记录面试遇到的几个自己不太熟悉的问题
Posted heqiyoujing
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了记录面试遇到的几个自己不太熟悉的问题相关的知识,希望对你有一定的参考价值。
一、https原理
二、Http1.0和1.1及2.0的区别
三、限流算法
四、Java内存模型
1.https原理
我们知道,HTTP请求都是明文传输的,所谓的明文指的是没有经过加密的信息,如果HTTP请求被黑客拦截,并且里面含有银行卡密码等敏感数据的话,会非常危险。为了解决这个问题,Netscape 公司制定了HTTPS协议,HTTPS可以将数据加密传输,也就是传输的是密文,即便黑客在传输过程中拦截到数据也无法破译,这就保证了网络通信的安全。
密码学基础
在正式讲解HTTPS协议之前,我们首先要知道一些密码学的知识。
- 明文: 明文指的是未被加密过的原始数据。
- 密文:明文被某种加密算法加密之后,会变成密文,从而确保原始数据的安全。密文也可以被解密,得到原始的明文。
- 密钥:密钥是一种参数,它是在明文转换为密文或将密文转换为明文的算法中输入的参数。密钥分为对称密钥与非对称密钥,分别应用在对称加密和非对称加密上。
对称加密
对称加密:对称加密又叫做私钥加密,即信息的发送方和接收方使用同一个密钥去加密和解密数据。对称加密的特点是算法公开、加密和解密速度快,适合于对大数据量进行加密,常见的对称加密算法有DES、3DES、TDEA、Blowfish、RC5和IDEA。
其加密过程如下:明文 + 加密算法 + 私钥 => 密文
解密过程如下:密文 + 解密算法 + 私钥 => 明文
对称加密中用到的密钥叫做私钥,私钥表示个人私有的密钥,即该密钥不能被泄露。
其加密过程中的私钥与解密过程中用到的私钥是同一个密钥,这也是称加密之所以称之为“对称”的原因。由于对称加密的算法是公开的,所以一旦私钥被泄露,那么密文就很容易被破解,所以对称加密的缺点是密钥安全管理困难。
非对称加密
非对称加密:非对称加密也叫做公钥加密。非对称加密与对称加密相比,其安全性更好。对称加密的通信双方使用相同的密钥,如果一方的密钥遭泄露,那么整个通信就会被破解。而非对称加密使用一对密钥,即公钥和私钥,且二者成对出现。私钥被自己保存,不能对外泄露。公钥指的是公共的密钥,任何人都可以获得该密钥。用公钥或私钥中的任何一个进行加密,用另一个进行解密。
被公钥加密过的密文只能被私钥解密,过程如下:
明文 + 加密算法 + 公钥 => 密文, 密文 + 解密算法 + 私钥 => 明文
被私钥加密过的密文只能被公钥解密,过程如下:
明文 + 加密算法 + 私钥 => 密文, 密文 + 解密算法 + 公钥 => 明文
由于加密和解密使用了两个不同的密钥,这就是非对称加密“非对称”的原因。
非对称加密的缺点是加密和解密花费时间长、速度慢,只适合对少量数据进行加密。
在非对称加密中使用的主要算法有:RSA、Elgamal、Rabin、D-H、ECC(椭圆曲线加密算法)等。
HTTPS通信过程
HTTPS协议 = HTTP协议 + SSL/TLS协议,在HTTPS数据传输的过程中,需要用SSL/TLS对数据进行加密和解密,需要用HTTP对加密后的数据进行传输,由此可以看出HTTPS是由HTTP和SSL/TLS一起合作完成的。
SSL的全称是Secure Sockets Layer,即安全套接层协议,是为网络通信提供安全及数据完整性的一种安全协议。SSL协议在1994年被Netscape发明,后来各个浏览器均支持SSL,其最新的版本是3.0
TLS的全称是Transport Layer Security,即安全传输层协议,最新版本的TLS(Transport Layer Security,传输层安全协议)是IETF(Internet Engineering Task Force,Internet工程任务组)制定的一种新的协议,它建立在SSL 3.0协议规范之上,是SSL 3.0的后续版本。在TLS与SSL3.0之间存在着显著的差别,主要是它们所支持的加密算法不同,所以TLS与SSL3.0不能互操作。虽然TLS与SSL3.0在加密算法上不同,但是在我们理解HTTPS的过程中,我们可以把SSL和TLS看做是同一个协议。
HTTPS为了兼顾安全与效率,同时使用了对称加密和非对称加密。数据是被对称加密传输的,对称加密过程需要客户端的一个密钥,为了确保能把该密钥安全传输到服务器端,采用非对称加密对该密钥进行加密传输,总的来说,对数据进行对称加密,对称加密所要使用的密钥通过非对称加密传输。
HTTPS在传输的过程中会涉及到三个密钥:
服务器端的公钥和私钥,用来进行非对称加密
客户端生成的随机密钥,用来进行对称加密
一个HTTPS请求实际上包含了两次HTTP传输,可以细分为8步。
- 1.客户端向服务器发起HTTPS请求,连接到服务器的443端口
- 2.服务器端有一个密钥对,即公钥和私钥,是用来进行非对称加密使用的,服务器端保存着私钥,不能将其泄露,公钥可以发送给任何人。
- 3.服务器将自己的公钥发送给客户端。
- 4.客户端收到服务器端的公钥之后,会对公钥进行检查,验证其合法性,如果发现发现公钥有问题,那么HTTPS传输就无法继续。严格的说,这里应该是验证服务器发送的数字证书的合法性,关于客户端如何验证数字证书的合法性,下文会进行说明。如果公钥合格,那么客户端会生成一个随机值,这个随机值就是用于进行对称加密的密钥,我们将该密钥称之为client key,即客户端密钥,这样在概念上和服务器端的密钥容易进行区分。然后用服务器的公钥对客户端密钥进行非对称加密,这样客户端密钥就变成密文了,至此,HTTPS中的第一次HTTP请求结束。
- 5.客户端会发起HTTPS中的第二个HTTP请求,将加密之后的客户端密钥发送给服务器。
- 6.服务器接收到客户端发来的密文之后,会用自己的私钥对其进行非对称解密,解密之后的明文就是客户端密钥,然后用客户端密钥对数据进行对称加密,这样数据就变成了密文。
- 7.然后服务器将加密后的密文发送给客户端。
- 8.客户端收到服务器发送来的密文,用客户端密钥对其进行对称解密,得到服务器发送的数据。这样HTTPS中的第二个HTTP请求结束,整个HTTPS传输完成。
2.Http1.0和1.1及2.0的区别
http1.0:
最早在1996年在网页中使用,内容简单,所以浏览器的每次请求都需要与服务器建立一个TCP连接,服务器处理完成后立即断开TCP连接(无连接),服务器不跟踪每个客户端也不记录过去的请求(无状态)。
HTTP1.1:
到1999年广泛在各大浏览器网络请求中使用,HTTP/1.0中默认使用Connection: close。在HTTP/1.1中已经默认使用Connection: keep-alive(长连接),避免了连接建立和释放的开销,但服务器必须按照客户端请求的先后顺序依次回送相应的结果,以保证客户端能够区分出每次请求的响应内容。通过Content-Length字段来判断当前请求的数据是否已经全部接收。不允许同时存在两个并行的响应。
HTTP2.0:
HTTP/2引入二进制数据帧和流的概念,其中帧对数据进行顺序标识,(流(stream):已建立连接上的双向字节流;消息:与逻辑消息对应的完整的一系列数据帧;帧:HTTP2.0通信的最小单位,每个帧包含帧头部,至少也会标识出当前帧所属的流(stream id))这样浏览器收到数据之后,就可以按照序列对数据进行合并,而不会出现合并后数据错乱的情况。同样是因为有了序列,服务器就可以并行的传输数据,这就是流所做的事情。这些数据帧都在一个tcp连接(可以承载任意数量的双向数据流)上并行发送。
http1.0和http1.1的主要区别如下:
- 1、缓存处理:1.1添加更多的缓存控制策略(如:Entity tag,If-Match)
- 2、网络连接的优化:1.1支持断点续传
- 3、错误状态码的增多:1.1新增了24个错误状态响应码,丰富的错误码更加明确各个状态
- 4、Host头处理:支持Host头域,不在以IP为请求方标志
- 5、长连接:减少了建立和关闭连接的消耗和延迟。
http1.1和http2.0的主要区别:
- 1、新的传输格式:2.0使用二进制格式,1.0依然使用基于文本格式
- 2、多路复用:连接共享,不同的request可以使用同一个连接传输(最后根据每个request上的id号组合成正常的请求)
- 3、header压缩:由于1.X中header带有大量的信息,并且得重复传输,2.0使用encoder来减少需要传输的hearder大小
- 4、服务端推送:同google的SPDUY(1.0的一种升级)一样
3.限流算法
限流是限制系统的输入和输出流量,以达到保护系统的目的,而限流的实现主要是依靠限流算法。
1. 固定时间窗口算法
又称计数器算法。固定时间窗口算法就是统计记录单位时间内进入系统或者某一接口的请求次数,在限定的次数内的请求则正常接收处理,超过次数的请求则拒绝掉或者改为异步处理等限流措施。
class CounterDemo { public long timeStamp = getNowTime(); public int reqCount = 0; public final int limit = 100; // 时间窗口内最大请求数 public final long interval = 1000; // 时间窗口ms public boolean grant() { long now = getNowTime(); if (now < timeStamp + interval) { // 在时间窗口内 reqCount++; // 判断当前时间窗口内是否超过最大请求控制数 return reqCount <= limit; } else { timeStamp = now; // 超时后重置 reqCount = 1; return true; } } }
2. 漏桶算法(leaky bucket)
漏桶算法其实很简单,可以粗略的认为就是注水漏水过程,往桶中以一定速率流出水,以任意速率流入水,当水超过桶流量则丢弃,因为桶容量是不变的,保证了整体的速率。这个从桶底流出去的水就是系统正常处理的请求,从旁边流出去的水就是系统拒绝掉的请求。
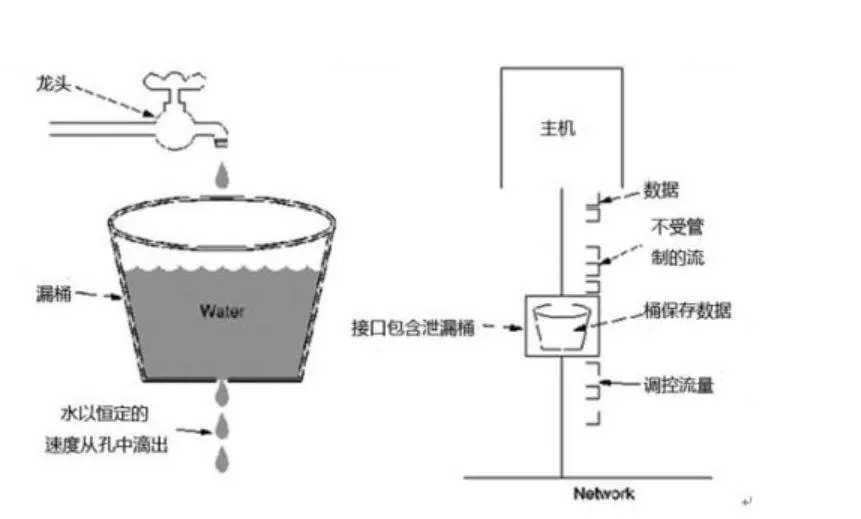
class LeakyDemo { public long timeStamp = getNowTime(); public int capacity; // 桶的容量 public int rate; // 水漏出的速度 public int water; // 当前水量(当前累积请求数) public boolean grant() { long now = getNowTime(); water = max(0, water - (now - timeStamp) * rate); // 先执行漏水,计算剩余水量 timeStamp = now; if ((water + 1) < capacity) { // 尝试加水,并且水还未满 water += 1; return true; } else { // 水满,拒绝加水 return false; } } }
因为流出的速度是一定的,可以抵御突发流量,做到更加平滑的限流,而且不允许流量突发。
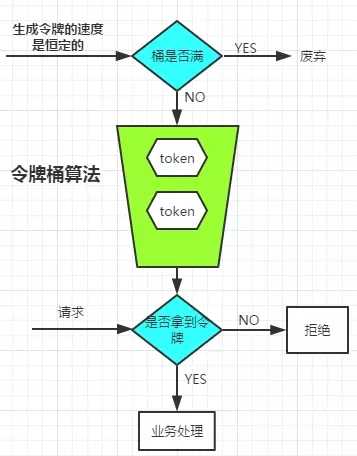
3. 令牌桶算法(Token Bucket)
令牌桶算法是比较常见的限流算法之一,Google开源项目Guava中的RateLimiter使用的就是令牌桶算法。流程如下:
- 所有的请求在处理之前都需要拿到一个可用的令牌才会被处理。
- 根据限流大小,设置按照一定的速率往桶里添加令牌。
- 桶设置最大的放置令牌限制,当桶满时、新添加的令牌就被丢弃或者拒绝。
- 请求到达后首先要获取令牌桶中的令牌,拿着令牌才可以进行其他的业务逻辑,处理完业务逻辑之后,将令牌直接删除。
单机伪代码如下,分布式环境可以使用Redisson。
class TokenBucketDemo { public long timeStamp = getNowTime(); public int capacity; // 桶的容量 public int rate; // 令牌放入速度 public int tokens; // 当前令牌数量 public boolean grant() { long now = getNowTime(); // 先添加令牌 tokens = min(capacity, tokens + (now - timeStamp) * rate); timeStamp = now; if (tokens < 1) { // 若桶中没有令牌,则拒绝 return false; } else { // 还有令牌,领取令牌 tokens -= 1; return true; } } }
算法特点
- 可以抵御突发流量,因为桶内的令牌数不会超过给定的最大值
- 可以做到更加平滑的限流,因为令牌是匀速放入的。
- 令牌桶算法允许流量一定程度的突发。(相比漏桶算法)
在时间点刷新的临界点上,只要剩余token足够,令牌桶算法会允许对应数量的请求通过,而后刷新时间因为token不足,流量也会被限制在外,这样就比较好的控制了瞬时流量。因此,令牌桶算法也被广泛使用。
4.Java内存模型
转自:Https原理及流程
以上是关于记录面试遇到的几个自己不太熟悉的问题的主要内容,如果未能解决你的问题,请参考以下文章