有以下几种方式:
file: 绝对路径和 file:/ URI 通过 driver 的 HTTP file server 提供服务,并且每个 executor 会从 driver 的 HTTP server 拉取这些文件。
hdfs:, http:, https:, ftp: 指定下载 文件的 URI.
local: 一个用 local:/ 开头的 URL, 要求作在每个 worker 节点上都存在。这样意味着没有网络 IO 发生,并且非常适用于那些已经被推送到每个 worker 或通过 NFS,GlusterFS 等共享的大型的 file/JAR。
注意: JARS 和 files 被复制到 每个SparkContext 的 executor 节点 的 工作目录. 在长时间的运行中, 所需要的空间会逐渐加大, 因此去清理掉这些文件. 在 YARN 模式下, 可以自动清理文件, 而在 standalone模式下, 需要在配置中加入spark.worker.cleanup.appDataTtl 用以自动清理.
Standalone 模式
官方文档: Spark Standalone Mode
中文文档: Spark Standalone Mode
由于在我们目前的项目中, 采用的就是 standalone模式, 因此只介绍这一种模式.
Spark 提供了一个简单的 standalone 部署模式。你可以手动启动 master 和 worker 来启动 standalone 集群.
安装 Spark Standalone 集群,只需要将编译好的版本部署在集群中的每个节点上。
先回答一个问题:
在当前模式下, driver 是选取 几个worker中的一个来运行相关进程, 并非是在master节点.
启动Spark Cluster
通常来说, 我使用的启动命令为:
${SPARK_HOME}/sbin/start-all.sh
会 加载配置文件, 启动 spark master, spark slaves.
停止的时候, 也可以采用 stop-all.sh
注意: 这些脚本必须在您想要运行 Spark master 的机器上执行,而不是您本地的机器。
当然可以加入一部分配置文件, 指定参数配置:
比较重要的或有趣的我会标注出来.
conf/spark-env.sh
可以在复制 conf/spark-env.sh.template > spark-env.sh 中设置环境变量来进一步配置集群。
可接收参数有:
环境变量 含义 SPARK_MASTER_HOST 绑定 master 到一个指定的 hostname 或者 IP 地址 SPARK_MASTER_PORT 在不同的端口上启动 master(默认:7077) SPARK_MASTER_WEBUI_PORT master的 web ui (默认: 8080) SPARK_MASTER_OPTS 仅应用到 master 上的配置属性,格式是 "-Dx=y"(默认是:none), 可用参数在下面会提到. SPARK_LOCAL_DIRS Spark 中 "scratch" space(暂存空间)的目录,包括 map 的输出文件 和 存储在磁盘上的 RDDs, 我们知道内存溢出会根据策略, 有可能存储在磁盘上. 这必须在你的系统中的一个快速的(不太明白这个快速的, 是什么意思?),本地的磁盘上。这也可以是逗号分隔的不同磁盘上的多个目录的列表。 SPARK_WORKER_CORES 机器上 所有 Spark 应用程序可以使用的的 cores 的总数.(默认:全部的核可用) SPARK_WORKER_MEMORY 机器上的 所有的 spark applications 允许使用的 总的内存, 默认是 机器内存 - 1GB; 而单个application的内存配置是由 spark.executor.memory 所决定的. SPARK_WORKER_PORT spark worker的端口, 默认是 随机 SPARK_WORKER_WEBUI_PORT spark worker 的 web ui 端口, 默认是 (8081) SPARK_WORKER_DIR 运行application所在的路径, 这个目录中包含日志和暂存空间(default:SPARK_HOME/work) SPARK_WORKER_OPTS 与 SPARK_MASTER_OPTS 类似, 不过是应用于 worker SPARK_DAEMON_MEMORY 分配给 Spark master 和 worker 守护进程的内存。(默认: 1g) SPARK_DAEMON_JAVA_OPTS Spark master 和 worker 守护进程的 JVM 选项,格式是 "-Dx=y"(默认:none) SPARK_DAEMON_CLASSPATH Spark master 和 worker 守护进程的 classPath (default: none). SPARK_PUBLIC_DNS Spark master 和 worker 的公开 DNS 名称(不是很理解)。(默认:none) 注意: 启动脚本现在还不支持 Windows。要在 Windows 上运行一个 Spark 集群,需要手动启动 master 和 workers。
但是不知为何, 我在运行 start-all的时候, 出现了 master 已经启动, 但 worker不能启动的问题.
最终的解决方式是将 在 Spark-env.sh中加入
export JAVA_HOME=$JAVA_PATH才解决的这个问题, 因此 Spark-env.sh 不仅能够用来容纳所上述所提供的 部分参数, 还能够指定, 提供Spark所需要的环境变量, 如 JAVA_HOME, SCALA_HOME, PYTHON_HOME 等等.
SPARK_MASTER_OPTS 参数
属性名 默认值 含义 spark.deploy.retainedApplications 200 在 web ui上最大展示的 已经完成的 application数量. 超过限制的会被从UI中丢弃. spark.deploy.retainedDrivers 200 展示已完成的 drivers 的最大数量。旧的 driver 会从 UI 删除掉以满足限制。 spark.deploy.spreadOut true cluster mananger 是否将 多个 application 分配到不同的节点上 还是 尽量使用 越少的 节点越好(即整合操作). 默认true是分配到不同节点上. 对于数据在本地的 HDFS 文件中, 一般是尽量分离会比较好, 而对于 计算密集型 任务 来说, 使用尽量少的节点是 一种更好的选择. spark.deploy.defaultCores (infinite) 如果没有设置 spark.cores.max,在 Spark 的 standalone 模式下默认分配给应用程序的 cores(核)数。如果没有设置,application 将总是获得所有的可用核,除非application设置了 spark.cores.max。在共享集群中设置较低的核数,可用于防止用户 grabbing(抓取)整个集群. spark.deploy.maxExecutorRetries 10 executor 连续多次的最大失败次数, 一旦到达最大次数, cluster manager 将会 移除发生错误的 application. 如果 application 有任意正在运行的 executor 则永远不会移除. 如果一个应用程序经历过超过 spark.deploy.maxExecutorRetries 次的连续失败,在这期间没有executor成功开始运行,并且应用程序没有运行着的executor,然后 cluster manager 将会移除这个应用程序并将它标记为失败。如果要禁用功能的话, 设置为-1即可. spark.worker.timeout 60 master 接收 worker 心跳的最大时间间隔, 单位 秒. SPARK_WORKER_OPTS 参数
属性名 默认值 含义 spark.worker.cleanup.enabled false 允许定期清理 worker / application 目录. 仅在standalone模式有效,且仅对已经停止运行的 application有效. spark.worker.cleanup.interval 1800 (30 minutes) 在本地机器上,多久去检测并清理一次,以秒计数. spark.worker.cleanup.appDataTtl 604800 (7 days, 7 * 24 * 3600) 对于每一个worker, 允许目录存在的最大时间, 这应该取决于你磁盘 可分配的最大空间. 随着时间的推移, 这个工作目录会很快填满磁盘空间, 特别是如果您经常运行jobs. spark.storage.cleanupFilesAfterExecutorExit true 在executor退出之后自动清除 工作目录下的 non-shuffle 文件(例如: 临时文件, shuffle blocks, 缓存的 RDD/broadcast blocks, spill files, 等等) of worker directories following executor exits. 注意与 spark.worker.cleanup.enabled是不同的. 后者会清理所有超时的项目文件.仅在 standalone模式下有效.spark.worker.ui.compressedLogFileLengthCacheSize 100 对于压缩日志文件,只能通过未压缩文件来计算未压缩文件。Spark 缓存未压缩日志文件的文件大小。此属性控制缓存的大小. 要在 Spark 集群中运行一个应用程序,只需要简单地将 master 的 spark://IP:PORT URL.
要针对集群运行交互式 Spark shell,运行下面的命令:
./bin/spark-shell --master spark://IP:PORT可以通过指定 --total-executor-cores numCores 控制集群中使用的 总的 cores数量.
提交application
对于 standalone 集群, park 目前支持两种部署模式。在 client 模式下,driver 在与 client 提交应用程序相同的进程中启动。
在 cluster 模式下,driver 是集群中的某个 Worker 中的进程中启动,并且 client 进程将会在完成提交应用程序的任务之后退出,而不需要等待应用程序完成再退出。
如果应用程序是通过 Spark submit, application 会被 自动发送到所有的工作节点, 对于你所依赖的任何jar包, 可以通过 --jars 的方式传入, 多个jar之间用,分割. 但正如之前 高级依赖管理 中提到的, 并不支持目录形式.
standalone cluster 模式支持 自动重启 application, 如果程序是以 非零代码退出的话. 只需要在 submit的时候加入 --supervise 标识即可.如果您想杀死一个重复失败的应用程序,您可以使用如下方式:
./bin/spark-class org.apache.spark.deploy.Client kill <master url> <driver ID> 资源分配
standalone 集群模式当前只支持一个简单的跨应用程序的 FIFO 调度。然而,为了允许多个并发的用户,您可以控制每个应用程序能用的最大资源数。默认情况下,它将获取集群中的 all cores(核),这只有在某一时刻只允许一个应用程序运行时才有意义, 因为如果此时其他的核被占用, 自然无法获取资源, 运行程序, 此时是有多少核用多少核.
您可以通过 spark.cores.max 在 SparkConf 中设置 cores(核)的数量。例如:
val conf = new SparkConf()
.setMaster(...)
.setAppName(...)
.set("spark.cores.max", "10")
val sc = new SparkContext(conf)这样就不用担心一个application占用了集群所有的资源, 又因为在 FIFO 模式下, 导致其他application无法使用.
此外, 如果不想通过 spark.cores.max,也可以通过在集群的 master 进程中配置 spark.deploy.defaultCores 来修改的应用程序。通过添加下面的命令到 conf/spark-env.sh:
export SPARK_MASTER_OPTS="-Dspark.deploy.defaultCores=$value"
executor分配
每个executor的可使用 核心数 是 可配置的, 当 spark.executor.cores 被设置之后, 同一application的多个 executors 可能在同一台机器上运行, 在机器的 core 和 memory 资源充足的情况下.
否则 每个executor 会获取 所有的可用 core, 当然 和 资源分配中提到的一致, 这需要在每次任务调度期间, 每个worker上的单个 application 只有 一个 executor.
监控 & 日志
监控自然是:
SPARK_MASTER_WEBUI_PORT 默认8080
SPARK_WORKER_WEBUI_PORT 默认8081, 如果8081已经被占用, 则会顺延一位.
分别对应 master的web ui 和 worker的web ui
至于日志 则是在各个节点的 worker目录.
配置网络安全端口
通常来说, 一个 spark cluster 和 其服务 并不会放在公共网络上, 一般都运行在私有服务内, 并且只能在部署Spark的组织网络内访问.
对Spark服务使用的主机和端口的访问 应仅限于需要访问服务的 原始主机.
这对于standalone来说更为重要, 因为这种模式并不支持 自由的 网络资源控制.
可以参考链接:
同样的关键部分, 与外界交互的端口, 用特殊颜色标注:
| 起始地址 | 目标地址 | 默认端口 | 用户 | 配置 | 说明 |
|---|---|---|---|---|---|
| 浏览器 | standalone master | 8080 | WEBUI | spark.master.ui.port / SPARK_MASTER_WEBUI_PORT | 仅在 standalone模式使用 |
| 浏览器 | standalone Worker | 8081 | Web UI | spark.worker.ui.port | / SPARK_WORKER_WEBUI_PORT |
| Driver / Standalone Worker | Standalone Master | 7077 | driver提交任务到 cluster/worker加入 cluster Submit job to cluster | SPARK_MASTER_PORT | |
| 外部服务 | Standalone Master | 6066 | 通过 REST API的方式提交任务到集群中. | spark.master.rest.port | 需要spark.master.rest.enabled 设置为 enabled. 仅在集群模式下使用. |
| Standalone Master | Standalone Worker | (random) | 调度分配 executors | SPARK_WORKER_PORT | 设置为0则二十随机端口. 仅在 standalone模式下使用. |
| 浏览器 | application | 4040 | WebUI | spark.ui.port | |
| 浏览器 | 历史服务: Spark学习笔记-使用Spark History Server | 18080 | Web UI | spark.history.ui.port | 所有模式 |
| Executor / Standalone Master | Driver | (random) | 连接到 application 或 发现 executor状态变更 | spark.driver.port | 设置为0即是随机端口, 所有模式可用. |
| Executor / Driver | Executor / Driver | (random) | Block Manager 端口 | spark.blockManager.port | 通过 ServerSocketChannelRaw socket |
高可用
一般来说, standalone 集群 调度 对于 worker的失败都是有一定弹性的(会将 失去连接 的worker从 worker中移除, 并将任务分配给其他worker.) 然而, 调度器使用的是 master去进行调度决策, 并且(默认情况下)会产生一个单点故障: 如果master 一旦崩溃, 则不会有任何 application 能够被创建, 为了规避这一点, 有如下两个高可用性方案:
Zookeeper
使用zk提供 leader的选举 和 存储一些状态. 我们可以通过 启动 多个masters 并连接到同一个 Zookeeper, 其中一个master会被选举为 leader, 其他的节点会维持在备用状态, 如果当前leader宕机, 则会从备份中选取一个master作为 leader, 恢复master状态, 并恢复调度. 从master宕机开始到另一个master恢复启用, 应该会用1~2分钟的时间.
注意 这种延迟仅仅会影响 调度新的 application, 在master挂掉期间, 正在运行的application是不受影响的.
配置:
为了启用这个恢复模式,您可以在 spark-env 中设置 SPARK_DAEMON_JAVA_OPTS 通过配置 spark.deploy.recoveryMode 和相关的 spark.deploy.zookeeper.* 配置。
配置连接: zk配置
内容如下:
属性名称 默认值 含义 spark.deploy.recoveryMode NONE 恢复模式设置,用于在失败并重新启动时以集群模式恢复提交的Spark作业。这仅适用于与Standalone或Mesos一起运行的群集模式。 spark.deploy.zookeeper.url NONE 当spark.deploy.recoveryMode设置为ZOOKEEPER时,此配置用于设置要连接的Zookeeper URL. spark.deploy.zookeeper.dir NONE 当spark.deploy.recoveryMode设置为ZOOKEEPER时,此配置用于设置zookeeper 存储状态的目录. 当你已经加入了ZK的相关配置之后, 实现高可用就是一件很简单的事, 只需要启动在 多个节点上 启动 多个 master进程 配置同一个zk(包括url 和 目录.), 可以在任意时间添加 或 移除 master.
为了添加新的 application 或 加入 新的 worker节点, 我们需要知道当前leader的 地址.这可以通过简单地传递一个你在一个单一的进程中传递的 Masters 的列表来完成。
如:
spark://host1:port1, host2:port2, host3:port3
通过这种方式 就可以将所有的master注册给 SparkContext了, 如果一个host挂掉, 通过这种方式就可以正确的找到 leader2.
在使用 Master 注册 与 正常操作之间有一个重要的区别。当启动的时候,一个 application 或者 Worker 需要找到当前的 lead Master 并 注册.一旦它成功注册,它就是 “在系统中” 了(即存储在了 ZooKeeper 中)。如果发生故障切换,新的 leader 将会联系所有之前已经注册的应用程序和 Workers 来通知他们领导层的变化,所以他们甚至不知道新的 Master 在启动时是否是否存在.
通过这个属性, 新的master可以在任何时候被创建, 所以你唯一需要担心的是, 新的application 和 worker 能够找到它, 假设它成为了新的leader. 一旦成功注册, 你就不需要担心了.
- 本地文件的方式
Zookeeper是最佳方式, 因此我就不再这里介绍另一种方式了.
这种方式的目的是, 你仅仅只是想要在 master 挂掉之后, 重启master.
以上是关于Spark集群-Standalone 模式的主要内容,如果未能解决你的问题,请参考以下文章