process on 自动注册实操
Posted imine-lightq-jane
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了process on 自动注册实操 相关的知识,希望对你有一定的参考价值。
本文涉及到的技术知识有:
- selenium 自动化定位;
- html dom element 抓取;
- 基于 opencv 的缺口滑块定位;
- 正则表达式;
偶然地阅读到一篇关于:利用爬虫增加 processon 免费文件数,刚好 process on 文件数要满了,所以想实操一把。
经分析,获知 process on 可以通过分享自己专属链接给别人,别人通过这个链接注册账号后,可以获得系统扩容3个文件。
通过撸代码整理出了通过 selenium 自动注册的逻辑。直接上图:
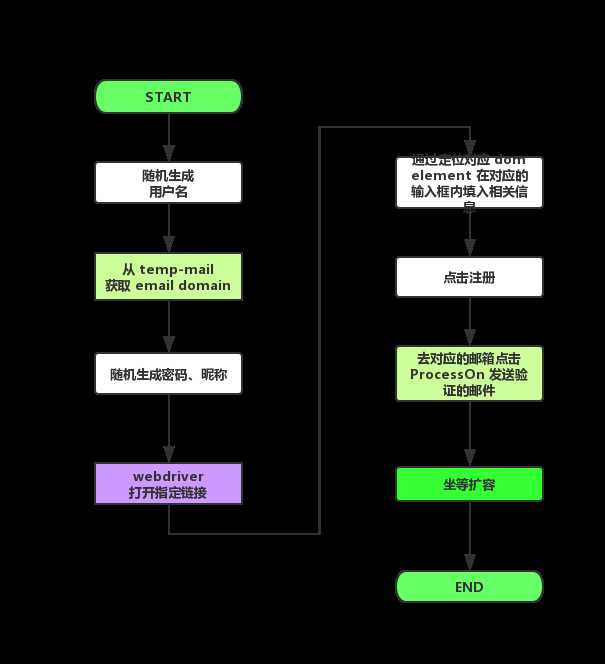
从上面可以了解到当时 ProcessOn 的登录注册过程还是比较简单的,dom元素也不复杂,全部为输入框。验证也是通过邮箱验证链接。
当时看到这篇文章的时候,ProcessOn 的注册已经发生了变更,验证方式改成了腾讯验证滑块。验证滑块通过后会发送邮件到注册邮箱。邮件的内容是验证码。
selenium,soup,dom,temp-mail 都是新技能。其实 python 也撸得少。搭建了个环境大概的运行了一下,在 selenium 定位 dom element 的时候频频报错。
万能的度娘(我可能不是一只合格的猿,我还是习惯度娘,没有趁手的梯子,速度忍不了),修改代码如下:
def open(self): """ open browser, and input register code """ self.browser.get(self.url) time.sleep(5) # press ‘register‘ button self.browser.find_element_by_class_name(‘button‘).click() # fill ‘email/phone‘ as user_name self.browser.find_element_by_id(‘login_phone‘).send_keys(self.email) # fill ‘password‘ self.browser.find_element_by_id(‘login_password‘).send_keys(self.psw) # fill ‘fullname/nickname‘ self.browser.find_element_by_id(‘login_fullname‘).send_keys(self.name) # trigger ‘TencentCaptcha‘ button to send verify email self.browser.find_element_by_id(‘TencentCaptcha‘).click()
还算见得多,知道那个是腾讯验证滑块,有了关键字,度娘之。找到一篇:腾讯防水墙验证码破解。拉下来复现之,可能比较新。复现通过了。
看了下源码,主要的技术点是通过 opencv 获取缺口的位置,当然还有模拟人体操作。
可以将 Login 类整体接入到 ProcessOn,修改的地方比较少:
class Login(object): def __init__(self, browser): # 跟 ProcessOn 在同一个浏览器上 # self.url = "https://open.captcha.qq.com/online.html" self.driver = browser def login_main(self): # 去掉触发滑块的动作,滑块触发由 ProcessOn 操作 # ssl._create_default_https_context = ssl._create_unverified_context driver = self.driver # wait for the dom load otherwise can not find the element # 此处一定要睡一会等待 dom 加载完成 time.sleep(5) driver.switch_to.frame(driver.find_element_by_id(‘tcaptcha_iframe‘)) # switch 到 滑块frame time.sleep(0.5) bk_block = driver.find_element_by_xpath(‘//img[@id="slideBg"]‘) # 大图 web_image_width = bk_block.size web_image_width = web_image_width[‘width‘] bk_block_x = bk_block.location[‘x‘] ... # 此处省略若干 ... # 不要将浏览器关闭 # self.after_quit()
接下来是要到 temp-mail 中获取邮件并拿到验证码了。
在这之前有个小插曲,当时(几个月前?)从 temp-mail 里获取 domain 列表是正常的。
def getdomain(): global domains if domains == []: r = requests.get("https://temp-mail.org/en/option/change/") soup = BeautifulSoup(r.text, "html.parser") domains = [tag.text for tag in soup.find(id="domain").find_all("option")] return random.choice(domains)
今天运行的时候,发现拿到的 domains 为空。经过浏览器 F12 查看 element 变化情况后发现,temp-mail 进行了一定的反爬策略(也不知道是不是我的网速慢^_^)。<option> 是通过脚本动态加载的。当下拿到的html还未加载。
def getdomain(): global domains if domains == []: url = "https://temp-mail.org/en/option/change/" browser = webdriver.Chrome() browser.get(url) domainsText = browser.find_element_by_id(‘domain‘).get_attribute(‘innerHTML‘) patt = re.compile(r‘<option.+?>(.+?)</option>‘) domains = patt.findall(domainsText) browser.quit() return random.choice(domains)
当时想到的方案是等待dom加载完成之后,再通过soup进行解析抓取邮件domain列表。研究了一阵未果,遂直接使用 selenium 神器。
加载完成比较慢,但是也是一锤子买卖。
拿到email domain 之后,我们就可以随机构造邮箱地址、用户名和密码了,即准备好了账号信息。
接下来的事情就是触发验证码发送,并且去对应的邮箱在抓取验证码。
因为之前体验过一次 temp-mail,邮箱随便设置,邮件随意收,以为小作品可以闭环了,不曾想大家技术升级太快,temp-mail 又在使妖。
欲知后事如何,且听下文分解。
PS:不曾想 process on 又作妖了。
社会逼着我们成长!
以上是关于process on 自动注册实操 的主要内容,如果未能解决你的问题,请参考以下文章