大数据实战——hadoop集群安装搭建
Posted 北溟溟
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据实战——hadoop集群安装搭建相关的知识,希望对你有一定的参考价值。
前言
本节内容我们主要来介绍如何搭建hadoop集群,将hadoop的基础环境搭建完成,便于我们使用hadoop集群。在搭建hadoop集群搭建之前,我们需要先安装java环境,并且我们需要规划我们hadoop集群的组件分布,保证hadoop集群服务器能发挥其最大的价值。
hadoop集群组件分布如下:
| hadoop101 | hadoop102 | hadoop103 | |
|---|---|---|---|
| HDFS | NameNode DataNode | DataNode | SecondaryNameNode DataNode |
| YARN | NodeManager | ResourceManager NodeManager | NodeManager |
正文
- java环境安装
①上传java安装包到hadoop101服务器
②解压java安装包到/opt/module目录
命令:tar -zxvf jdk-8u212-linux-x64.tar.gz -C /opt/module/
③在/etc/profile.d目录下,新建环境变量配置文件my_env.sh
④在配置文件my_env.sh中添加java环境变量配置
#JAVA_HOME export JAVA_HOME=/opt/module/jdk1.8.0_212 export PATH=$PATH:$JAVA_HOME/bin
⑤让新的环境变量 PATH 生效,查看java环境配置是否生效
source /etc/profile
⑥分发java安装包到hadoop102和hadoop103服务器
hsync /opt/module/jdk1.8.0_212
⑦分发环境配置文件my_env.sh到hadoop102和hadoop103服务器
hsync /etc/profile.d/my_env.sh
⑧分别在hadoop102与hadoop103上面执行source /etc/profile,查看java是否安装完成









- hadoop安装
①上传hadoop安装包到hadoop101服务器
② 解压hadoop安装包到/opt/module目录
命令:tar -zxvf hadoop-3.1.3.tar.gz -C /opt/module/
③获取hadoop安装目录/opt/module/hadoop-3.1.3
④在/etc/profile.d/my_env.sh环境变量配置文件中配置hadoop的环境变量
#HADOOP_HOME export HADOOP_HOME=/opt/module/hadoop-3.1.3 export PATH=$PATH:$HADOOP_HOME/bin export PATH=$PATH:$HADOOP_HOME/sbin
⑤使配置的环境变量生效,并查看hadoop的安装情况
source /etc/profile
⑥分发hadoop安装包到hadoop102和hadoop103服务器
命令:hsync /opt/module/hadoop-3.1.3/
⑦分发环境配置文件my_env.sh到hadoop102和hadoop103服务器
hsync /etc/profile.d/my_env.sh
⑧分别在hadoop102与hadoop103上面执行source /etc/profile,查看hadoop是否安装完成








结语
本节内容到这里就结束了,关于hadoop的组件运行及启动,由于篇幅所限,我们在下节内容中再详细介绍,后会有期。。。。。。
大数据实战——hadoop的模板虚拟机搭建
前言
在实际的开发过程中,我们的hadoop都是以集群的方式存在,该系列内容我们使用vmware工具构建我们的虚拟机,从而实现hadoop集群搭建。在开始hadoop集群搭建之前,我们需要先创建一个模板虚拟机,便于我们集群虚拟机的快速克隆复制使用。关于vmware工具的安装,这里不在介绍,读者可以查看我往期的博客内容。
正文
- 虚拟机硬件配置
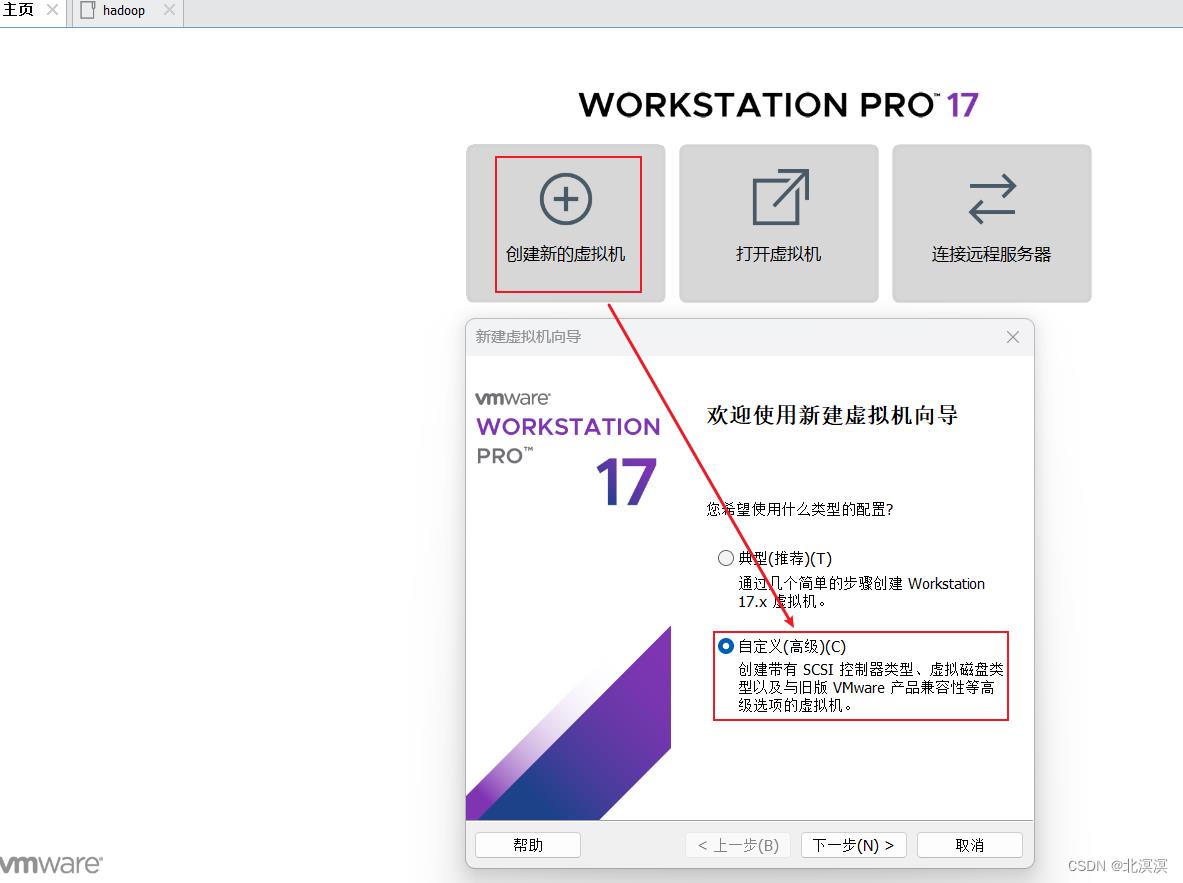
①打开vmware工具,点击创建虚拟机,选择自定义创建
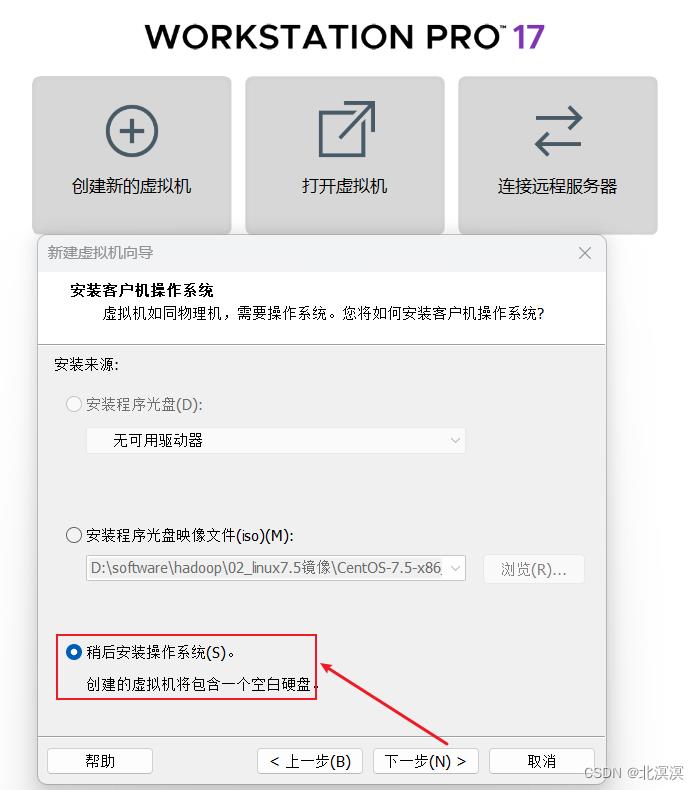
②一直点击下一步,选择稍后安装操作系统
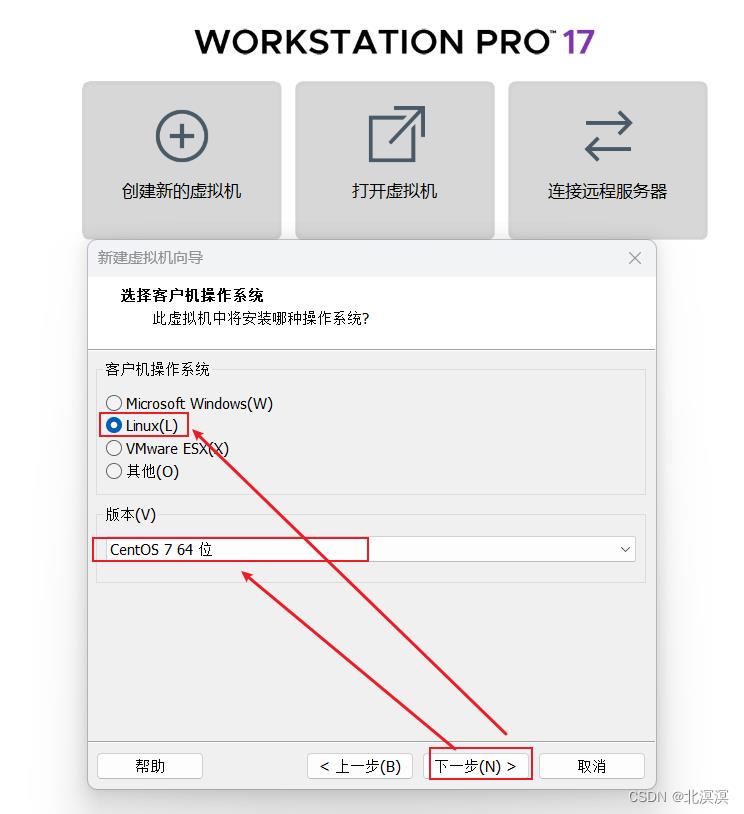
③选择centos7系统安装虚拟机
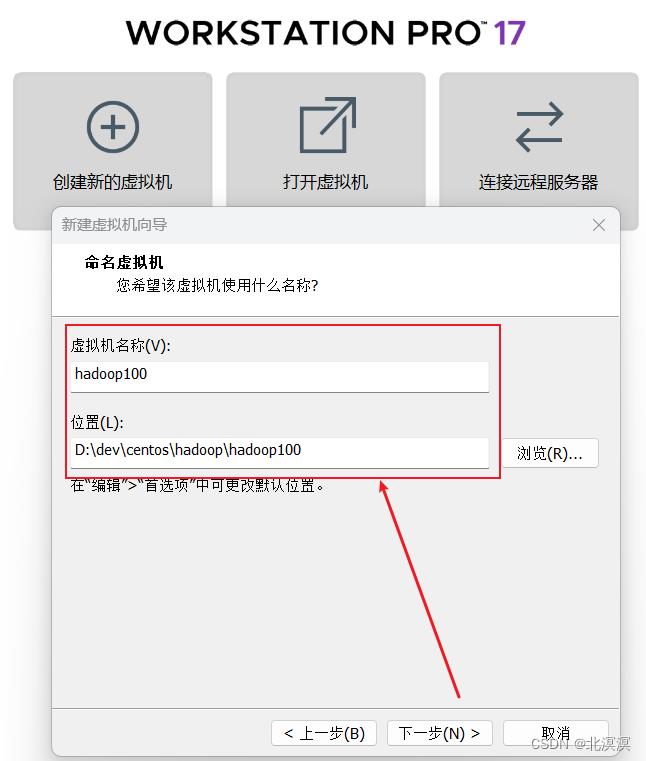
④填写虚拟机名称和存储路径
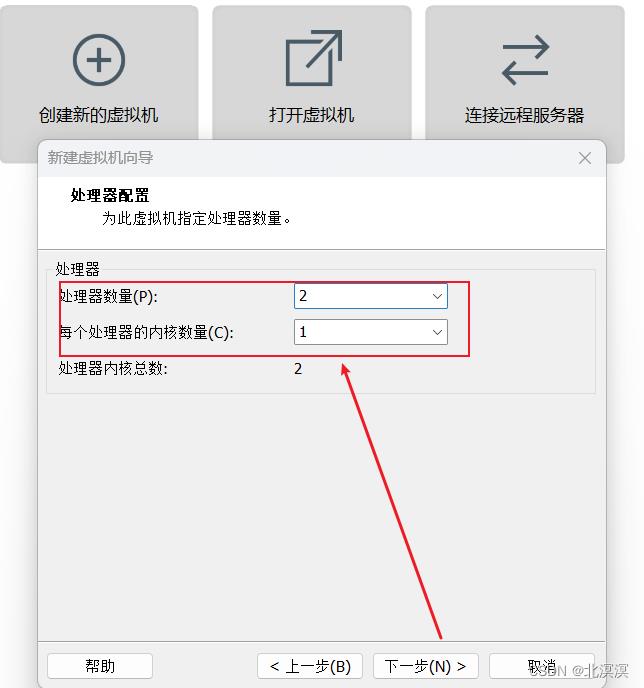
⑤配置处理器数量
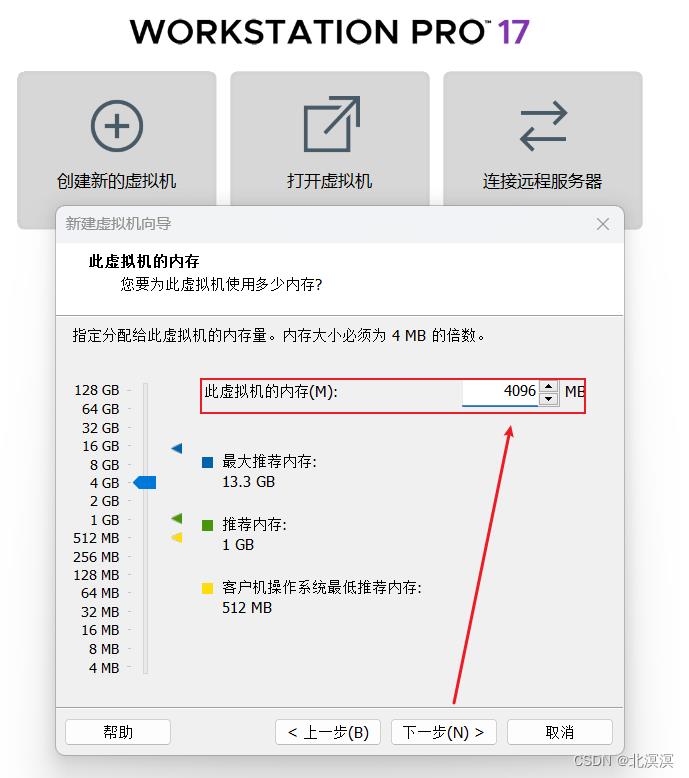
⑥配置虚拟机内存
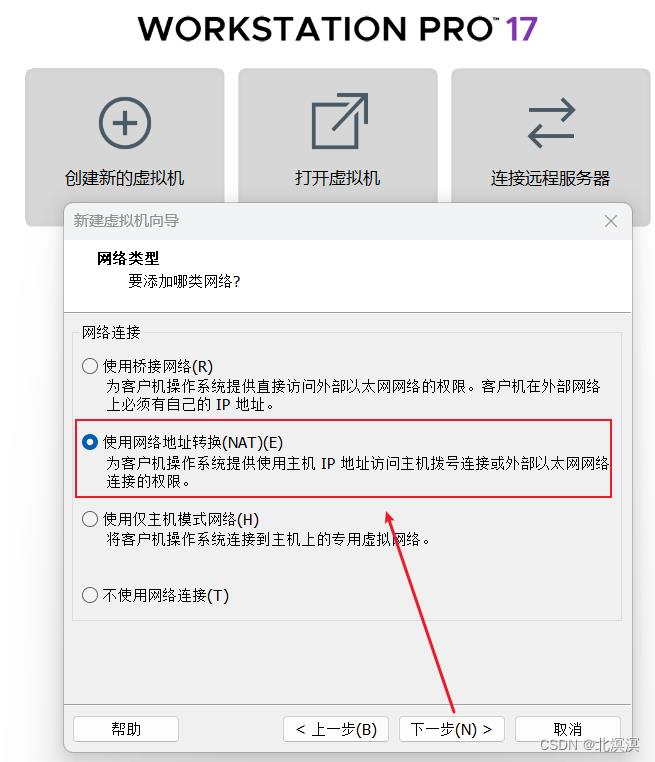
⑦选择NAT网络
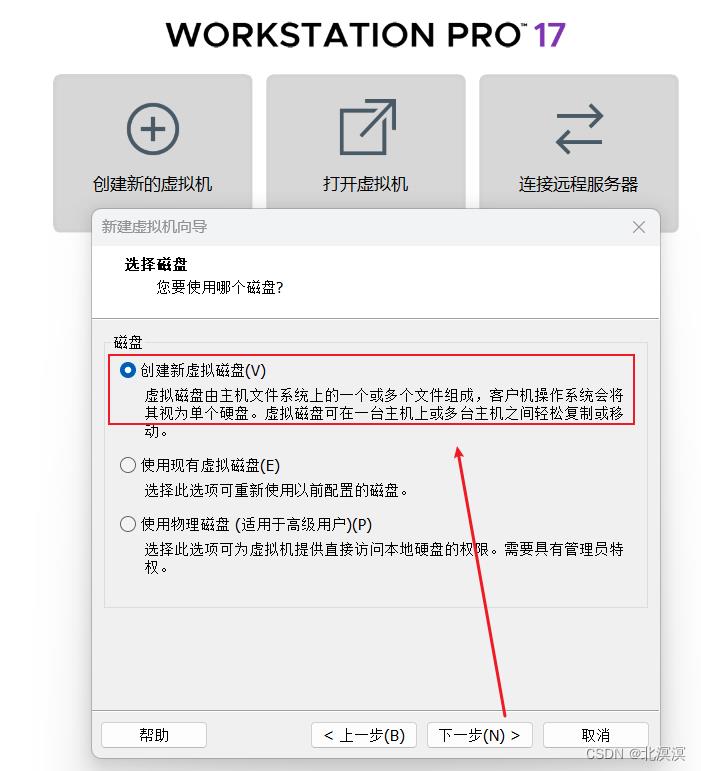
⑧控制器和磁盘格式选择推荐的,选择创建新虚拟磁盘
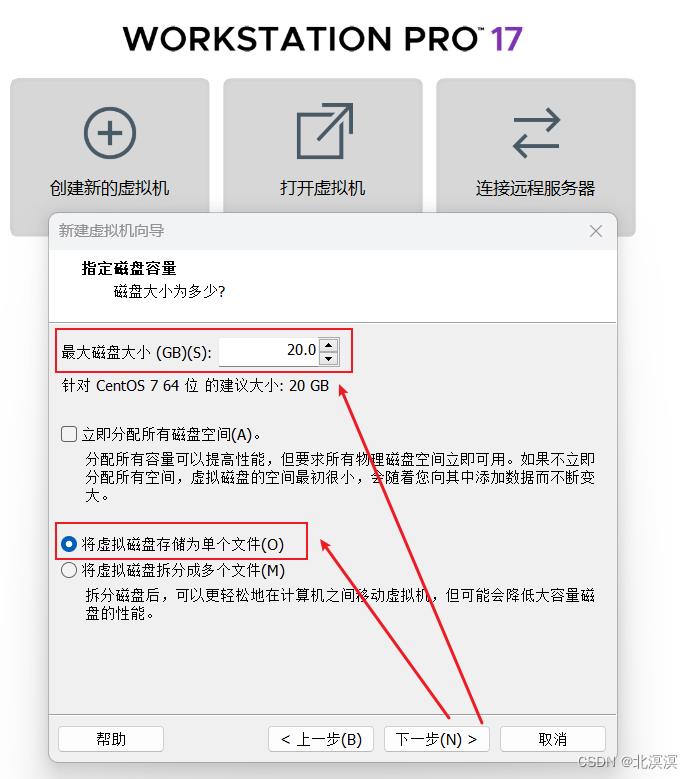
⑨分配磁盘容量
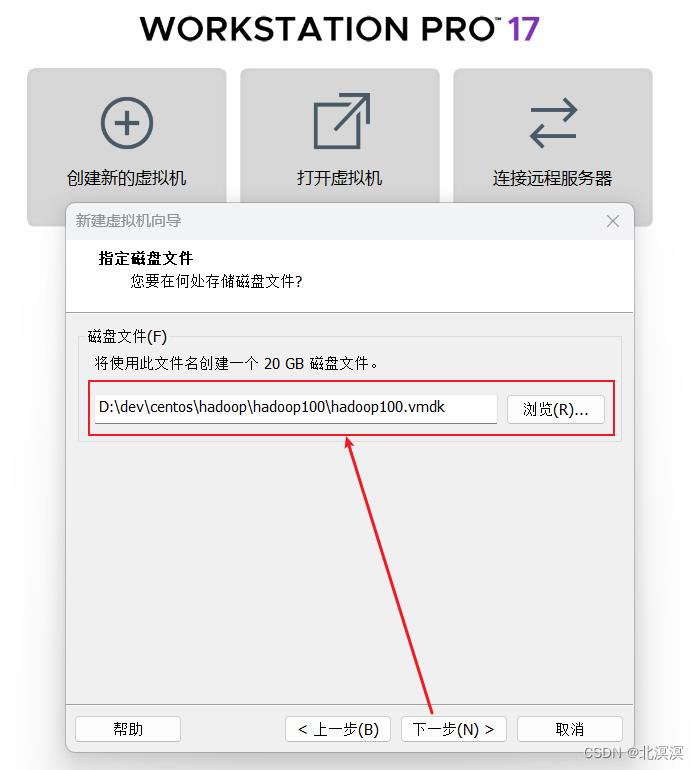
⑩选择磁盘文件存储位置
⑪点击完成

- 安装虚拟机
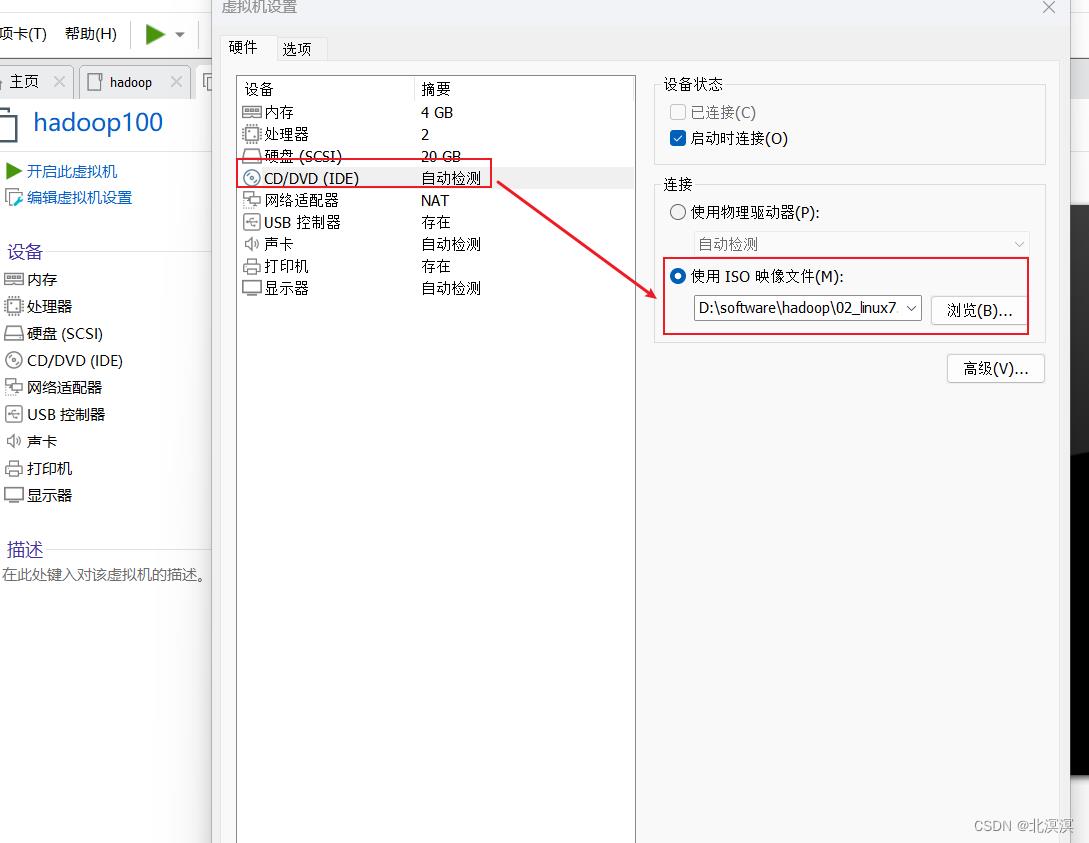
①配置centos的虚拟机镜像
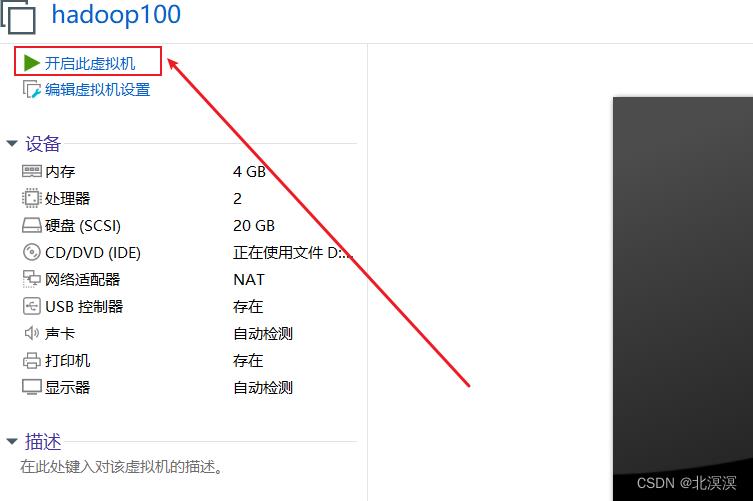
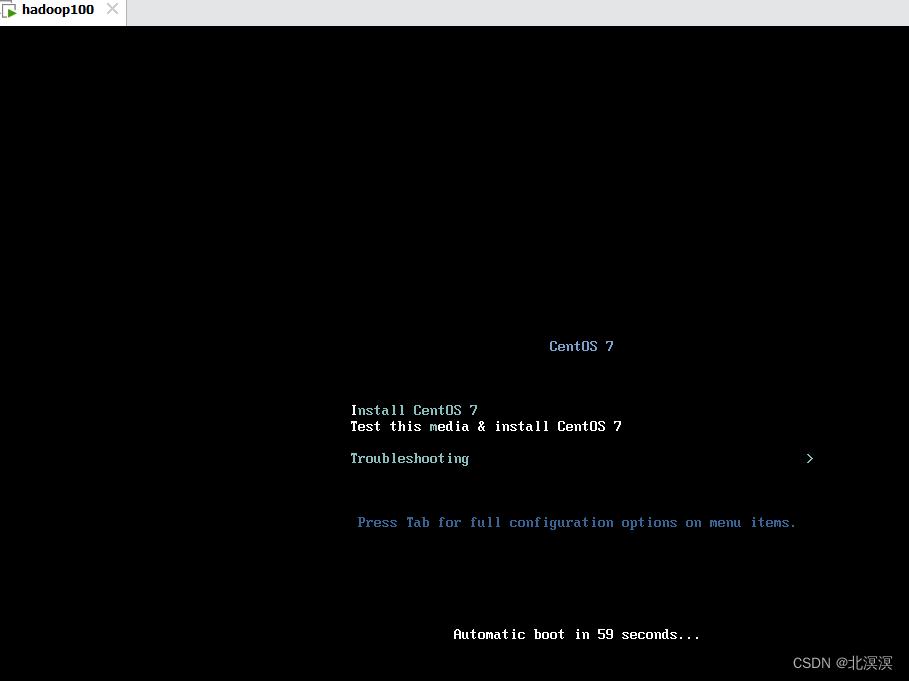
②启动虚拟机
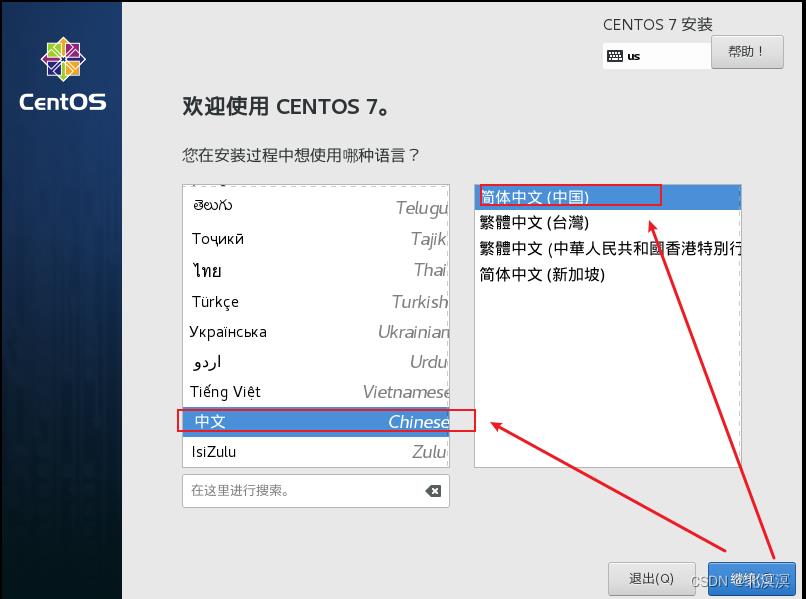
③选择中文安装
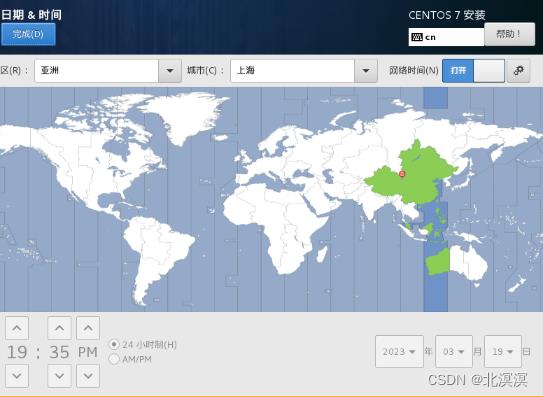
④修改系统时间
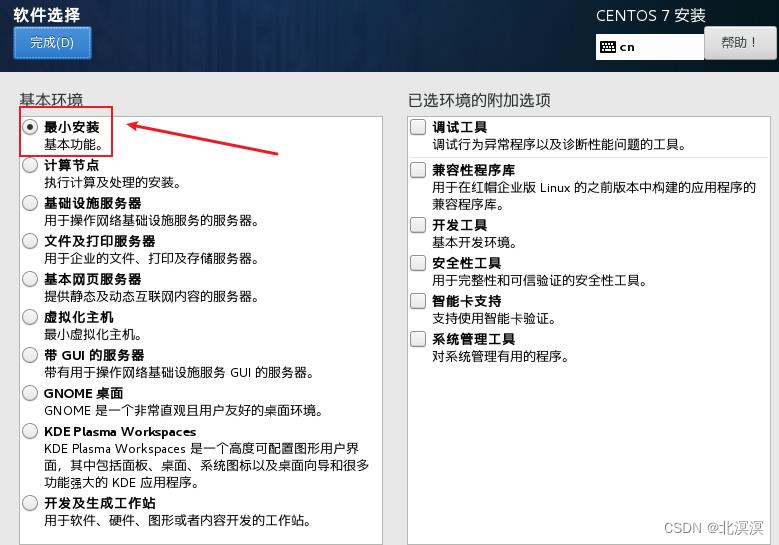
⑤软件安装选择最小安装,也可以选择安装有桌面的虚拟机,作者这里选择最小安装
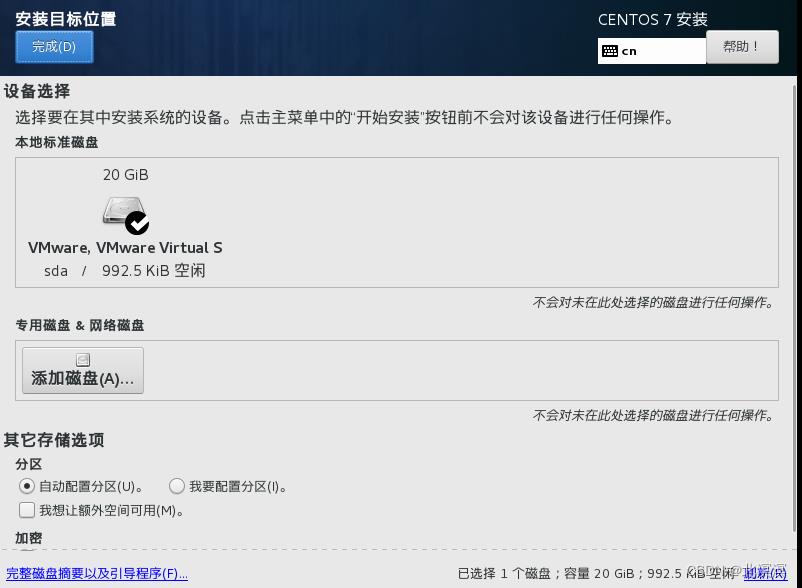
⑥安装位置选择自动分区
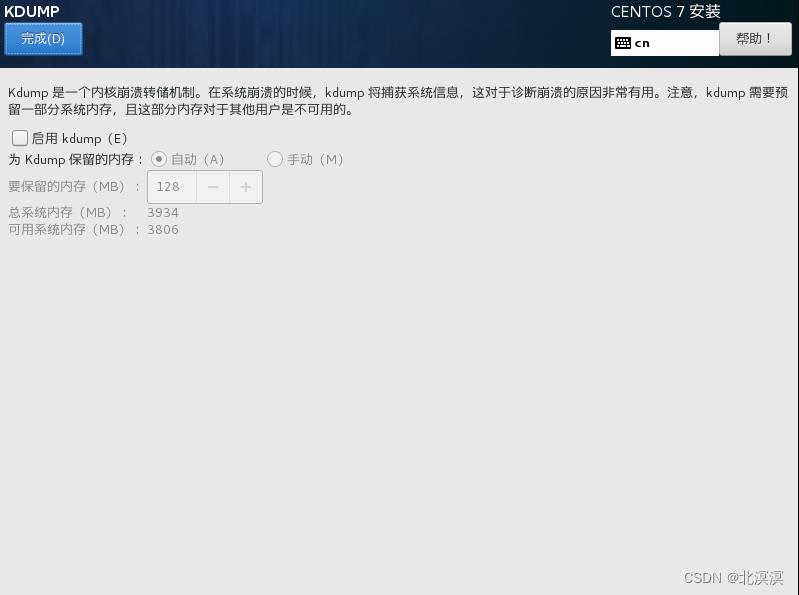
⑦禁用Kdump,节省资源,也可以不关
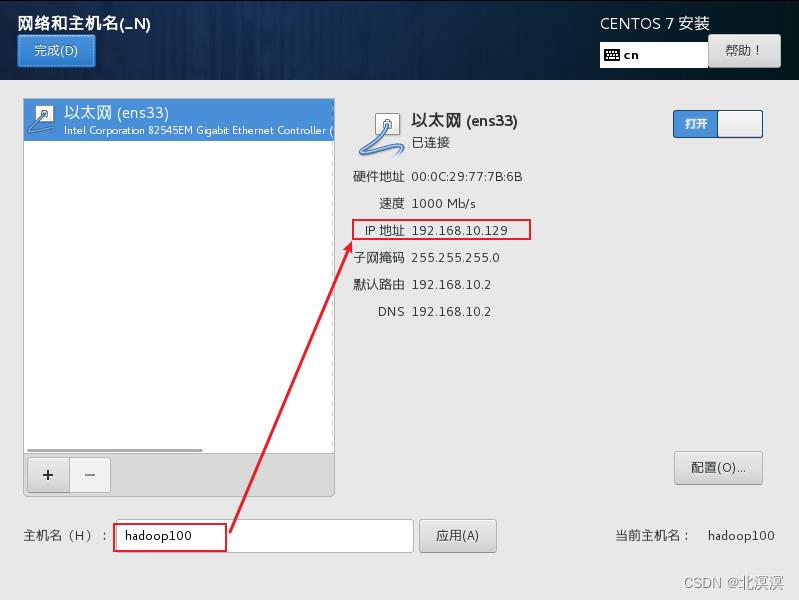
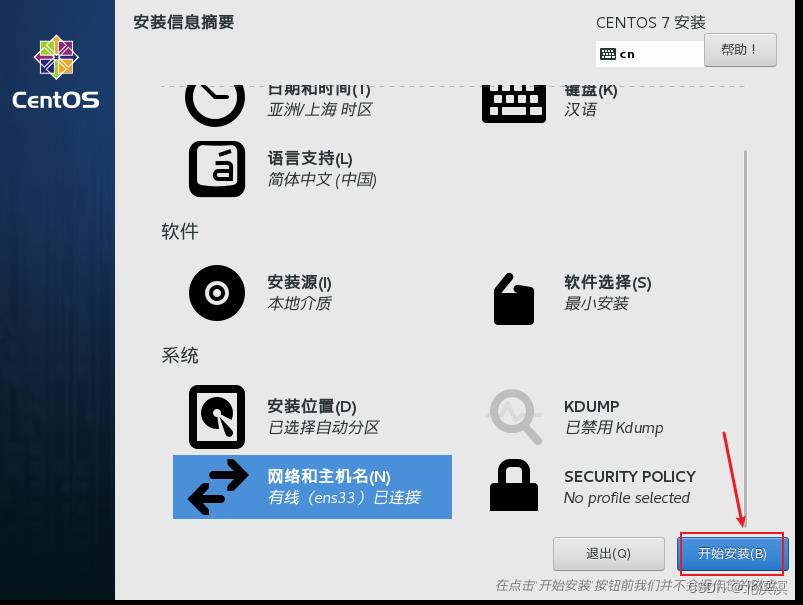
⑧网络和主机,主机名改为hadoop100,打开网络连接
⑨开始安装
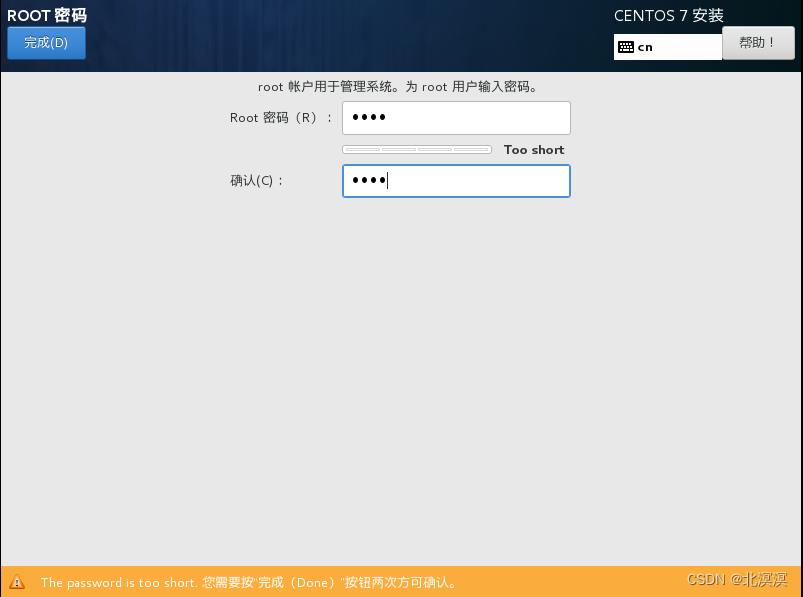
⑩设置root用户密码
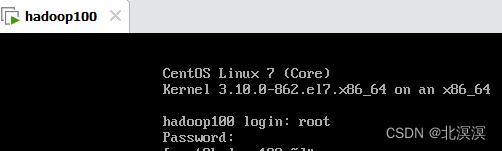
⑪等待安装完成,重启虚拟机,使用root账号登录
结语
关于centos虚拟机安装的部分到这里就结束了,我们下期见。。。。。。
以上是关于大数据实战——hadoop集群安装搭建的主要内容,如果未能解决你的问题,请参考以下文章