使用request+bs4爬取所有股票信息
Posted yanjiayi098-001
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了使用request+bs4爬取所有股票信息相关的知识,希望对你有一定的参考价值。
爬取前戏
我们要知道利用selenium是非常无敌的,自我认为什么反爬不反爬都不在话下,但是今天我们为什么要用request+bs4爬取所有股票信息呢?因为他比较原始,因此今天的数据,爬取起来也是比较繁琐的!接下来让我们emmmm。。。。你懂得
爬取步骤
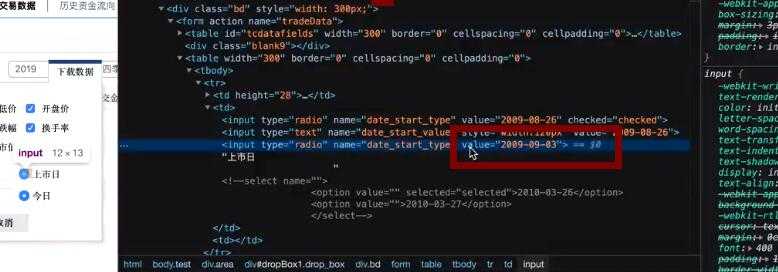
第一步:获取股票代码
1)我们通过这个链接去网易看一下具体的股票信息,下面这个网页是乐视网的股票信息http://quotes.money.163.com/trade/lsjysj_300104.html#01b07
2)上海证券交易所的官方网站上直接告诉你了所有股票的代码,请点击市场数据---股票列表---下载---整理为csv文件(这样你就拿到了3000多个股票代码)
第二步:处理一些乱糟糟的数据,这些数据要在网页上面找。将数据下载下来,存储为csv文件。
[注意]:为什么要异常处理?
? 因为有些股票代码里面没有数据,也可能是空的,总之在下载的时候,由于股票代码,就会出现一系列的问题,所以对他异常处理
'''处理不规整数据'''
# http://quotes.money.163.com/trade/lsjysj_300104.html#01b07 #30010就是一个公司的股票代码
import pandas as pd
import requests
from bs4 import BeautifulSoup
log = open("error.log", mode="w", encoding="utf-8") #这是一个错误日志,打开它,把错误的记录填进去
df = pd.read_csv("code.csv")
for code in df['code']: #遍历code
try:
# 000539
# 000001 1
code = format(code, "06") # 进行格式化处理. 处理成6位的字符串 000001
url = f"http://quotes.money.163.com/trade/lsjysj_{code}.html#01b07"
# 发送请求
resp = requests.get(url) # 发送请求. 获取到数据
main_page = BeautifulSoup(resp.text, "html.parser") # 解析这个网页, 告诉它这个网页是html
main_page.find() # 找一个
main_page.find_all() # 找一堆
trs = main_page.find("form", attrs={"name": "tradeData"}).find_all("table")[1].find_all("tr") # <form name="tradeData"> #打开网页,找到网页的一个唯一属性
#这些就是网页的信息,我们对他进行处理就好
start = trs[0].find_all("input")[2].get("value").replace("-", "") #开始上市时间
end = trs[1].find_all("input")[2].get("value").replace("-", "") #今日
href = main_page.find("ul", attrs={"class": 'main_menu'}).find_all("li")[0].find("a").get('href')
# print(href) # /0600000.html#01a01
code_num = href.split(".")[0].strip("/") #对上面的字符串进行切片处理
download_url = f"http://quotes.money.163.com/service/chddata.html?code={code_num}&start={start}&end={end}&fields=TCLOSE;HIGH;LOW;TOPEN;LCLOSE;CHG;PCHG;TURNOVER;VOTURNOVER;VATURNOVER;TCAP;MCAP"
#获取到整个完整的访问股票代码的网址。
resp = requests.get(download_url)
resp.encoding = "GBK" #编码问题
file_name = main_page.find("h1", attrs={"class":"title_01"}).text.replace(" ", "")
with open(f"股票交易记录/{file_name}.csv", mode="w", encoding="UTF-8") as f:
f.write(resp.text)
print("下载了一个")
except Exception as e:
log.write(f"下载{code}股票的时候. 出现了错误. url是:{url} download:{download_url}
")
上面这样,我们的每个股票的详细信息就会下载到文件中。
第三步:将数据进行可视化操作,将收盘价,开盘价等数据,用一定的图片显示出来。
import pandas as pd
import matplotlib.pyplot as plt
import mpl_finance as mpl
from matplotlib.pylab import date2num
def main():
main_df = pd.read_csv('目录.csv', dtype=object) # 如果不写后面的dtype, 你读取的code就是数值 int, 此时默认是字符串
while 1:
code = input("请输入一个你想看到的股票代码(6位):") # 00001
if len(code) != 6:
print("代码不对. 请重新输入!")
else:
data_df = main_df[main_df['code']==code]
# 600006,东风汽车(600006)历史交易数据.csv
if data_df.empty:
print("没有这支股票")
else:
print("有这支股票")
file_name = data_df.iloc[0]['file']
show(file_name, code)
def show(file_name, code): # 显示这个股票的历史记录
data_df = pd.read_csv(f"股票所有记录/{file_name}", parse_dates=["日期"]).iloc[:100, :]
data_df = data_df[data_df['开盘价' != 0.0]]
k_data = data_df[["日期", "开盘价", "最高价", "最低价", "收盘价"]]
k_data['日期'] = date2num(k_data['日期'])
# time, open, high, low, close
# [(time, open, high, low, close), (time, open, high, low, close), (time, open, high, low, close), ()]
# gen = [tuple(value) for value in k_data.values] # 1
gen = (tuple(value) for value in k_data.values) # 2
fig, [ax1, ax2] = plt.subplots(2, 1, sharex=True)
ax2.bar(date2num(data_df['日期']), data_df['成交金额'])
ax1.xaxis_date() #x轴
ax2.xaxis_date()
mpl.candlestick_ohlc(ax1, gen)
plt.savefig("abc.jpg", dpi=1000)
plt.show()
if __name__ == '__main__':
main()
有没有发现这张图好丑,好吧!没关系的,基本实现了哈哈。
以上是关于使用request+bs4爬取所有股票信息的主要内容,如果未能解决你的问题,请参考以下文章
python实例:从excel读取股票代码,爬取股票信息写到代码后面的单元格中