数据结构学习总结 栈和队列
Posted 2019wxw
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据结构学习总结 栈和队列相关的知识,希望对你有一定的参考价值。

图 1 栈存储结构示意图
1,栈只能从表的一端存取数据,另一端是封闭的,如图 1 所示;2,在栈中,无论是存数据还是取数据,都必须遵循"先进后出"的原则,即最先进栈的元素最后出栈。拿图 1 的栈来说,从图中数据的存储状态可判断出,元素 1 是最先进的栈。因此,当需要从栈 中取出元素 1 时,根据"先进后出"的原则,需提前将元素 3 和元素 2 从栈中取出,然后才能成功取出元素 1。
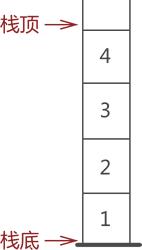
图 2 栈顶和栈底
进栈和出栈
基于 栈结构的特点,在实际应用中,通常只会对栈执行以下两种操作:- 向栈中添加元素,此过程被称为"进栈"(入栈或压栈);
- 从栈中提取出指定元素,此过程被称为"出栈"(或弹栈);
栈的具体实现
栈是一种 "特殊" 的线性存储结构,因此栈的具体实现有以下两种方式:
两种实现方式的区别,仅限于数据元素在实际物理空间上存放的相对位置,顺序栈底层采用的是数组,链栈底层采用的是链表。有关顺序栈和链栈的具体实现会在后续章节中作详细讲解。
栈的应用
基于栈结构对数据存取采用 "先进后出" 原则的特点,它可以用于实现很多功能。例如,我们经常使用浏览器在各种网站上查找信息。假设先浏览的页面 A,然后关闭了页面 A 跳转到页面 B,随后又关闭页面 B 跳转到了页面 C。而此时,我们如果想重新回到页面 A,有两个选择:
- 重新搜索找到页面 A;
- 使用浏览器的"回退"功能。浏览器会先回退到页面 B,而后再回退到页面 A。
不仅如此,栈存储结构还可以帮我们检测代码中的括号匹配问题。多数编程语言都会用到括号(小括号、中括号和大括号),括号的错误使用(通常是丢右括号)会导致程序编译错误,而很多开发工具中都有检测代码是否有编辑错误的功能,其中就包含检测代码中的括号匹配问题,此功能的底层实现使用的就是栈结构。
同时,栈结构还可以实现数值的进制转换功能。例如,编写程序实现从十进制数自动转换成二进制数,就可以使用栈存储结构来实现。
以上也仅是栈应用领域的冰山一角,这里不再过多举例。在后续章节的学习中,我们会大量使用到栈结构。
接下来,我们学习如何实现顺序栈和链栈,以及对栈中元素进行入栈和出栈的操作。
{1,2,3,4},存储状态如图 1 所示:
图 1 顺序表存储 {1,2,3,4}
{1,2,3,4},其存储状态如图 2 所示:
图 2 栈结构存储 {1,2,3,4}
从数组下标为 0 的模拟栈存储数据是常用的方法,从其他数组下标处存储数据也完全可以,这里只是为了方便初学者理解。
顺序栈元素"入栈"
{1,2,3,4} 的过程。最初,栈是"空栈",即数组是空的,top 值为初始值 -1,如图 3 所示:
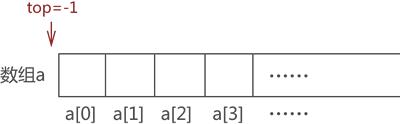
图 3 空栈示意图
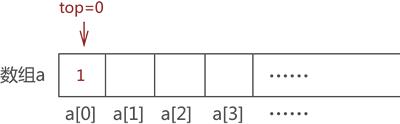
图 4 模拟栈存储元素 1
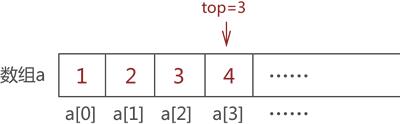
图 5 模拟栈存储{1,2,3,4}
因此,C 语言实现代码为:
//元素elem进栈,a为数组,top值为当前栈的栈顶位置 int push(int* a,int top,int elem){ a[++top]=elem; return top; }
代码中的 a[++top]=elem,等价于先执行 ++top,再执行 a[top]=elem。
顺序栈元素"出栈"
其实,top 变量的设置对模拟数据的 "入栈" 操作没有实际的帮助,它是为实现数据的 "出栈" 操作做准备的。比如,将图 5 中的元素 2 出栈,则需要先将元素 4 和元素 3 依次出栈。需要注意的是,当有数据出栈时,要将 top 做 -1 操作。因此,元素 4 和元素 3 出栈的过程分别如图 6a) 和 6b) 所示:
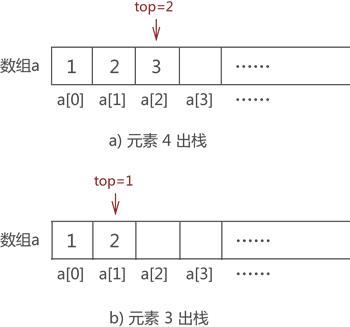
图 6 数据元素出栈
注意,图 6 数组中元素的消失仅是为了方便初学者学习,其实,这里只需要对 top 值做 -1 操作即可,因为 top 值本身就表示栈的栈顶位置,因此 top-1 就等同于栈顶元素出栈。并且后期向栈中添加元素时,新元素会存储在类似元素 4 这样的旧元素位置上,将旧元素覆盖。
//数据元素出栈 int pop(int * a,int top){ if (top==-1) { printf("空栈"); return -1; } printf("弹栈元素:%d ",a[top]); top--; return top; }
代码中的 if 语句是为了防止用户做 "栈中已无数据却还要数据出栈" 的错误操作。代码中,关于对栈中元素出栈操作的实现,只需要 top 值 -1 即可。
总结
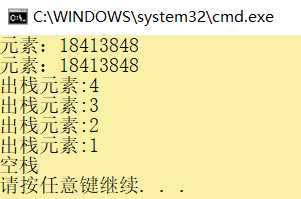
通过学习顺序表模拟栈中数据入栈和出栈的操作,初学者完成了对顺序栈的学习,这里给出顺序栈及对数据基本操作的 C 语言完整代码:#include <stdio.h> //元素elem进栈 int push(int* a,int top,int elem){ a[++top]=elem; return top; } //数据元素出栈 int pop(int * a,int top){ if (top==-1) { printf("空栈"); return -1; } printf("弹栈元素:%d ",a[top]); top--; return top; } int main() { int a[100]; int top=-1; top=push(a, top, 1); top=push(a, top, 2); top=push(a, top, 3); top=push(a, top, 4); top=pop(a, top); top=pop(a, top); top=pop(a, top); top=pop(a, top); top=pop(a, top); return 0; }
程序输出结果为:
链栈的实现思路同顺序栈类似,顺序栈是将数顺序表(数组)的一端作为栈底,另一端为栈顶;链栈也如此,通常我们将链表的头部作为栈顶,尾部作为栈底,如图 1 所示:

图 1 链栈示意图
- 在实现数据"入栈"操作时,需要将数据从链表的头部插入;
- 在实现数据"出栈"操作时,需要删除链表头部的首元节点;
链栈元素入栈
例如,将元素 1、2、3、4 依次入栈,等价于将各元素采用头插法依次添加到链表中,每个数据元素的添加过程如图 2 所示:
图 2 链栈元素依次入栈过程示意图
//链表中节点结构 typedef struct lineStack{ int data; struct lineStack* next; }; //压栈 stack 当前链栈 a 入栈元素 lineStack* push(lineStack* stack,int a) { //创建存储新元素的节点 lineStack* temp = (lineStack*)malloc(sizeof(lineStack)); temp->data = a; //新节点与头节点建立关联 temp->next = stack; //更新头指针指向 stack = temp; return stack; }
链栈元素出栈
例如,图 2e) 所示的链栈中,若要将元素 3 出栈,根据"先进后出"的原则,要先将元素 4 出栈,也就是从链表中摘除,然后元素 3 才能出栈,整个操作过程如图 3 所示:
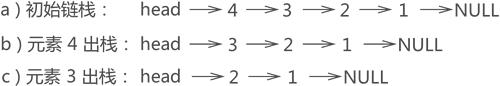
图 3 链栈元素出栈示意图
//栈顶元素出栈的实现函数 lineStack* pop(lineStack* stack) { if (stack) { //声明一个新指针指向栈顶节点 lineStack *p = stack; //更新头节点 stack = stack->next; printf("出栈元素:%d ",p->data); if (stack) { printf("新栈顶元素:%d ",stack->data); } else { printf("栈已空 "); } free(p); } else { printf("栈内没有元素 "); return stack; } return stack;
代码中通过使用 if 判断语句,避免了用户执行"栈已空却还要数据出栈"错误操作。
总结
本节,通过采用头插法操作数据的单链表实现了链栈结构,这里给出链栈及基本操作的C语言完整代码:

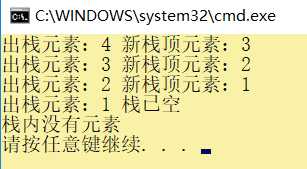
#include<stdlib.h> #include<stdio.h> //链表中节点结构 typedef struct lineStack{ int data; struct lineStack* next; }; //压栈 stack 当前链栈 a 入栈元素 lineStack* push(lineStack* stack,int a) { //创建存储新元素的节点 lineStack* temp = (lineStack*)malloc(sizeof(lineStack)); temp->data = a; //新节点与头节点建立关联 temp->next = stack; //更新头指针指向 stack = temp; return stack; } //栈顶元素出栈的实现函数 lineStack* pop(lineStack* stack) { if (stack) { //声明一个新指针指向栈顶节点 lineStack *p = stack; //更新头节点 stack = stack->next; printf("出栈元素:%d ",p->data); if (stack) { printf("新栈顶元素:%d ",stack->data); } else { printf("栈已空 "); } free(p); } else { printf("栈内没有元素 "); return stack; } return stack; } int main() { lineStack * stack = NULL; stack = push(stack, 1); stack = push(stack, 2); stack = push(stack, 3); stack = push(stack, 4); stack = pop(stack); stack = pop(stack); stack = pop(stack); stack = pop(stack); stack = pop(stack); return 0; }
运行结果:
二,顺序表及队列的实现
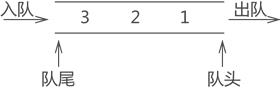
图 1 队列存储结构
通常,称进数据的一端为 "队尾",出数据的一端为 "队头",数据元素进队列的过程称为 "入队",出队列的过程称为 "出队"。
栈和队列不要混淆,栈结构是一端封口,特点是"先进后出";而队列的两端全是开口,特点是"先进先出"。
队列的实现
实际生活中,队列的应用随处可见,比如排队买 XXX、医院的挂号系统等,采用的都是队列的结构。
拿排队买票来说,所有的人排成一队,先到者排的就靠前,后到者只能从队尾排队等待,队中的每个人都必须等到自己前面的所有人全部买票成功并从队头出队后,才轮到自己买票。这就不是典型的队列结构吗?
明白了什么是队列,接下来开始系统地学习顺序队列和链队列。
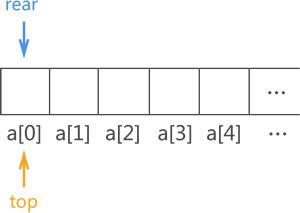
图 1 顺序队列实现示意图
在图 1 的基础上,当有数据元素进队列时,对应的实现操作是将其存储在指针 rear 指向的数组位置,然后 rear+1;当需要队头元素出队时,仅需做 top+1 操作。
{1,2,3,4} 用顺序队列存储的实现操作如图 2 所示: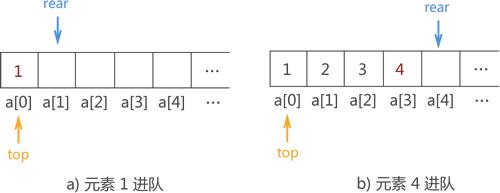
图 2 数据进顺序队列的过程实现示意图
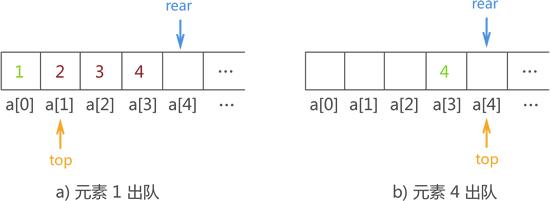
图 3 数据出顺序队列的过程示意图
#include <stdio.h> int enQueue(int *a,int rear,int data){ a[rear]=data; rear++; return rear; } void deQueue(int *a,int front,int rear){ //如果 front==rear,表示队列为空 while (front!=rear) { printf("出队元素:%d ",a[front]); front++; } } int main() { int a[100]; int front,rear; //设置队头指针和队尾指针,当队列中没有元素时,队头和队尾指向同一块地址 front=rear=0; //入队 rear=enQueue(a, rear, 1); rear=enQueue(a, rear, 2); rear=enQueue(a, rear, 3); rear=enQueue(a, rear, 4); //出队 deQueue(a, front, rear); return 0; }
程序输出结果:
出队元素:1
出队元素:2
出队元素:3
出队元素:4
此方法存在的问题
先来分析以下图 2b) 和图 3b)。图 2b) 是所有数据进队成功的示意图,而图 3b) 是所有数据全部出队后的示意图。通过对比两张图,你会发现,指针 top 和 rear 重合位置指向了 a[4] 而不再是 a[0]。也就是说,整个顺序队列在数据不断地进队出队过程中,在顺序表中的位置不断后移。顺序队列整体后移造成的影响是:
- 顺序队列之前的数组存储空间将无法再被使用,造成了空间浪费;
- 如果顺序表申请的空间不足够大,则直接造成程序中数组 a 溢出,产生溢出错误;
顺序队列另一种实现方法
既然明白了上面这种方法的弊端,那么我们可以试着在它的基础上对其改良。为了解决以上两个问题,可以使用巧妙的方法将顺序表打造成一个环状表,如图 4 所
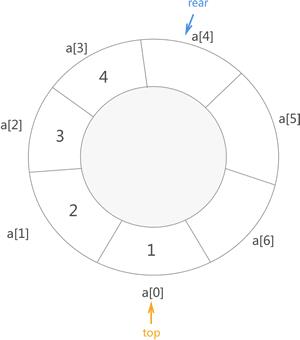
图 4 环状顺序队列
#include <stdio.h> #define max 5//表示顺序表申请的空间大小 int enQueue(int *a,int front,int rear,int data){ //添加判断语句,如果rear超过max,则直接将其从a[0]重新开始存储,如果rear+1和front重合,则表示数组已满 if ((rear+1)%max==front) { printf("空间已满"); return rear; } a[rear%max]=data; rear++; return rear; } int deQueue(int *a,int front,int rear){ //如果front==rear,表示队列为空 if(front==rear%max) { printf("队列为空"); return front; } printf("%d ",a[front]); //front不再直接 +1,而是+1后同max进行比较,如果=max,则直接跳转到 a[0] front=(front+1)%max; return front; } int main() { int a[max]; int front,rear; //设置队头指针和队尾指针,当队列中没有元素时,队头和队尾指向同一块地址 front=rear=0; //入队 rear=enQueue(a,front,rear, 1); rear=enQueue(a,front,rear, 2); rear=enQueue(a,front,rear, 3); rear=enQueue(a,front,rear, 4); //出队 front=deQueue(a, front, rear); //再入队 rear=enQueue(a,front,rear, 5); //再出队 front=deQueue(a, front, rear); //再入队 rear=enQueue(a,front,rear, 6); //再出队 front=deQueue(a, front, rear); front=deQueue(a, front, rear); front=deQueue(a, front, rear); front=deQueue(a, front, rear); return 0; }
程序运行结果:
1 2 3 4 5 6
- 当队列为空时,队列的头指针等于队列的尾指针;
- 当数组满员时,队列的头指针等于队列的尾指针;
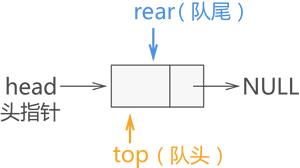
图 1 链式队列的初始状态
在创建链式队列时,强烈建议初学者创建一个带有头节点的链表,这样实现链式队列会更简单。
//链表中的节点结构 typedef struct QNode{ int data; struct QNode * next; }QNode; //创建链式队列的函数 QNode * initQueue(){ //创建一个头节点 QNode * queue=(QNode*)malloc(sizeof(QNode)); //对头节点进行初始化 queue->next=NULL; return queue; }
链式队列数据入队
链队队列中,当有新的数据元素入队,只需进行以下 3 步操作:
- 将该数据元素用节点包裹,例如新节点名称为 elem;
- 与 rear 指针指向的节点建立逻辑关系,即执行 rear->next=elem;
- 最后移动 rear 指针指向该新节点,即 rear=elem;
由此,新节点就入队成功了。
例如,在图 1 的基础上,我们依次将 {1,2,3} 依次入队,各个数据元素入队的过程如图 2 所示:
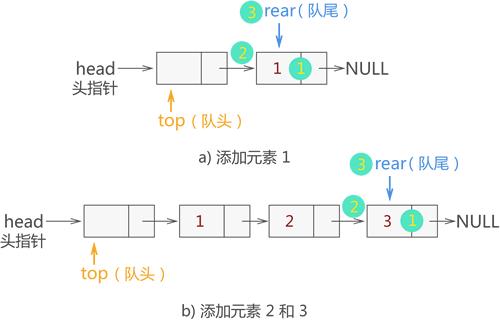
图 2 {1,2,3} 入链式队列
QNode* enQueue(QNode * rear,int data){ //1、用节点包裹入队元素 QNode * enElem=(QNode*)malloc(sizeof(QNode)); enElem->data=data; enElem->next=NULL; //2、新节点与rear节点建立逻辑关系 rear->next=enElem; //3、rear指向新节点 rear=enElem; //返回新的rear,为后续新元素入队做准备 return rear; }
链式队列数据出队
当链式队列中,有数据元素需要出队时,按照 "先进先出" 的原则,只需将存储该数据的节点以及它之前入队的元素节点按照原则依次出队即可。这里,我们先学习如何将队头元素出队。
链式队列中队头元素出队,需要做以下 3 步操作:
- 通过 top 指针直接找到队头节点,创建一个新指针 p 指向此即将出队的节点;
- 将 p 节点(即要出队的队头节点)从链表中摘除;
- 释放节点 p,回收其所占的内存空间;
例如,在图 2b) 的基础上,我们将元素 1 和 2 出队,则操作过程如图 3 所示
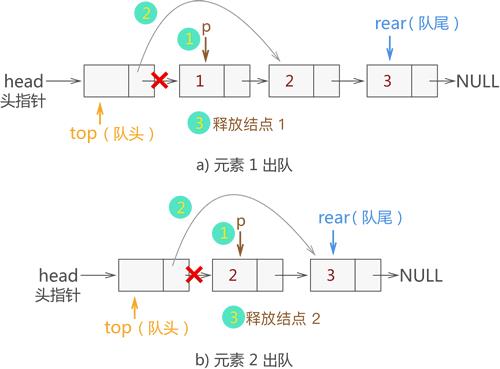
图 3 链式队列中数据元素出队
链式队列中队头元素出队的 C 语言实现代码为:
void DeQueue(QNode * top,QNode * rear){ if (top->next==NULL) { printf("队列为空"); return ; } // 1、 QNode * p=top->next; printf("%d",p->data); top->next=p->next; if (rear==p) { rear=top; } free(p); }
注意,将队头元素做出队操作时,需提前判断队列中是否还有元素,如果没有,要提示用户无法做出队操作,保证程序的健壮性。
总结
通过学习链式队列最基本的数据入队和出队操作,我们可以就实际问题,对以上代码做适当的修改。
前面在学习顺序队列时,由于顺序表的局限性,我们在顺序队列中实现数据入队和出队的基础上,又对实现代码做了改进,令其能够充分利用数组中的空间。链式队列就不需要考虑空间利用的问题,因为链式队列本身就是实时申请空间。因此,这可以算作是链式队列相比顺序队列的一个优势。
这里给出链式队列入队和出队的完整 C 语言代码为:
#include <stdio.h> #include <stdlib.h> typedef struct QNode{ int data; struct QNode * next; }QNode; QNode * initQueue(){ QNode * queue=(QNode*)malloc(sizeof(QNode)); queue->next=NULL; return queue; } QNode* enQueue(QNode * rear,int data){ QNode * enElem=(QNode*)malloc(sizeof(QNode)); enElem->data=data; enElem->next=NULL; //使用尾插法向链队列中添加数据元素 rear->next=enElem; rear=enElem; return rear; } QNode* DeQueue(QNode * top,QNode * rear){ if (top->next==NULL) { printf(" 队列为空"); return rear; } QNode * p=top->next; printf("%d ",p->data); top->next=p->next; if (rear==p) { rear=top; } free(p); return rear; } int main() { QNode * queue,*top,*rear; queue=top=rear=initQueue();//创建头结点 //向链队列中添加结点,使用尾插法添加的同时,队尾指针需要指向链表的最后一个元素 rear=enQueue(rear, 1); rear=enQueue(rear, 2); rear=enQueue(rear, 3); rear=enQueue(rear, 4); //入队完成,所有数据元素开始出队列 rear=DeQueue(top, rear); rear=DeQueue(top, rear); rear=DeQueue(top, rear); rear=DeQueue(top, rear); rear=DeQueue(top, rear); return 0; }
程序运行结果为:
1 2 3 4
队列为空
以上是关于数据结构学习总结 栈和队列的主要内容,如果未能解决你的问题,请参考以下文章