oracle查询出来的数据如何消除重复数据
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了oracle查询出来的数据如何消除重复数据相关的知识,希望对你有一定的参考价值。
这是PB中代码:
SELECT "PAT_MASTER_INDEX"."PATIENT_ID", "PAT_MASTER_INDEX"."NAME", "INP_PAYMENTS_MONEY"."PAYMENT_AMOUNT", "INP_PAYMENTS_MONEY"."MONEY_TYPE", "INP_SETTLE_MASTER"."CHARGES", "INP_SETTLE_MASTER"."RCPT_NO", "INP_SETTLE_MASTER"."OPERATOR_NO" FROM "INP_PAYMENTS_MONEY", "INP_SETTLE_MASTER", "PAT_MASTER_INDEX" WHERE ( "INP_PAYMENTS_MONEY"."RCPT_NO" = "INP_SETTLE_MASTER"."RCPT_NO" ) and ( "INP_SETTLE_MASTER"."PATIENT_ID" = "PAT_MASTER_INDEX"."PATIENT_ID" )
查询出的结果有重复的(这是结果部分截图),如果我想把重复的ID号消除,group by怎么应用?
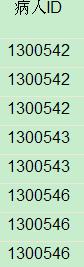
oracle查询出来的数据消除重复数据的具体步骤如下:
1、首先我们查看表中重复的数据。
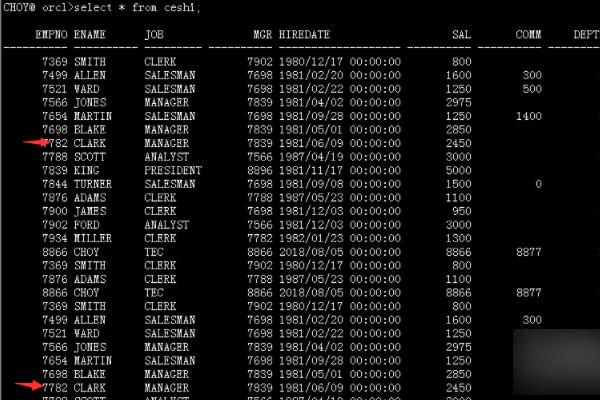
2、然后我饿美女使用distinct去除函数查询出去掉重复后的数据。
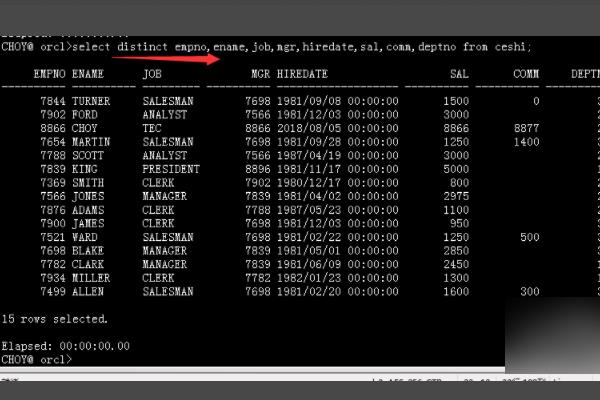
3、然后我们创建新表把去掉重复的数据插入到新表中。
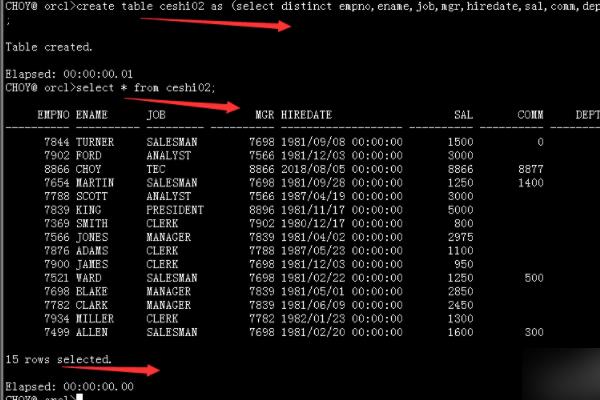
4、最后使用truncate清空原表中的数据。
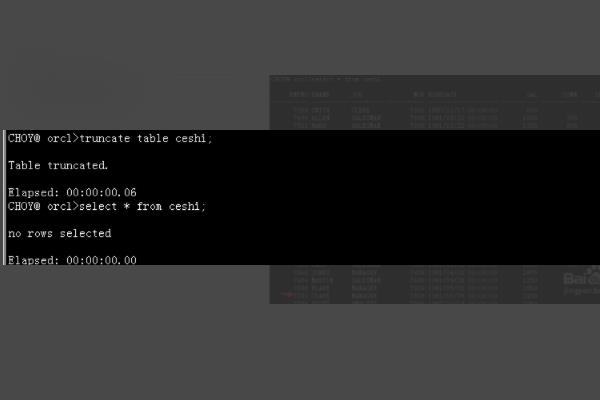
5、再向原表中插入新表中重复的数据,即可达到去重复数据的效果。
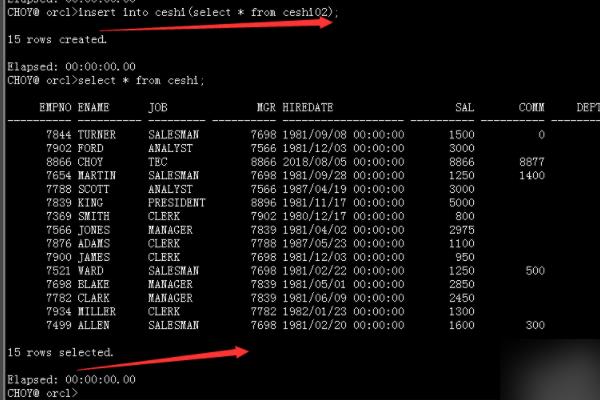
Oracle数据库重复的数据一般有两种去重方法,一、完全重复数据去重;二、部分字段数据重复去重。
一、完全重复数据去重方法
对于表中完全重复数据去重,可以采用以下SQL语句。
Code
CREATETABLE"#temp"AS (SELECTDISTINCT * FROM 表名);--创建临时表,并把DISTINCT 去重后的数据插入到临时表中
truncateTABLE 表名;--清空原表数据
INSERTINTO 表名(SELECT * FROM"#temp");--将临时表数据插入到原表中
DROPTABLE"#temp";--删除临时表
具体思路是,首先创建一个临时表,然后将DISTINCT之后的表数据插入到这个临时表中;然后清空原表数据;再讲临时表中的数据插入到原表中;最后删除临时表。
二、部分数据去重方法
首先查找重复数据
select 字段1,字段2,count(*) from 表名 groupby 字段1,字段2 havingcount(*) > 1
将上面的>号改为=号就可以查询出没有重复的数据了。
想要删除这些重复的数据,可以使用下面语句进行删除:
deletefrom 表名 a where 字段1,字段2 in
(select 字段1,字段2,count(*) from 表名 groupby 字段1,字段2 havingcount(*) > 1)
oracle产品服务
甲骨文公司产品主要有以下几类:
甲骨文股份有限公司
1.服务器及工具
数据库服务器:2013年最新版本Oracle 12C。
应用服务器:Oracle Application Server。
开发工具:OracleJDeveloper,Oracle Designer,Oracle Developer,等等。
2.企业应用软件
企业资源计划(ERP)软件。已有10年以上的历史。2005年,并购了开发企业软件的仁科软件公司(PeopleSoft)以增强在这方面的竞争力。
客户关系管理(CRM)软件。自1998年开始研发这种软件。2005年,并购了开发客户关系管理软件的希柏软件公司(Siebel)。
3. Oracle职业发展力计划(Oracle WDP)
Oracle WDP 全称为Oracle Workforce Development Program,是Oracle (甲骨文)公司专门面向学生、个人、在职人员等群体开设的职业发展力课程。Oracle的技术广泛应用于各行各业,其中电信、电力、金融、政府及大量制造业都需要Oracle技术人才,Oracle公司针对职业教育市场在全球推广的项目,其以低廉的成本给这部分人群提供Oracle技术培训,经过系统化的实训,让这部分人群能够迅速掌握Oracle最新的核心技术,并能胜任企业大型数据库管理、维护、开发工作。
参考技术C SELECT distinct "PAT_MASTER_INDEX"."PATIENT_ID", "PAT_MASTER_INDEX"."NAME", "INP_PAYMENTS_MONEY"."PAYMENT_AMOUNT", "INP_PAYMENTS_MONEY"."MONEY_TYPE", "INP_SETTLE_MASTER"."CHARGES", "INP_SETTLE_MASTER"."RCPT_NO", "INP_SETTLE_MASTER"."OPERATOR_NO" FROM "INP_PAYMENTS_MONEY", "INP_SETTLE_MASTER", "PAT_MASTER_INDEX" WHERE ( "INP_PAYMENTS_MONEY"."RCPT_NO" = "INP_SETTLE_MASTER"."RCPT_NO" ) and ( "INP_SETTLE_MASTER"."PATIENT_ID" = "PAT_MASTER_INDEX"."PATIENT_ID" )本回答被提问者采纳 参考技术D 在你需要去掉重复数据的字段前加上distinctselect distinct PATIENT_ID from xxxx
oracle数据查询时如何定位问题数据
在oracle数据库中执行一个查询语句,数据查询到一部分时报错,SQL本身没问题,是由于表中有异常数据导致的,只要定位到这条异常数据,将其数据修正,SQL就能正确执行,但如何快速定位到异常数据?
参考技术A 可以根据where条件去找的什么时候开始错误的
找最后正常天之后的数据出来对
范围慢慢缩小,你这种情况,肯定是业务数据保存的时候没有SQL过滤 参考技术B 这样的问题回答起来比较难。
对待有问题的数据
首先判断会出现什么问题。
针对问题,通过where 条件限定,查询到问题数据追问
我一直也是这么做的,但以为有简便的方法,因为oracle在遇到问题数据时才报错,说明它已经找到这条数据了,oracle本身没有一个将问题数据抛出来的机制?
追答数据库 有验证机制,但是不能够解决全部的问题
所以需要人为的去排错
以上是关于oracle查询出来的数据如何消除重复数据的主要内容,如果未能解决你的问题,请参考以下文章