Oracle簇
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Oracle簇相关的知识,希望对你有一定的参考价值。
参考技术A建立顺序是:簇→簇表→簇索引→数据
簇占用实际存储空间
创建簇的格式
CREATE CLUSTER cluster_name
(column date_type [,column datatype]...)
[PCTUSED 40 | integer] [PCTFREE 10 | integer]
[SIZE integer]
[INITRANS 1 | integer] [MAXTRANS 255 | integer]
[TABLESPACE tablespace]
[STORAGE storage]
SIZE:指定估计平均簇键,以及与其相关的行所需的字节数。
在簇中创建的表:聚簇表
将两个表中具有相同的聚簇字段值记录集中存放同一个数据块
在CREATE TABLE 语句 通过 CLUSTER 子句 指定表所使用的簇和聚簇字段
为簇中的聚簇字段创建索引
mysql/sqlserver/oracle
1. ORACLE
oracle 能在所有主流平台上运行(包括 windows)。完全支持所有的工业标准。采用完全开放策略。可以使客户选择最适合的解决方案。对开发商全力支 持.oracle并行服务器通过使一组结点共享同一簇中的工作来扩展windownt的能力,提供高可用性和高伸缩性的簇的解决方案。如果 windowsNT不能满足需要,用户可以把数据库移到UNIX中。Oracle的并行服务器对各种UNIX平台的集群机制都有着相当高的集成度。 oracle获得最高认证级别的ISO标准认证.oracle性能最高, 保持开放平台下的TPC-D和TPC-C的世界记录oracle多层次网络计 算,支持多种工业标准,可以用ODBC、JDBC、OCI等网络客户连接。
Oracle 在兼容性、可移植性、可联结性、高生产率上、开放性也存在优点。Oracle产品采用标准SQL,并经过美国国家标准技术所(NIST)测试。与 IBM SQL/DS,DB2,INGRES,IDMS/R等兼容。 Oracle的产品可运行于很宽范围的硬件与操作系统平台上。可以安装在70种以上 不同的大、中、小型机上;可在VMS、DOS、UNIX、WINDOWS等多种操作系统下工作。能与多种通讯网络相连,支持各种协议(TCP/IP、 DECnet、LU6.2等)。提供了多种开发工具,能极大的方便用户进行进一步的开发。Oracle良好的兼容性、可移植性、可连接性和高生产率是 Oracle RDBMS具有良好的开放性。
Oracle价格是比较昂贵的。据说一套正版的oracle软件早在2006年年底的时候在市场上的价格已经达到了6位数。所以如果你的项目不是那种超级大的项目,还是放弃Oracle吧。
2. SQLSERVER
SQL Server 是 Microsoft推出一套产品,它具有使用方便、可伸缩性好、与相关软件集成程度高等优点,逐渐成为Windows平台下进行数据库应用开发较为理想的 选择之一。SQLServer是目前流行的数据库之一,它已广泛应用于金融,保险,电力,行政管理等与数据库有关的行业.而且,由于其易操作性及友好的界 面,赢得了广大用户的青睐,尤其是SQLServer与其它数据库,如Access,FoxPro,Excel等有良好的ODBC接口,可以把上述数据库 转成SQLServer的数据库,因此目前越来越多的读者正在使用SQLServer.
Sqlserver由于是微软的产品,又有着如此强大的功能,所以他的影响力是几种数据库系统中比较大,用户也是比较多的。它一般是和同是微软产品 的.net平台一起搭配使用。当然其他的各种开发平台,都提供了与它相关的数据库连接方式。因此,开发软件用sqlserver做数据库是一个正确的选 择。
3. MYSQL
MySQL不支持事务处理,没有视图,没有存储过程和触发器,没有数据库端的用户自定义函数,不能完全使用标准的SQL语法。
从 数据库行家听说的第一件事就是MySQL缺乏transactions,rollbacks, 和subselects的功能。如果你计划使用MySQL 写一个关于银行、会计的应用程序,或者计划维护一些随时需要线性递增的不同类的计数器,你将缺乏transactions功能。在现有的发布版本的 MySQL下,请不要有任何的这些想法。(请注意,MySQL的测试版3.23.x系列现在已经支持transactions了)。
在非常必要的情况下,MySQL的局限性可以通过一部分开发者的努力得到克服。在MySQL中你失去的主要功能是subselect语句,而这正是其它的所有数据库都具有的。换而言之,这个失去的功能是一个痛苦。
MySQL没法处理复杂的关联性数据库功能,例如,子查询(subqueries),虽然大多数的子查询都可以改写成join
另 一个MySQL没有提供支持的功能是事务处理(transaction)以及事务的提交(commit)/撤销(rollback)。一个事务指的是被当 作一个单位来共同执行的一群或一套命令。如果一个事务没法完成,那么整个事务里面没有一个指令是真正执行下去的。对于必须处理线上订单的商业网站来 说,MySQL没有支持这项功能,的确让人觉得很失望。但是可以用MaxSQL,一个分开的服务器,它能通过外挂的表格来支持事务功能。
外 键(foreignkey)以及参考完整性限制(referentialintegrity)可以让你制定表格中资料间的约束,然后将约束 (constraint)加到你所规定的资料里面。这些MYSQL没有的功能表示一个有赖复杂的资料关系的应用程序并不适合使用MySQL。当我们说 MySQL不支持外键时,我们指的就是数据库的参考完整性限制--MySQL并没有支持外键的规则,当然更没有支持连锁删除 (cascadingdelete)的功能。简短的说,如果你的工作需要使用复杂的资料关联,那你还是用原来的Access吧。
你在MySQL中也不会找到存储进程(storedprocedure)以及触发器(trigger)。(针对这些功能,在Access提供了相对的事件进程(eventprocedure)。
***********************************************************************************
链接:https://www.zhihu.com/question/19866767/answer/14942009
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
- 如果要说明三者的区别,首先就要从历史入手。
- Oracle:中文译作甲骨文,这是一家传奇的公司,有一个传奇的大老板Larry Ellision。 Ellision 32岁还一事无成,读了三个大学,没得到一个学位文凭,换了十几家公司,老婆也离他而去。开始创业时只有1200美元,却使得Oracle公司连续12年销售额每年翻一番。
Oracle成立于1977年,早期的理论基础,反而来自于一篇IBM的论文《A Relational Model of Data for Large Shared Data Banks》【1】。作者CODD选取了关系代数的五种运算,并基于运算,架构了一种新型的数据存储模型。基于这种模型,Oracle成为了一个非常典型的关系数据库。因此也变的严谨、安全、高速、稳定,并且变的越来越庞大。
由于其诞生早、结构严谨、高可用、高性能等特点,使其在传统数据库应用中大杀四方,金融、通信、能源、运输、零售、制造等各个行业的大型公司基本都是用了Oracle,早些年的时候,世界500强几乎100%都是Oracle的用户。 - MySQL :MySQL的最初的核心思想,主要是开源、简便易用。其开发可追溯至1985年,而第一个内部发行版本诞生,已经是1995年。到1998年,MySQL已经可以支持10中操作系统了,其中就包括win平台。但依然问题多多,如不支持事务操作、子查询 、外键、存储过程和视图等功能。下图是一个截止至2006年的数据库市场占有率【2】:
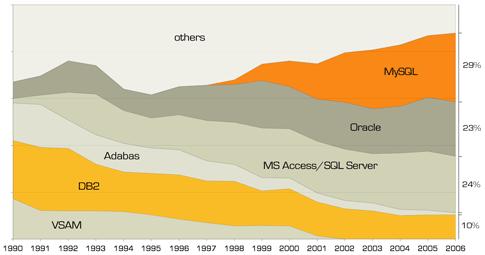 图中可以看出,MySQL的爆发实际是在01、02年,尤其是02年发布的4.0 Beta版,正式选定InnoDB作为默认引擎,对事务处理能力及数据缓存能力有了极大的提高。同年4.1版开始支持子查询,至此MySQL终于蜕变成一个成熟的关系型数据库系统。05年的5.0版本又添加了存储过程、服务端游标、触发器、查询优化以及分布式事务功能,但同年被Oracle抄了后路,InnoDB被Oracle收编。08年,MySQL被Sun收购,09年,Oracle收购了Sun和MySQL。
图中可以看出,MySQL的爆发实际是在01、02年,尤其是02年发布的4.0 Beta版,正式选定InnoDB作为默认引擎,对事务处理能力及数据缓存能力有了极大的提高。同年4.1版开始支持子查询,至此MySQL终于蜕变成一个成熟的关系型数据库系统。05年的5.0版本又添加了存储过程、服务端游标、触发器、查询优化以及分布式事务功能,但同年被Oracle抄了后路,InnoDB被Oracle收编。08年,MySQL被Sun收购,09年,Oracle收购了Sun和MySQL。
由于MySQL的早期定位,其主要应用场景就是互联网开发。基本上,互联网的爆发成就了MySQL,LAMP架构风靡天下。而由于MySQL更多的的追求轻量、易用,以及早期的事物操作及复杂查询优化的缺失,在传统的数据库应用场景中,份额极少。 - SQL Server:一提到SQL Server,大家一般都只想到Microsoft SQL Server,而非Sybase SQL Server。SQL Server最初是由Microsoft, Sybase and Ashton-Tate三家公司拦下的生意,是为IBM(又出现了)公司的OS/2操作系统开发的。随着OS/2项目的失败,大家也分道扬镳。 Microsoft自然转向自己的win操作系统,作为windows NT软件方案的一部分。而Sybase则专注于Linux/Unix方向的数据库开发。
MS SQL Server主要面向中小企业。其最大的优势就是在于集成了MS公司的各类产品及资源,提供了强大的可视化界面、高度集成的管理开发工具,在快速构建商业智能(BI)方面颇有建树。 MS SQL Server是MS公司在软件集成方案中的重要一环,也为WIN系统在企业级应用中的普及做出了很大贡献。
- 典型应用场景
关于“大型数据库”,并没有严格的界定,有说以数据量为准,有说以恢复时间为准。如果综合数据库应用场景来说,大型数据库应用有以下特点:海量数据、高吞吐量;复杂逻辑、高计算量,以及高可用性。从这点上来说,Oracle,DB2就是比较典型的大型数据库,Sybase SQL Server也算是吧。下面分别说明之前三种数据库的应用场景。
- Oracle。Oracle的应用,主要在传统行业的数据化业务中,比如:银行、金融这样的对可用性、健壮性、安全性、实时性要求极高的业务;零售、物流这样对海量数据存储分析要求很高的业务。此外,高新制造业如芯片厂也基本都离不开Oracle;电商也有很多使用者,如京东(正在投奔Oracle)、阿里巴巴(计划去Oracle化)。而且由于Oracle对复杂计算、统计分析的强大支持,在互联网数据分析、数据挖掘方面的应用也越来越多。一个典型场景是这样的:
某电信公司(非国内)下属某分公司的数据中心,有4台Oracle Sun的大型服务器用来安装Solaris操作系统和Oracle并提供计算服务,3台Sun Storage磁盘阵列来提供Oracle数据存储,12台IBM小型机,一台Oracle Exadata服务器,一台500T的磁带机用来存储历史数据,San连接内网,使用Tuxedo中间件来保证扩展性和无损迁移。建立支持高并发的Oracle数据库,通过OLTP系统用来对海量数据实时处理、操作,建立高运算量的Oracle数据仓库,用OLAP系统用来分析营收数据及提供自动报表。总预算约750万美金。 - MySQL。MySQL基本是生于互联网,长于互联网。其应用实例也大都集中于互联网方向,MySQL的高并发存取能力并不比大型数据库差,同时价格便宜,安装使用简便快捷,深受广大互联网公司的喜爱。并且由于MySQL的开源特性,针对一些对数据库有特别要求的应用,可以通过修改代码来实现定向优化,例如SNS、LBS等互联网业务。一个典型的应用场景是:
某互联网公司,成立之初,仅有PC数台,通过LAMP架构迅速搭起网站框架。随着业务扩张、市场扩大,迅速发展成为6台Dell小型机的中型网站。现在花了三年,终于成为垂直领域的最大网站,计划中的数据中心,拥有Dell机架式服务器40台,总预算20万美金。 - MS SQL Server。windows生态系统的产品,好处坏处都很分明。好处就是,高度集成化,微软也提供了整套的软件方案,基本上一套win系统装下来就齐活了。因此,不那么缺钱,但很缺IT人才的中小企业,会偏爱 MS SQL Server 。例如,自建ERP系统、商业智能、垂直领域零售商、餐饮、事业单位等等。
1996年,Bill Gates亲自出手,从Borland挖来了大牛Anders,搞定了C#语言。微软02年搞定了http://ASP.NET。成熟的.NET、Silverlight技术,为 MS SQL Server赢得了部分互联网市场,其中就有曾经的全球最大社交网站MySpace,其发展历程很有代表性,可作为一个比较特别的例子【3】。其巅峰时有超过1.5亿的注册用户及每月400亿的访问量。应该算是MS SQL Server支撑的最大的数据应用了。
- 架构。其实要说执行的区别,主要还是架构的区别。正是架构导致了相同SQL在执行过程中的解释、优化、效率的差异。这里只做粗略说明,就不细说了:
- Oracle: 数据文件包括:控制文件、数据文件、重做日志文件、参数文件、归档文件、密码文件。这是根据文件功能行进行划分,并且所有文件都是二进制编码后的文件,对数据库算法效率有极大的提高。由于Oracle文件管理的统一性,就可以对SQL执行过程中的解析和优化,指定统一的标准:
RBO(基于规则的优化器)、CBO(基于成本的优化器)
通过优化器的选择,以及无敌的HINT规则,给与了SQL优化极大的自由,对CPU、内存、IO资源进行方方面面的优化。 - MySQL:最大的一个特色,就是自由选择存储引擎。每个表都是一个文件,都可以选择合适的存储引擎。常见的引擎有 InnoDB、 MyISAM、 NDBCluster等。但由于这种开放插件式的存储引擎,比如要求数据库与引擎之间的松耦合关系。从而导致文件的一致性大大降低。在SQL执行优化方面,也就有着一些不可避免的瓶颈。在多表关联、子查询优化、统计函数等方面是软肋,而且只支持极简单的HINT。
- SQL Server :数据架构基本是纵向划分,分为:Protocol Layer(协议层), Relational Engine(关系引擎), Storage Engine(存储引擎), SQLOS。SQL执行过程就是逐层解析的过程,其中Relational Engine中的优化器,是基于成本的(CBO),其工作过程跟Oracle是非常相似的。在成本之上也是支持很丰富的HINT,包括:连接提示、查询提示、表提示。
以上是关于Oracle簇的主要内容,如果未能解决你的问题,请参考以下文章