2.1.6 处理器级并行译
Posted xihui
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了2.1.6 处理器级并行译相关的知识,希望对你有一定的参考价值。
人们对更快计算机的需求是不会停止的。天文学家想要模仿大爆炸后第一微秒发生的事情,经济学家想给世界经济建立模型,孩子们想和他们的虚拟朋友在网上玩3D交互多媒体游戏。CPU变得越来越快,最后它们会以光速解决问题,无论英特尔的工程师有多聪明,都离不开20cm/纳秒铜线或者光纤。更快的芯片也要消耗更多的热量,芯片的损耗是个大问题。事实上,过去十年间令CPU时钟速度提升陷入停滞的主要原因就是难以摆脱的热量问题。
指令集并行有一点效果,流水线和超标量运算胜过前者5或10倍。为了获取50,100,或更多的利润,唯一的方法就是设计多CPU计算机,现在我们关心它们是怎样组织起来的。
数据并行计算机
计算领域存在的大量问题,比如物理科学,工程学,和计算机图形学,涉及到循环和数组,或者在其他方面有着严格的结构。通常相同的计算过程会反复出现,即使作用在不同的数据集上。这些程序的规则性和构造有利于提升并行执行的速度。有两种主要的方法来快速有效地执行这些高度规则化的程序:SIMD处理器和向量处理器。虽然这两种模式在大多数方面极度相似,讽刺的是,第一种通常被视作并行计算机而第二种被视作单处理器的拓展。
数据并行计算机上已经产生许多由于性能卓越而成功的应用程序。它们只用备选方案里最少的晶体管,确能产生强大的算力。Gordon Moore(就是摩尔定律那个摩尔)注意到了硅的成本是十亿美元每亩(4047平方米)。因此,每亩硅能挤出越多的算力,计算机公司通过卖硅挣的钱就越多。数据并行处理器是压榨硅性能的最好手段之一。因为所有的处理器运行着相同的指令,系统只需要一个“大脑”来控制计算机。因此,处理器只需要一个读取阶段,一个解码阶段,和一些控制逻辑。数据并行计算机相比于其他处理器的巨大优势就是省硅,只要它们运行的软件能规律化地处理大量并行。
一个单指令流多数据流或者SIMD处理器由大量完全相同的处理器组成,针对不同的数据集执行相同的指令序列。世界上最早的SIMD处理器是Illinois大学的埃尼阿克4号(Bouknight,1972)。埃尼阿克4号最早设计成由4个象限组成,每个象限有一个以处理器/内存作为单元的8乘8正方形网格。每个象限有一个简单的控制单元,给所有的处理器广播一条简单指令,该指令被所有处理器步伐一致地执行,每个处理器使用其所持内存中的数据。由于资金有限,仅仅构建了一个50-每秒百万浮点运算的象限。假如完整的1-每秒10亿次浮点运算机器构建完成,它能单枪匹马,把整个世界的算力提升一倍。
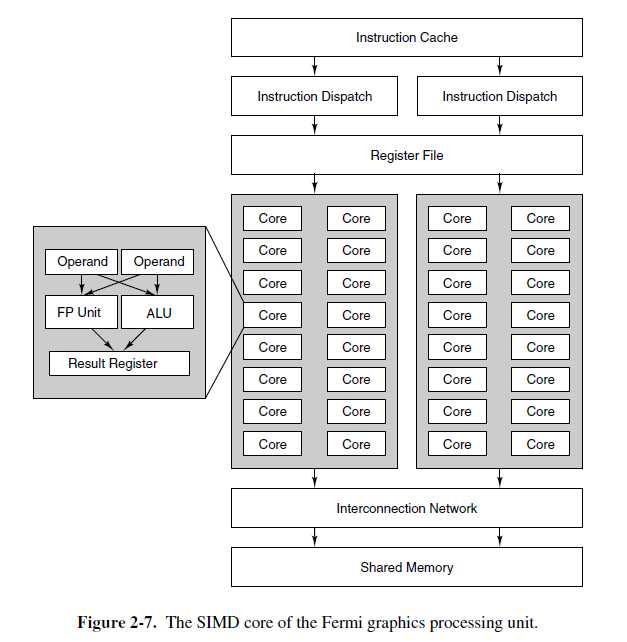
现代图像处理单元(GPUS)严重依赖SIMD,用少量晶体管获得巨大的算力。图像处理把它自身导向SIMD处理器,因为大部分算法是高度规则化的,对像素,顶点,纹理和边重复地操作。图2-7展示了英伟达Fermi GPU核心中的SIMD处理器。一个Fermi GPU包括16个SIMD流多处理器(SM),每个SM包含32个SIMD处理器。每个时钟周期,调度器选择SIMD上的两个线程来执行。每个线程的下一个指令到16个SIMD处理器上执行,如果没有足够多的并行数据可能会少一点。如果每个线程能在每个周期执行16个操作,一个完整挂载的,具有32个SM的Fermi GPU核心能在一个周期执行512次操作。这是一个令人印象深刻的壮举,考虑下,一个相似尺寸的,通用目的的四核CPU拼命工作,也只能达到前者的1/32。
向量处理器对程序员来说和SIMD处理器十分相似。像SIMD处理器,向量处理器执行那些有成对数据元素的操作序列时非常有效率。但是不像SIMD处理器,所有的操作都在在一个简单的,笨重的流水线功能单元里执行。Seymour Cray公司发现,Cray Research生产了许多向量处理器,最早追溯到1974年的Cray-1并且在现代的模型中还在继续。
SIMD处理器和向量处理器都致力于数据数组。都执行单指令,比如把元素成对地添加到两个向量中。SIMD处理器把地址作为向量中的元素,向量处理器另有向量寄存器的概念,向量寄存器由一组平常的寄存器组成,可以在一条简单指令中从内存读取,该指令实际上从内存中连续地读取它们。向量和指令通过把两个向量寄存器中的元素提供给流水线累加器,一对对的做加法。累加器的结果也是一个向量,可以存储在向量寄存器中,或者直接作为其他向量操作的操作数。SSE(流式SIMD拓展)指令在英特尔Core体系中用这种可执行模型来加速那些高度规则化的计算,比如多媒体和科学软件。从某种意义上说,英特尔Core体系的诸多祖先之一包括ILLIAC 4。
多处理器
在数据并行处理器中处理元素的CPU并不是独立的,虽然它们之间仅仅共享控制单元。我们第一个有着多个完备CPU的并行系统就是多处理器,有着多个CPU且共享内存的系统,像房间里的一群人共享一块黑板。既然每个CPU都能读写任意内存,它们必须协调工作,避免互相妨碍。与多处理器的情况一样,若两个或更多的CPU有能力交互,我们称之为紧耦合的。
各种各样的实现方案都是可能的。最简单的一种就是一根总线连接多个CPU,一个内存多个接入。图2-8(a)就是这样一个基于总线的多处理器的示意图。
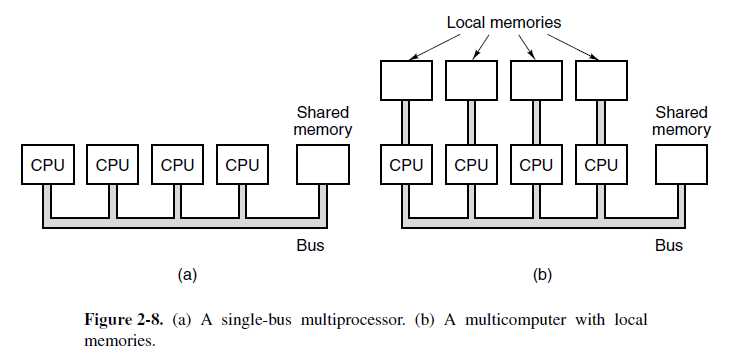
无需太多设想就能认识到,大量快速处理器不断尝试通过一条相同的主线连接内存,冲突无可避免。 多处理器设计者已经提出许多方案来减少竞争,提高性能。有一种设计,如图2-8(b)所示,赋予每个处理器一些私有的本地存储。这种内存用于保存程序代码和那些不需要共享的数据项。访问这种私有内存用不到总线,极大地减少了总线的通信量。其他方案(比如缓存--如下所示)也是可能的。
多处理器比起其他类型的并行计算机,优势在于简单共享内存的的编程模型容易实现。比如,设想一个程序,在一套图片中通过显微镜寻找癌细胞。数字化图片可以保存在通用内存中,每个处理器分配图片的某些搜索区域。由于每个处理器都连接到整个内存,最好仔细检查那些从分配区横跨到相邻区域的单元。
多计算机
虽然有着适度数量(<=256)处理器的多处理器真的很好构建,但是大些的十分难以构建。难点在于这么多处理器都要连接到内存。为了绕开这些问题,许多设计者简单地抛弃了共享内存的想法,而仅仅是构建由大量互相连接的计算机组成的系统,每个计算机有其私有内存,但是没有公用内存。这些系统被称作多计算机。多计算机中的CPU被称作松耦合的,与紧耦合的多处理器CPU形成鲜明对比。
多计算机系统中CPU之间的通讯是通过互相发送信息,很像email,但是更快。对于大型系统来说,每台计算机都和其他计算机连接是不切实际的,所以像2D和3D网格,树和环这样的拓扑被使用。因此,从一台电脑传送到另一台电脑的信息必须经过一或多个中间计算机或者路由器。尽管如此,以微秒级传输消息并不十分困难。多计算机有超过250000个CPU,比如IBM曾经搭建的蓝色基因计划/P。
由于多处理器更容易编程,多计算机更容易构建,有很多混合系统设计的研究,希望结合两者的优点。这种计算机试着提出了一种错误观念,共享内存不需要考虑它构建时的开销。我们将在第8章进入多处理器和多计算机的细节。
以上是关于2.1.6 处理器级并行译的主要内容,如果未能解决你的问题,请参考以下文章