爬虫是什么
Posted 1208xu
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬虫是什么相关的知识,希望对你有一定的参考价值。
网络爬虫很厉害的东西,行业标杆Google,Baidu, 这都不用多说了,网络爬虫就是为其提供信息来源的程序。对于当时的我接触这个东西还是一脸懵逼,也怀疑这些大公司开发的东西岂是我等草民,所能参悟到的。热情还是驱使我买了很多书,看的也是云里雾里,没得到什么灵感。最后在图书馆,找的一本封存在角落里<<网络机器人java编程指南>>给了我很大启发。
开始进入正题,网络爬虫其实是一种机器人程序,什么是机器人程序,就是替人类做重复性工作的程序,比如说:你得到了一份很无趣的工作,你的老板叫你每天把隔壁竞争对手公司网站主页内容复制下来保存到word给他(也没谁了),接下你会打开浏览器,输入隔壁公司的网址, 进入主页,鼠标一划,然后Ctrl+C 和 Ctrl + V, ,保存world,万事大吉。 突然有一天你公司强大了, 竞争对手范围上升到了50个, 还是重复之前的流程,还好CV大法练得比较纯熟,下班前就完成了,不过想想以后这要是几百个,几千个竞争对手,我的天啊,要累死朕啊!内心极度渴望一种程序可以摆脱这无聊的工作,幸好是个程序猿,所以要写个程序帮我完成这些工作。
我们怎么设计这个程序呢, 首先我要将50个公司的网址保存起来,循环他每个网址,访问网站,找到内容,保存到本地。这就是爬虫程序,名字听起来高大上,其实爬虫就是帮你解决这些重复的操作而已。所以他之后写了一个代码:
main()
{
url[50] //50个公司地址
loop(i < 50) //循环50次, for循环,while循环,只要是个循环就行。
{
request url[i]; //获取网页
Ctrl + C; //复制
Ctrl + V; //粘贴
i++;
}
}
loop(i < 50) //循环50次, for循环,while循环,只要是个循环就行。
{
request url[i]; //获取网页
Ctrl + C; //复制
Ctrl + V; //粘贴
i++;
}
}
我的天啊,这也叫代码。 这个程序猿碰到了问题,怎么获取网页? 怎么样才能找到想要的内容保存呢?以后几百个网站几千个网站,保存这些网址数组难道我还要一遍一遍输入?问题总要一个一个解决。
首先我们是通过浏览器输入网址获取到我们想要的网页, 那浏览器是怎么做到的呢,你是否会有过这样的经历,热切等待电视剧的更新,说好的19点更新,怎么还不更新,刷新了一下页面最后发现已经更新,如果你不刷新你依旧不知道他更新了,所以只要你不请求,你的页面就不会改变,这并不是一个持久的过程,而是短暂的过程。通过你的输入网址的操作,刷新的操作,实际上浏览器是在向服务端程序要你想看的网页,服务端程序返回给你想看的网页到浏览器上,这就是实现了http通讯协议的工具所做到的事情,接下来就是找到这个工具然后放到我们程序里,目前来看任何一款面向对象的开发语言都支持这个工具,不用担心找不到,最重要的是我们知道通过他能获取网页。为什么能准确找到我想看的网页,这就要说下URL,”统一资源定位符是对可以从互联网上得到的资源的位置和访问方法的一种简洁的表示,是互联网上标准资源的地址。互联网上的每个文件都有一个唯一的URL,它包含的信息指出文件的位置“
这说的就是网址(除了他也没别人了)
举个例子: (http://127.0.0.1:8080/index.html , http代表是用http传输协议,127.0.0.1是要访问目标机器的IP地址,8080是端口, index.html也就是我们想要的文件名字),我们给予如此多的信息也不想象难出http协议工具是如何通过网址定位到我们想要的文件。(http://www.XXX.com/
像这样的网址带万维网会翻译成url正常格式)。
接下来怎么能知道我想要的内容,并保存。首先网页是什么,就是包含了文字,图片,视频,音乐,程序...大的集合,那这样一个复杂的集合总会有一定的组织形式,不然管理起来不是很累么,这就是htm超文本语言,其实就是一堆标签包含我们想要的内容(文字,图片,视频,音乐,程序...)打开浏览器输入一个网址,按F12你会看到类似如下图片,左侧是是页面,右侧就是html格式的页面,右侧看起来好闹心,但是没什么关系,我们只是想找几个我们关心的标签(标签就是<div> </div>像这种形式的结构), 你也可以找个写网页的工具像DreamWeaver,写个网页~~
F12后的页面如下:
首先我们是通过浏览器输入网址获取到我们想要的网页, 那浏览器是怎么做到的呢,你是否会有过这样的经历,热切等待电视剧的更新,说好的19点更新,怎么还不更新,刷新了一下页面最后发现已经更新,如果你不刷新你依旧不知道他更新了,所以只要你不请求,你的页面就不会改变,这并不是一个持久的过程,而是短暂的过程。通过你的输入网址的操作,刷新的操作,实际上浏览器是在向服务端程序要你想看的网页,服务端程序返回给你想看的网页到浏览器上,这就是实现了http通讯协议的工具所做到的事情,接下来就是找到这个工具然后放到我们程序里,目前来看任何一款面向对象的开发语言都支持这个工具,不用担心找不到,最重要的是我们知道通过他能获取网页。为什么能准确找到我想看的网页,这就要说下URL,”统一资源定位符是对可以从互联网上得到的资源的位置和访问方法的一种简洁的表示,是互联网上标准资源的地址。互联网上的每个文件都有一个唯一的URL,它包含的信息指出文件的位置“
这说的就是网址(除了他也没别人了)
举个例子: (http://127.0.0.1:8080/index.html , http代表是用http传输协议,127.0.0.1是要访问目标机器的IP地址,8080是端口, index.html也就是我们想要的文件名字),我们给予如此多的信息也不想象难出http协议工具是如何通过网址定位到我们想要的文件。(http://www.XXX.com/
像这样的网址带万维网会翻译成url正常格式)。
接下来怎么能知道我想要的内容,并保存。首先网页是什么,就是包含了文字,图片,视频,音乐,程序...大的集合,那这样一个复杂的集合总会有一定的组织形式,不然管理起来不是很累么,这就是htm超文本语言,其实就是一堆标签包含我们想要的内容(文字,图片,视频,音乐,程序...)打开浏览器输入一个网址,按F12你会看到类似如下图片,左侧是是页面,右侧就是html格式的页面,右侧看起来好闹心,但是没什么关系,我们只是想找几个我们关心的标签(标签就是<div> </div>像这种形式的结构), 你也可以找个写网页的工具像DreamWeaver,写个网页~~
F12后的页面如下:
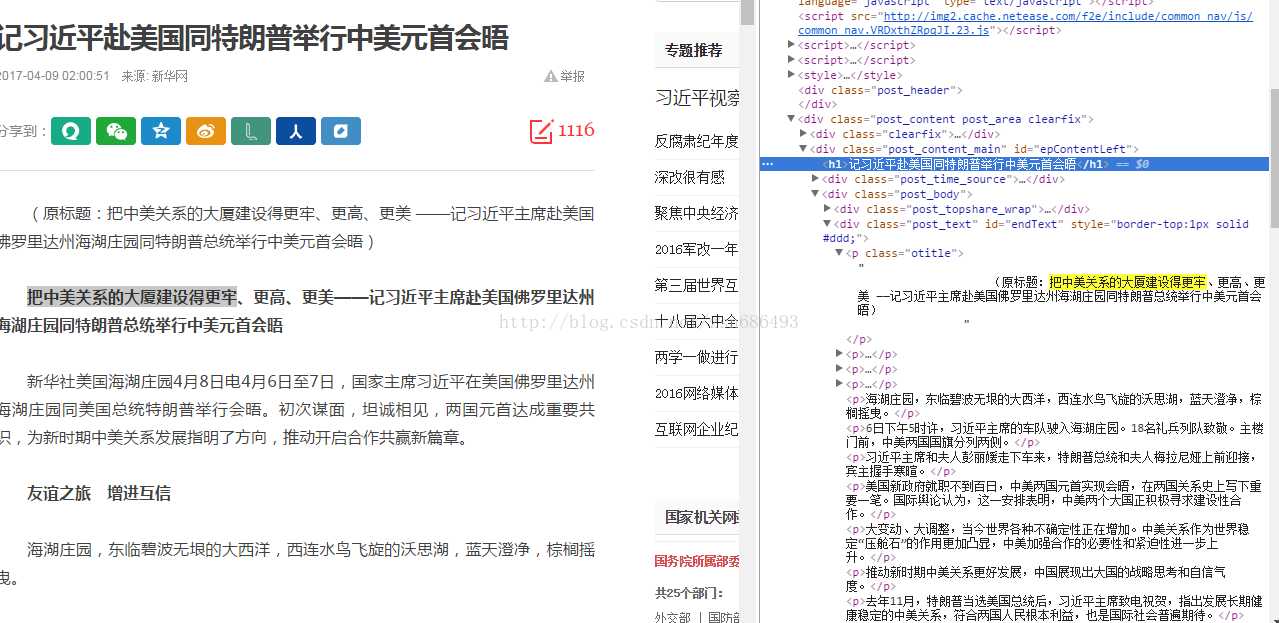
你输入网址请求的页面,其实是以html格式返回给你,也就是先给你右侧这一坨东西,再转化成左侧比较和谐的东西,你的浏览器可以解析出这个格式,并将其对应内容,放到页面对应位置上,查看这个右侧文字与左侧文字对应,如上图我们只要解析<p> </p>这个标签就能获取我们想要的文本,同样html解析工具也是随处可见,关注你感兴趣的含文本的标签,在获取到文本后保存成文件即可。
还不错,还剩下最后一个问题看着问题不大,但是却是最关键的。老板给你多少网址你就写多少网址。但是现实是老板连网都不会上,怎么能给你网址,所以真实情况下给你任务是找出与我们相关的网址并获取文本发给我,好的大王,是的大王,不过没有了网址我怎么能获取我想要的网页呢?
我们在浏览页面的时候会点击某个页面上标题或按钮,会自动跳转到下一个页面。
例如下图:(页面展示是个电影分类文字标题)
这里有个标签带了个属性href = “....", 看着格式就知道是个网址,所以跳转(超链接)其实就是通过这个新的url向服务端做了个请求,然后将一个新的页面展示给你。这和你在浏览器上输入网址然后按回车是一个道理,只不过这次是点击(啰嗦)。所以我们大胆想象下网络上的所有网页都是这样关联在一起的,比如自己写个网站如果想让其他人快速知道,一般会放到点击量高的网址,通过这个网站再进入到我的网站,然后浏览我的网页内容,当然我的网页内容同样也包含别人网站的连接,只要找个网页解析出url就能,再发送请求就能找到下一个网页,以此类推。至于实现其实很简单,使用html解析解析工具,这回是我们感兴趣的第二个标签<a
href = "url" >,将解析出来的url存到数组中,大工告成。
重新再来写一下:
void main()
{
href = "url" >,将解析出来的url存到数组中,大工告成。
重新再来写一下:
void main()
{
Vector <string> urlArray; //这里用了容器Vector,就是个无限长度的数组,为了方便你不用再写数组长度了(但实际上并不适合,下回分解),还是存放网址 (URL), 启动前要至少添加一个url
while (urlArray.count != 0) //判断存的url数组里不能为空,为空则结束循环。
{
string htmlPage = Request(urlArray[0]); //请求获取网页文件, index.html, xxx.html,获取形式是字符串。
string text = ParseHtmlText(htmlPage); //解析htmlPage,并获取文本,
string url = ParseHtmlUrl(htmlPage); //解析htmlPage,并获取url,这里其实是一堆url,主页里会有很多url解析出来,这里为了清晰就写一个吧。
saveFile(text); //保存刚才获取到text到本地文件
urlArray.add(url); //添加url到urlArray 保存url,作为下次使用的url
urlArray.remove(0); //移除这次使用过的url也就是第一个urlArray[0]
}
}
最后广度搜索方式网络爬虫写完了。当然你会吐槽,但是槽点太多无从下口。请原谅我的懒惰,这个就是百分之百网络爬虫。首先解释下流程,循环开始检查下url列表中是否是空的,不是则获取首个url,通过url请求获得htmlPage页面,然后进行解析网页获取text 和 url两个内容,然后将text文本保存,将url加入url列表作为待访问的点。这个过程就是通过url获取页面,通过页面获取url,就这样回到了哲学问题上,鸡生蛋,蛋生鸡。
while (urlArray.count != 0) //判断存的url数组里不能为空,为空则结束循环。
{
string htmlPage = Request(urlArray[0]); //请求获取网页文件, index.html, xxx.html,获取形式是字符串。
string text = ParseHtmlText(htmlPage); //解析htmlPage,并获取文本,
string url = ParseHtmlUrl(htmlPage); //解析htmlPage,并获取url,这里其实是一堆url,主页里会有很多url解析出来,这里为了清晰就写一个吧。
saveFile(text); //保存刚才获取到text到本地文件
urlArray.add(url); //添加url到urlArray 保存url,作为下次使用的url
urlArray.remove(0); //移除这次使用过的url也就是第一个urlArray[0]
}
}
最后广度搜索方式网络爬虫写完了。当然你会吐槽,但是槽点太多无从下口。请原谅我的懒惰,这个就是百分之百网络爬虫。首先解释下流程,循环开始检查下url列表中是否是空的,不是则获取首个url,通过url请求获得htmlPage页面,然后进行解析网页获取text 和 url两个内容,然后将text文本保存,将url加入url列表作为待访问的点。这个过程就是通过url获取页面,通过页面获取url,就这样回到了哲学问题上,鸡生蛋,蛋生鸡。
是先有鸡,还是先有蛋呢,不管先有谁,我们都必须要让这个循环进行下去,让鸡下蛋,让蛋生鸡,子子孙孙无穷匮也。所以我们先给个蛋(url), 让世界的齿轮开始转动。爬虫原理就是这么简单,你用任何一款面向对象语言(C++, java, c#, python, go, php)都能实现它。虽然写完了,但是事情还远没有结束,我们程序猿在写完了这个程序后会碰到了各种各样的问题,网络是个危险地方,我们还是会火星吧。这个粗枝大叶的程序能在今天的网络活上半小时已经是奇迹了。这也就是为什么有各式各样爬虫程序,格式各样的开发组件工具层出不穷,为的就是将循环进行到底。但首先搞明白爬虫是什么东西才能更灵活设计出自己的爬虫,至于程序猿能不能完成任务,下次再说