用Cobar做MySql集群时关于Schema.xml的配置问题
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了用Cobar做MySql集群时关于Schema.xml的配置问题相关的知识,希望对你有一定的参考价值。
配置Schema中,有大量的表,用相同的dataNode,相同的rule.有没有简单的配置方法?总不能多少张表就弄多少个table节点吧,那样这个xml解析岂不慢死?
各dataSource的用户名和密码能不能不写在配置文件中?写到中间件或者拿到别地方?
Ø dataNode:数据节点,由主、备数据源,数据源的HA以及连接池共同组成,可以将一个dataNode理解为一个分库。
Ø table:表,包括拆分表(如tb1,tb2)和非拆分表。
Ø tableRule:路由规则,用于判断SQL语句被路由到具体哪些datanode执行。
Ø schema:cobar可以定义包含拆分表的schema(如schema1),也可以定义无拆分表的schema(如schema2)。
Ø 以上层次关系具有较强的灵活性,用户可以将表自由放置不同的datanode,也可将不同的datasource放置在同一mysql实例上
这方面是有点不太好理解,慢慢体会!
由Cobar引起的Mysql锁问题
题外话
使用Cobar将近一年了,但对其原理仍旧不是很了解,更没阅读过源码,说起来也是惭愧。趁着最近线上的一次故障,总算说服自己花时间来看看Cobar的真面目。
我们公司对它的印象很差,因为经常出现各种不稳定。比如Cobar在执行一条复杂查询的过程中,同时执行一条普通的selectById都有可能爆出Unsupport Command。
线上故障
最近的这次线上故障更为严重:因为在底层Mysql层面捕捉到了锁,并且多个session长时间的在等待该锁直到超时(锁超时时间是50s)。此时的Cobar完全就处于一个近似于僵死的状态。当时的场景是一个接口的并发调用,这个并发调用会更新同一个人的账户余额,简化成SQL类似于
update `user` set balance = balance - 5 where id = 1;并发度大概在30+左右。Mysql层面捕捉到的也都是id为1这条记录的行级锁(row-level locking),锁超时时间是50s,当时应用有大量更新这条记录的锁超时爆出。最后,其余访问cobar的线程也被阻塞。
临时方案
线上故障在无法立即找出原因并解决的情况下,我们必须要有紧急预案或者说是临时方案。当时的问题产生是由于某个定时任务去并行对某个用户的账号做扣罚。于是我们将该扣罚金额参数调整成了0,至此,Cobar恢复正常。
抛出疑问
当然,临时方案只是为了暂时先恢复正常运营。下面的工作就要找出问题真正的原因。
针对上面的故障场景,当时产生了几点疑问:
- 为什么某条Sql会占用id为1的行锁超过50s甚至更长?
- 为什么id为1的行锁占用会影响到整个
Cobar的服务?
我们留着这两点疑问先慢慢往下看。
场景还原
故障之后有同事在重现该场景并寻找原因,根据数据源和事务提交方式的不同,在并发度为500的情况下,分别测试了如下几种场景:
| 数据源 | 事务提交方式 | 是否重现 |
|---|---|---|
| Cobar | 自动 | 否 |
| Cobar | 手动 | 是 |
| 直连Mysql | 自动 | 否 |
| 直连Mysql | 手动 | 否 |
只有在使用Cobar并采用手动提交事务的情况下,才会出现Cobar僵死的情况。这个测试模拟了一个最简单并且足以说明问题的场景,单表一条主键id为1的记录,对其做update操作。更不用说并发500了,30+的情况也完全能把Cobar给搞挂。
原理探究
到这里大家可能就开始质疑Cobar了,真的是Cobar的并发低到只有30+?
带着这样的质疑,我踏上了一条为Cobar正名的“不归路”。通过官方文档以及Cobar的源代码,梳理出了Cobar的大致结构,下面是简化后的结构图:
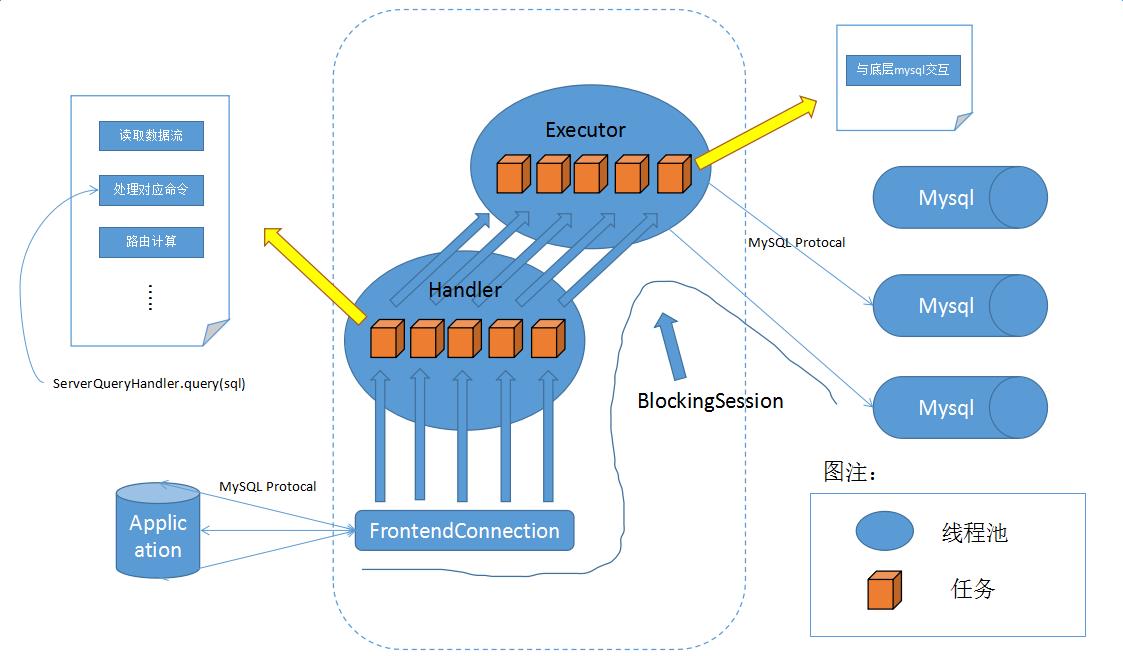
可以看到,Cobar实现了Mysql协议,伪装成Mysql服务端与我们的应用进行通讯,这样我们的应用就可以像直连Mysql一样操作Cobar了。应用与Cobar建立连接,然后通过Mysql协议将请求发到Cobar,Cobar解析报文然后根据命令的不同执行不同的操作。其中涉及到两个线程池,如上图所示,在Cobar中命名这两个线程池为:Handler和Executor:Handler的主要工作是读取数据流,解析报文,处理对应命令,路由计算等。而具体要和底层的Mysql打交道的工作就交给Executor来完成了。我们来举个简单的例子,就拿前面的update语句来简单分析一下(建立连接这块先不说):
update `user` set balance = balance - 5 where id = 1;假设应用和Cobar之间已经建立起了连接,那么Cobar就开始从应用读取数据流,一旦读到数据流,那么Cobar会简单处理数据包,待获得一个完整的数据包之后将此数据包打包成一个任务丢给Handler去执行。该任务的内容包含:
- 根据
Mysql协议来解析数据包(枯燥的过程,例如包头4个字节,第五个字节代表具体的命令类型,诸如此类的东西) - 通过第一步可以解析出命令类型以及具体的SQL,下面以Query这种命令类型为例,这也是最常用的(这里的查询不局限select,crud都属于Query)
- 根据SQL进行路由计算,针对于单节点和多节点处理略有不同
最后将携带了路由信息的数据包打包成任务丢到Executor中去执行,这块任务要做的是:
- 根据路由信息关联
Mysql通道 - 针对该会话绑定
Mysql通道,主要是为了关联事务 - 发送数据包到
Mysql并等待返回结果
提出猜想
通过上面的分析,再来想想之前提出过的两点疑问:
- 为什么某条Sql会占用id为1的行锁超过50s甚至更长?
- 为什么id为1的行锁占用会影响到整个
Cobar的服务?
这边先来简单普及一个知识点,一般的手动事务需要三个步骤:
- set autocommit = 0;
- Query Command
- commit/rollback
在正常情况下根据主键update肯定不可能超过50s,那么只有一种情况,那就是update操作之后没有commit。
为什么会没有commit呢,是不是Executor被挤满了?
为什么Executor满了?因为堵满了update
这看起来像不像一个死锁(DeadLock)问题?
Executor中的某条线程(ThreadA)获取了锁,其余大多数线程都在等待该锁。假设此时update线程足够多并且都因为等待锁而阻塞,进而堵满了Executor。那么那条获得了锁的线程也就没有空余线程来释放锁了(commit/rollback)。DeadLock!
验证猜想
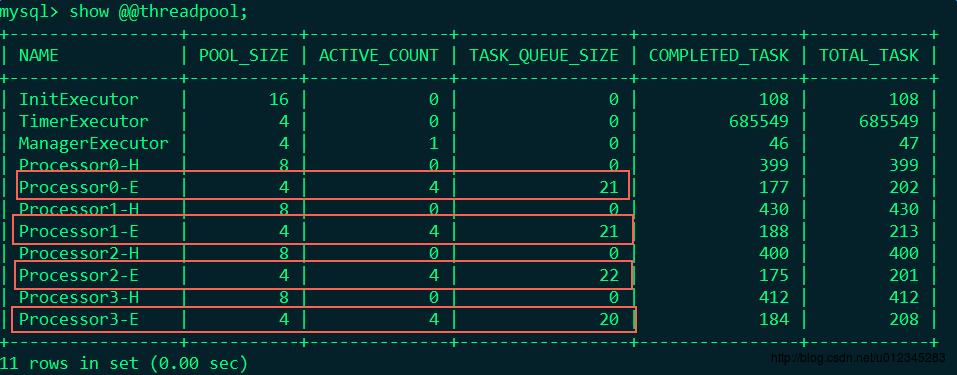
首先,我们来重现场景,和上面写的场景还原一样,采用500个线程来并发更新一条记录:
update `user` set balance = balance - 5 where id = 1;不出意料,场景又再现了。此时,我们通过Cobar提供的管理节点来监控线程池,发现Executor跑满了,并且队列中还堆积了好多请求:
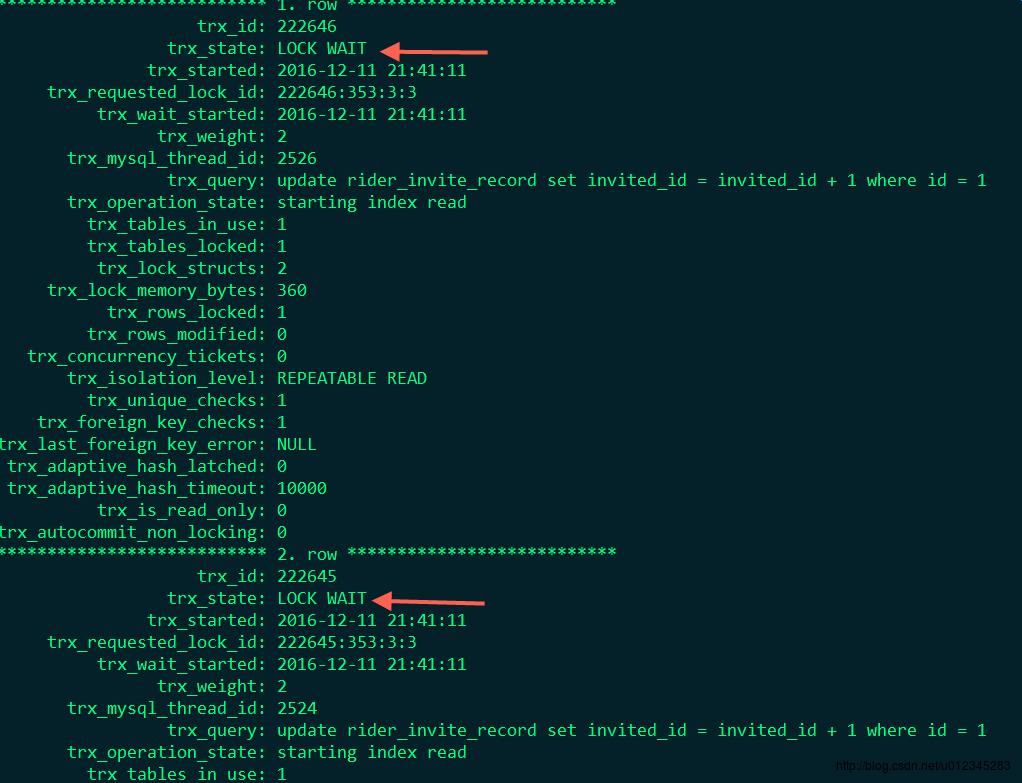
此时再去底层的Mysql看看,发现此时大量锁超时:
为了证明线程池里堵得全都是update,又通过修改Cobar源码打印出了Executor中任务执行的日志。至此,问题已经非常清晰,并且同时也解释了为什么在自动提交事务的场景下不会发生堵塞。
那么可以开始考虑解决方案了。
解决方案
1、加大Executor的线程池大小,这应该也是最容易想到的方式。Cobar会根据CPU核心数创建N个Executor,假设将Executor的线程池大小调整到256,那么理论上可支持对同一条记录的并发操作数可达到 N * 256。
优点:改起来非常方便,本身Cobar配置文件就有暴露该配置项
缺点:总觉得有点治标不治本的味道,并发量过高还是会有阻塞的危机
当然可以搭配死锁检查或对于线程中执行时间过长的SQL直接Kill并报警等机制
2、再定义一种线程池,单独用来执行commit/rollback命令
优点:将资源隔离,可以从本质上来解决死锁问题
缺点:需要改动Cobar源代码,可能需要经过一轮全面的测试才能使用到生产环境
3、暂时没想到
对于前两种方案我都实践了并且测试过,都可以达到想要的效果。个人还是倾向于第二种,但是第一种可以作为过渡方案。
结束语
上面说的第一种方案在Cobar现有的架构下是必不可少的。必须要调到合适的线程数,如果系统瓶颈被卡在这里,那岂不是资源浪费?
感觉这个问题算是Cobar隐藏的一个BUG吧。可能在设计之初并没有考虑到一些对同一条记录高并发的更新场景。网上也没有太多关于这方面的文章。这篇文章算是一个探路者,为我之后研究开元中间件开一个好头~
以上是关于用Cobar做MySql集群时关于Schema.xml的配置问题的主要内容,如果未能解决你的问题,请参考以下文章