Solr7.x学习-创建core并使用分词器
Posted zhi-leaf
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Solr7.x学习-创建core并使用分词器相关的知识,希望对你有一定的参考价值。
1、创建core文件夹
ck /usr/local/solr-7.7.2/server/solr
mkdir first-core
cp -r configsets/_default/* first_core/
2、添加core
3、配置中文IK分词器
参考:https://github.com/magese/ik-analyzer-solr
1)将ik-analyzer-7.7.1.jar复制到solr-7.7.2/server/solr-webapp/webapp/WEB-INF/lib目录下
2)将https://github.com/magese/ik-analyzer-solr/tree/v7.7.1/src/main/resources目录下的dynamicdic.txt、ext.dic、ik.conf、IKAnalyzer.cfg.xml、stopword.dic文件复制到solr-7.7.2/server/solr-webapp/webapp/WEB-INF/classes目录下。
3)修改managed-schema,添加配置:
<!-- ik分词器 --> <fieldType name="text_ik" class="solr.TextField"> <analyzer type="index"> <tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="false" conf="ik.conf"/> <filter class="solr.LowerCaseFilterFactory"/> </analyzer> <analyzer type="query"> <tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="true" conf="ik.conf"/> <filter class="solr.LowerCaseFilterFactory"/> </analyzer> </fieldType>
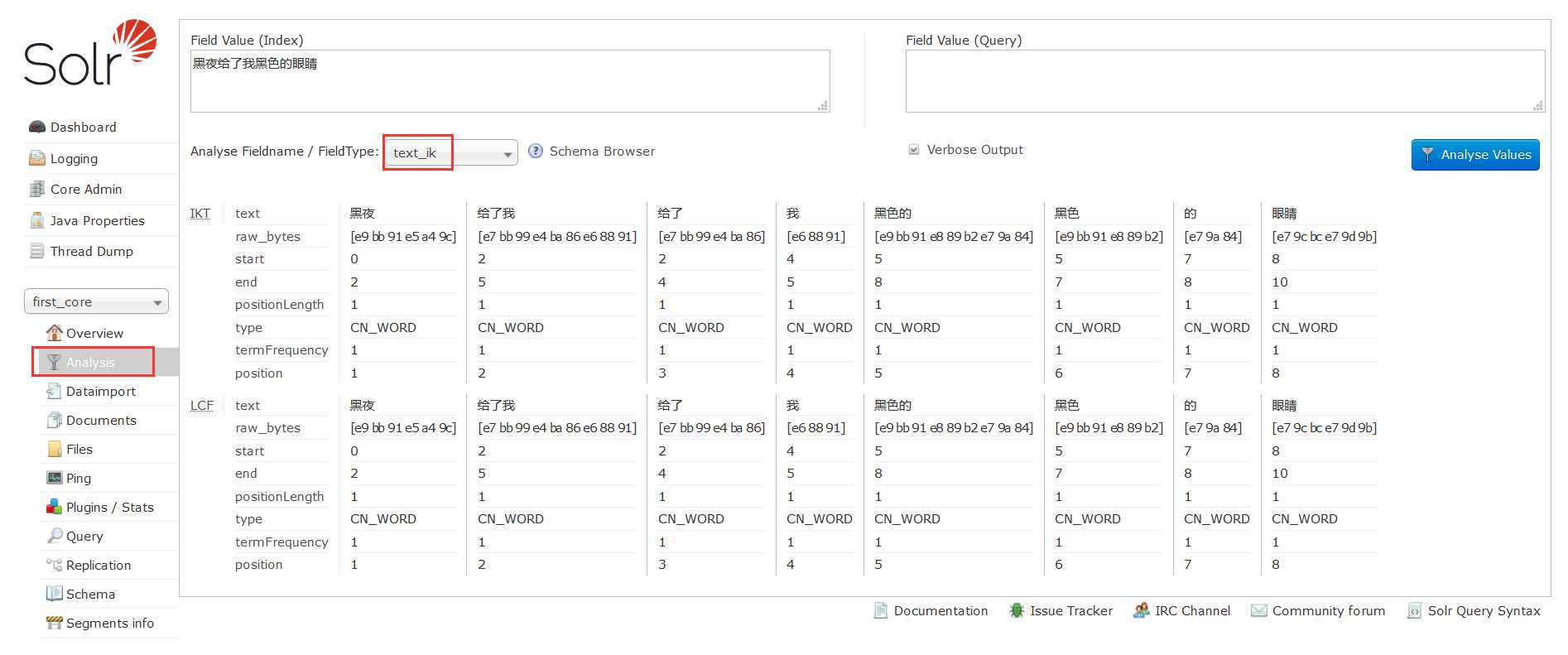
4)重启solr服务,测试IK分词器
4、使用solr自带的smart中文分词器
1)复制solr-7.7.2contribanalysis-extraslucene-libslucene-analyzers-smartcn-7.7.2.jar到solr-7.7.2/server/solr-webapp/webapp/WEB-INF/lib目录下
2)修改managed-schema文件,增加配置
<fieldType name="text_smart" class="solr.TextField" positionIncrementGap="100"> <analyzer type="index"> <tokenizer class="org.apache.lucene.analysis.cn.smart.HMMChineseTokenizerFactory"/> </analyzer> <analyzer type="query"> <tokenizer class="org.apache.lucene.analysis.cn.smart.HMMChineseTokenizerFactory"/> </analyzer> </fieldType>
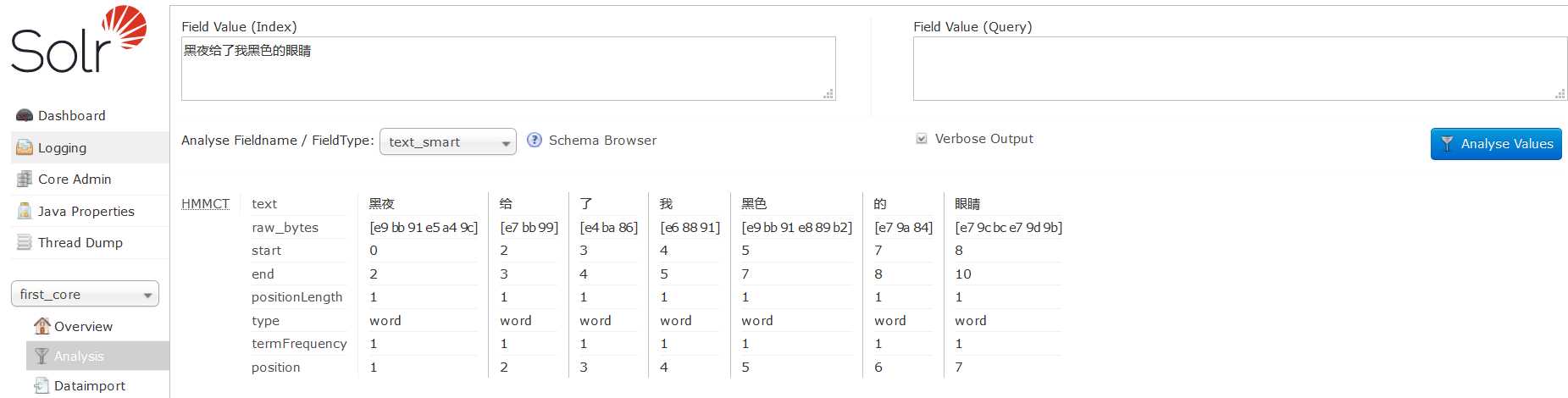
3)重启solr,测试smart分词器
以上是关于Solr7.x学习-创建core并使用分词器的主要内容,如果未能解决你的问题,请参考以下文章