STL源码剖析——iterators与trait编程#3 iterator_category
Posted misakijh
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了STL源码剖析——iterators与trait编程#3 iterator_category相关的知识,希望对你有一定的参考价值。
最后一个迭代器的相应类型就是iterator_category,就是迭代器本身的类型,根据移动特性与实行的操作,迭代器被分为了五类:
- Input Iterator:这种迭代器所指的对象,不允许外界改变。只读(read only)。
- Output Iterator:唯写(write only)
- Forward Iterator:允许写入型算法在此种迭代器所形成的区间上进行读写操作,具有Input迭代器的全部功能和Output迭代器的大部分功能。支持++运算符。
- Bidirectional Iterator:可双向移动。某些算法需要逆向遍历某个迭代器区间,可以使用Bidirectional Iterator。在Forward的基础上支持--运算符。
- Random Access Iterator:前四种迭代器都只供应一部分指针算术能力(operator++、operator--),而这种则涵盖所有指针算数能力,包括p+n、p-n、p[n]、p1-p2、p1<p2
这些迭代器的分类与从属关系,下图可以表示,直线与箭头代表的并非C++的继承关系,而是concept(概念)与refinement(强化)的关系。
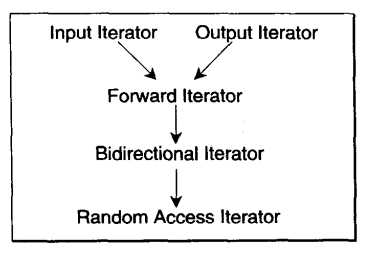
设计算符时,如果可能,我们尽量针对图中的某种迭代器提供一个明确的定义,并针对更强化的某种迭代器提供另一种定义,这样才能在不同情况下提供最大效率。假设有个算法可接受Forward Iterator,你以Random Access Iterator喂给它,它当然也接受,因为一个Random Access Iterator一定是一个Forward Iteartor。但是可用并不是代表最佳。
例如最近我刚好看到copy()函数,它就为不同的迭代器定义了不同的复制方法,它提供了Input Iterator的特化版本和针对更强化的Random Access Iteartor的特化版本,为什么如此?因为于非随机迭代器而言,它们无法做到迭代器之间的减法处理(operator-()),所以每次循环判断是否达到被复制区间的尾部时,只能与last(区间为[first, last) )迭代器进行比较,这个就是Input Iterator的特化版本;而针对更强化的随机迭代器而言,因为其提供的减法处理,所以可以利用difference type记录区间大小(last - first),然后在复制循环中只用判断循环次数是否超过区间大小就好了,这个就是Random Access Iterator的特化版本,相对而言后者的速度显然比前者快很多,这就是在不同情况下提供最大效率。
但重点是,我们必须有能力去萃取出迭代器的种类,才能调用到相应的特化版本。这最后一个迭代器的相应类型一定必须是一个类(class type),不能只是数值号码之类的东西,因为编译器需要仰赖它来进行重载判断。下面定义五个classes,代表五种迭代器类型:
1 struct input_iterator_tag {}; 2 struct output_iterator_tag {}; 3 struct forward_iterator_tag :public input_iterator {}; 4 struct bidirectional_iterator_tag :public forward_iterator_tag {}; 5 struct random_access_iterator_tag :public bidirectional_iterator_tag {};
这些classes只作为标记用,所以不需要任何成员。至于为什么运用继承机制,它可以促成重载机制的成功运作,另一个好处是,通过继承,我们可以不必写“单纯只做传递调用”的函数,我们可以做一个小测试:
1 struct B {}; //B 可比拟为Input Iterator 2 struct D1 :public B {}; //D1可比拟为Forward Iterator 3 struct D2 :public D1 {};//D2可比拟为Bidirectional Iterator 4 5 template<typename I> 6 func(I& p, B) 7 { 8 cout << "B version" << endl; 9 } 10 template<typename I> 11 func(I& p, D2) 12 { 13 cout << "D2 version" << endl; 14 } 15 int main() 16 { 17 int *p; 18 func(p, B()); //输出“B version” 19 func(p, D1()); //输出“B version” 20 func(p, D2()); //输出“D2 version” 21 }
何为“单纯只做传递调用”的函数,如果Forward Iteartor的特化版本的功能Input Iterator也能做到,那在非继承情况下,它是如下的,以advance函数的内部函数__advance()为例,该函数具有跳到容器内某指定位置的功能:
1 //Distance即为两迭代器距离类型(difference type) 2 template<typename InputIterator, typename Distance> 3 inline void __advance(InputIterator& i, Distance n, input_iterator_tag) 4 { 5 //单向,逐一前进 6 while (n--)++i; 7 } 8 9 template<typename InputIterator, typename Distance> 10 inline void __advance(InputIterator& i, Distance n, forward_iterator_tag) 11 { 12 __advance(i, n, input_iterator_tag()); //单纯的转调用 13 }
如果是继承的情况下,只需写一个Input Iteartor版本即可,而无需再写一个Forward Iteartor特化版本然后做传递调用处理。而因处理方式不一,它还提供了Bidirectional Iteartor的特化版本和Random Access Iteartor的特化版本,这里不再赘述,但有必要提一下其上层对外开放接口advance函数,这一上层接口只需两个参数,当它准备将工作转给上述的__advance()时,才自行加上第三参数:迭代器类型。因此,这个上层函数必须有能力从它所获得的迭代器推导出其类型——这份工作自然是交给traits机制:
1 template<typename InputIterator, typename Distance> 2 inline void advance(InputIterator& i, Distance n) 3 { 4 __advance(i, n, 5 iterator_traits<InputIterator>::iteartor_category()); 6 }
iterator_traits<InputIterator>::iteartor_category()将产生一个临时对象,其类型应该隶属于前述四个迭代器类型(I、F、B、R)之一。然后,根据这个类型,编译器才决定调用哪一个__advance()重载函数。
因此,为了满足上述行为,traits必须在增加一个相应类型:
1 template<typename I> 2 struct iterator_traits 3 { 4 ... 5 typedef typename I::iterator_category iterator_category; 6 }; 7 template<typename T> 8 struct iterator_traits<T*> 9 { 10 ... 11 //原生指针是一种Random Access Iterator 12 typedef typename random_access_iterator_tag iterator_category; 13 }; 14 struct iterator_traits<const T*> 15 { 16 ... 17 //原生pointer-to-const是一种Random Access Iterator 18 typedef typename random_access_iterator_tag iterator_category; 19 };
一个迭代器的类型,应该是各种迭代器类型中最强的那个,例如int*,既是Random Access Iterator,又是Bidirectional Iterator,同时也是Forward Iterator,而且也是Input Iteartor,那么,其类型应该归属为randm_access_iterator_tag。
另外还需注意的是STL算法的一个命名规则,如advance(),其迭代器类型参数命名为InputIteartor,这表示只要其迭代器类型的基类为input_iteartor_tag,该函数就能接受,即接受各种类型的迭代器。以算法所能接受之最低阶迭代器类型,来为其迭代器类型参数命名。
std::iterator的保证
为了符合规范,任何迭代器都应该提供相应类型,否则便是有别于整个STL整个架构,可能无法与其他STL组件顺利搭配。因此STL提供了一个iteartor class,如果每个新设计的迭代器都继承自它,就可保证符合STL规范:
template <class Category, class T, class Distance = ptrdiff_t, class Pointer = T*, class Reference = T&> struct iterator { typedef Category iterator_category; typedef T value_type; typedef Distance difference_type; typedef Pointer pointer; typedef Reference reference; };
iteartor class不含任何成员,纯粹只是类型定义,所以继承它并不会带来任何额外的负担。由于后三个参数皆有默认值,故新的迭代器只需提供前两个参数即可。如我们第一节土法炼钢的ListIter,如果改用正式规格,应该这么写:
1 template<typename Item> 2 struct ListIter: public std::iterator<std::forward_iterator_tag, Item> 3 {...}
设计适当的相应类型,是迭代器的责任。设计适当的迭代器,则是容器的责任。唯容器本身,才知道设计出怎样的迭代器来遍历自己,并执行迭代器该有的各种行为。至于算法,完全可以独立于容器和迭代器之外自行发展,只要设计时以迭代器为对外接口就行。
以上是关于STL源码剖析——iterators与trait编程#3 iterator_category的主要内容,如果未能解决你的问题,请参考以下文章