系统软件工程师面试2. 网络部分
Posted ym65536
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了系统软件工程师面试2. 网络部分相关的知识,希望对你有一定的参考价值。
网络部分
1、tcp/udp区别
2、tcp 三次握手/ connect/ accept 关系, read返回0
3、select/ epoll
ET/LT
在一个非阻塞的socket上调用read/write函数, 返回EAGAIN或者EWOULDBLOCK(注: EAGAIN就是EWOULDBLOCK)
从字面上看, 意思是:EAGAIN: 再试一次,EWOULDBLOCK: 如果这是一个阻塞socket, 操作将被block,perror输出: Resource temporarily unavailable
总结:
这个错误表示资源暂时不够,能read时,读缓冲区没有数据,或者write时,写缓冲区满了。遇到这种情况,如果是阻塞socket,read/write就要阻塞掉。而如果是非阻塞socket,read/write立即返回-1, 同时errno设置为EAGAIN。
所以,对于阻塞socket,read/write返回-1代表网络出错了。但对于非阻塞socket,read/write返回-1不一定网络真的出错了。可能是Resource temporarily unavailable。这时你应该再试,直到Resource available。
综上,对于non-blocking的socket,正确的读写操作为:
读:忽略掉errno = EAGAIN的错误,下次继续读
写:忽略掉errno = EAGAIN的错误,下次继续写
对于select和epoll的LT模式,这种读写方式是没有问题的。但对于epoll的ET模式,这种方式还有漏洞。
epoll的两种模式LT和ET
二者的差异在于level-trigger模式下只要某个socket处于readable/writable状态,无论什么时候进行epoll_wait都会返回该socket;而edge-trigger模式下只有某个socket从unreadable变为readable或从unwritable变为writable时,epoll_wait才会返回该socket。
所以,在epoll的ET模式下,正确的读写方式为:
读:只要可读,就一直读,直到返回0,或者 errno = EAGAIN
写:只要可写,就一直写,直到数据发送完,或者 errno = EAGAIN
正确的读
| n = 0; |
| while ((nread = read(fd, buf + n, BUFSIZ-1)) > 0) { |
| n += nread; |
| } |
| if (nread == -1 && errno != EAGAIN) { |
| perror("read error"); |
| } |
正确的写
| int nwrite, data_size = strlen(buf); |
| n = data_size; |
| while (n > 0) { |
| nwrite = write(fd, buf + data_size - n, n); |
| if (nwrite < n) { |
| if (nwrite == -1 && errno != EAGAIN) { |
| perror("write error"); |
| } |
| break; |
| } |
| n -= nwrite; |
| } |
正确的accept,accept 要考虑 2 个问题
(1) 阻塞模式 accept 存在的问题
考虑这种情况:TCP连接被客户端夭折,即在服务器调用accept之前,客户端主动发送RST终止连接,导致刚刚建立的连接从就绪队列中移出,如果套接口被设置成阻塞模式,服务器就会一直阻塞在accept调用上,直到其他某个客户建立一个新的连接为止。但是在此期间,服务器单纯地阻塞在accept调用上,就绪队列中的其他描述符都得不到处理。
解决办法是把监听套接口设置为非阻塞,当客户在服务器调用accept之前中止某个连接时,accept调用可以立即返回-1,这时源自Berkeley的实现会在内核中处理该事件,并不会将该事件通知给epool,而其他实现把errno设置为ECONNABORTED或者EPROTO错误,我们应该忽略这两个错误。
(2)ET模式下accept存在的问题
考虑这种情况:多个连接同时到达,服务器的TCP就绪队列瞬间积累多个就绪连接,由于是边缘触发模式,epoll只会通知一次,accept只处理一个连接,导致TCP就绪队列中剩下的连接都得不到处理。
解决办法是用while循环抱住accept调用,处理完TCP就绪队列中的所有连接后再退出循环。如何知道是否处理完就绪队列中的所有连接呢?accept返回-1并且errno设置为EAGAIN就表示所有连接都处理完。
综合以上两种情况,服务器应该使用非阻塞地accept,accept在ET模式下的正确使用方式为:
| while ((conn_sock = accept(listenfd,(struct sockaddr *) &remote, (size_t *)&addrlen)) > 0) { |
| handle_client(conn_sock); |
| } |
| if (conn_sock == -1) { |
| if (errno != EAGAIN && errno != ECONNABORTED && errno != EPROTO && errno != EINTR) |
| perror("accept"); |
| } |
一道腾讯后台开发的面试题
使用Linuxepoll模型,水平触发模式;当socket可写时,会不停的触发socket可写的事件,如何处理?
第一种最普遍的方式:
需要向socket写数据的时候才把socket加入epoll,等待可写事件。
接受到可写事件后,调用write或者send发送数据。
当所有数据都写完后,把socket移出epoll。
这种方式的缺点是,即使发送很少的数据,也要把socket加入epoll,写完后在移出epoll,有一定操作代价。
一种改进的方式:
开始不把socket加入epoll,需要向socket写数据的时候,直接调用write或者send发送数据。如果返回EAGAIN,把socket加入epoll,在epoll的驱动下写数据,全部数据发送完毕后,再移出epoll。
这种方式的优点是:数据不多的时候可以避免epoll的事件处理,提高效率。
4、timeout wait过多, 2MSL
- netstat -n | awk ‘/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}‘
它会显示例如下面的信息:
TIME_WAIT 814
CLOSE_WAIT 1
FIN_WAIT1 1
ESTABLISHED 634
SYN_RECV 2
LAST_ACK 1
常用的三个状态是:ESTABLISHED 表示正在通信,TIME_WAIT 表示主动关闭,CLOSE_WAIT 表示被动关闭。
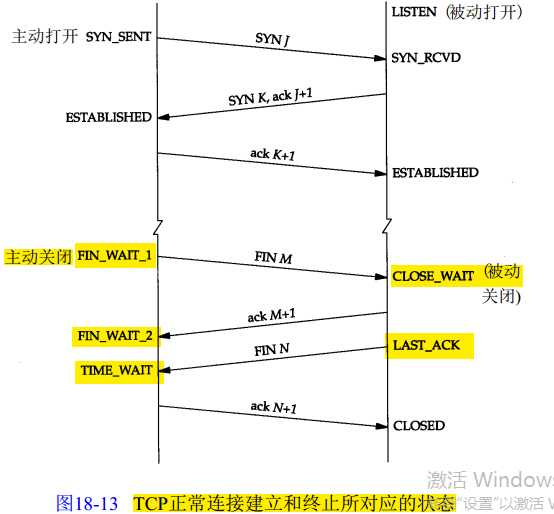
如果服务器出了异常,百分之八九十都是下面两种情况:
1.服务器保持了大量TIME_WAIT状态
2.服务器保持了大量CLOSE_WAIT状态
因为linux分配给一个用户的文件句柄是有限的(可以参考:http://blog.csdn.net/shootyou/article/details/6579139),而TIME_WAIT和CLOSE_WAIT两种状态如果一直被保持,那么意味着对应数目的通道就一直被占着,而且是“占着茅坑不使劲”,一旦达到句柄数上限,新的请求就无法被处理了,接着就是大量Too Many Open Files异常,
1.服务器保持了大量TIME_WAIT状态
这种情况比较常见,一些爬虫服务器或者WEB服务器(如果网管在安装的时候没有做内核参数优化的话)上经常会遇到这个问题,这个问题是怎么产生的呢?
从 上面的示意图可以看得出来,TIME_WAIT是主动关闭连接的一方保持的状态,对于爬虫服务器来说他本身就是“客户端”,在完成一个爬取任务之后,他就 会发起主动关闭连接,从而进入TIME_WAIT的状态,然后在保持这个状态2MSL(max segment lifetime)时间之后,彻底关闭回收资源。为什么要这么做?明明就已经主动关闭连接了为啥还要保持资源一段时间呢?这个是TCP/IP的设计者规定 的,主要出于以下两个方面的考虑:
1.防止上一次连接中的包,迷路后重新出现,影响新连接(经过2MSL,上一次连接中所有的重复包都会消失)
2. 可靠的关闭TCP连接。在主动关闭方发送的最后一个 ack(fin) ,有可能丢失,这时被动方会重新发fin, 如果这时主动方处于 CLOSED 状态 ,就会响应 rst 而不是 ack。所以主动方要处于 TIME_WAIT 状态,而不能是 CLOSED 。另外这么设计TIME_WAIT 会定时的回收资源,并不会占用很大资源的,除非短时间内接受大量请求或者受到攻击。
关于MSL引用下面一段话:
- MSL 為 一個 TCP Segment (某一塊 TCP 網路封包) 從來源送到目的之間可續存的時間 (也就是一個網路封包在網路上傳輸時能存活的時間),由 於 RFC 793 TCP 傳輸協定是在 1981 年定義的,當時的網路速度不像現在的網際網路那樣發達,你可以想像你從瀏覽器輸入網址等到第一 個 byte 出現要等 4 分鐘嗎?在現在的網路環境下幾乎不可能有這種事情發生,因此我們大可將 TIME_WAIT 狀態的續存時間大幅調低,好 讓 連線埠 (Ports) 能更快空出來給其他連線使用。
再引用网络资源的一段话:
- 值 得一说的是,对于基于TCP的HTTP协议,关闭TCP连接的是Server端,这样,Server端会进入TIME_WAIT状态,可 想而知,对于访 问量大的Web Server,会存在大量的TIME_WAIT状态,假如server一秒钟接收1000个请求,那么就会积压 240*1000=240,000个 TIME_WAIT的记录,维护这些状态给Server带来负担。当然现代操作系统都会用快速的查找算法来管理这些 TIME_WAIT,所以对于新的 TCP连接请求,判断是否hit中一个TIME_WAIT不会太费时间,但是有这么多状态要维护总是不好。
- HTTP协议1.1版规定default行为是Keep-Alive,也就是会重用TCP连接传输多个 request/response,一个主要原因就是发现了这个问题。
也就是说HTTP的交互跟上面画的那个图是不一样的,关闭连接的不是客户端,而是服务器,所以web服务器也是会出现大量的TIME_WAIT的情况的。
- #对于一个新建连接,内核要发送多少个 SYN 连接请求才决定放弃,不应该大于255,默认值是5,对应于180秒左右时间
- net.ipv4.tcp_syn_retries=2
- #net.ipv4.tcp_synack_retries=2
- #表示当keepalive起用的时候,TCP发送keepalive消息的频度。缺省是2小时,改为300秒
- net.ipv4.tcp_keepalive_time=1200
- net.ipv4.tcp_orphan_retries=3
- #表示如果套接字由本端要求关闭,这个参数决定了它保持在FIN-WAIT-2状态的时间
- net.ipv4.tcp_fin_timeout=30
- #表示SYN队列的长度,默认为1024,加大队列长度为8192,可以容纳更多等待连接的网络连接数。
- net.ipv4.tcp_max_syn_backlog = 4096
- #表示开启SYN Cookies。当出现SYN等待队列溢出时,启用cookies来处理,可防范少量SYN攻击,默认为0,表示关闭
- net.ipv4.tcp_syncookies = 1
- #表示开启重用。允许将TIME-WAIT sockets重新用于新的TCP连接,默认为0,表示关闭
- net.ipv4.tcp_tw_reuse = 1
- #表示开启TCP连接中TIME-WAIT sockets的快速回收,默认为0,表示关闭
- net.ipv4.tcp_tw_recycle = 1
- ##减少超时前的探测次数
- net.ipv4.tcp_keepalive_probes=5
- ##优化网络设备接收队列
- net.core.netdev_max_backlog=3000
net.ipv4.tcp_fin_timeout
net.ipv4.tcp_keepalive_*
5、RST出现原因
TCP异常终止的常见情形
我们在实际的工作环境中,导致某一方发送reset报文的情形主要有以下几种:
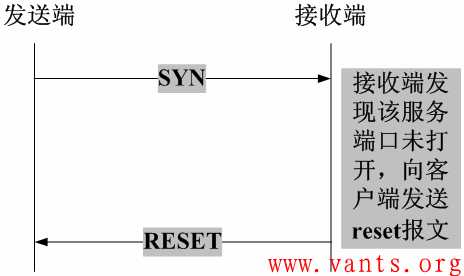
1,客户端尝试与服务器未对外提供服务的端口建立TCP连接,服务器将会直接向客户端发送reset报文。
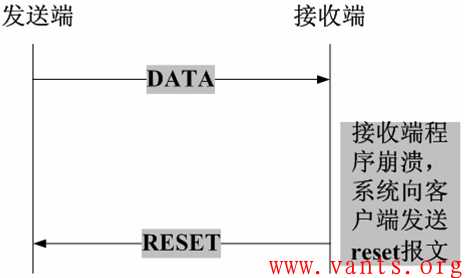
2,客户端和服务器的某一方在交互的过程中发生异常(如程序崩溃等),该方系统将向对端发送TCP reset报文,告之对方释放相关的TCP连接,如下图所示:
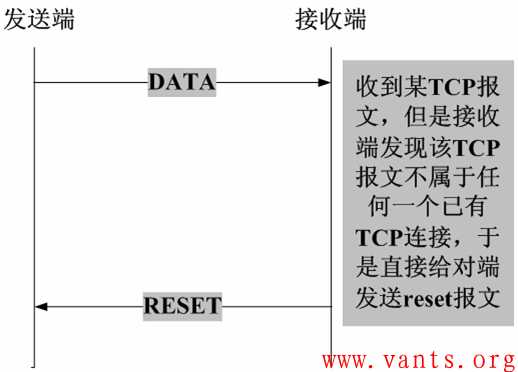
3,接收端收到TCP报文,但是发现该TCP的报文,并不在其已建立的TCP连接列表内(比如server机器直接宕机),则其直接向对端发送reset报文,如下图所示:
TCP_NODelay
链接:https://www.zhihu.com/question/42308970/answer/123620051
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
TCP_NODELAYTCP/IP协议中针对TCP默认开启了Nagle算法。Nagle算法通过减少需要传输的数据包,来优化网络。关于Nagle算法,@郭无心 同学的答案已经说了不少了。在内核实现中,数据包的发送和接受会先做缓存,分别对应于写缓存和读缓存。
If set, disable the Nagle algorithm. This means that segments are always sent as soon as possible, even if there is only a small amount of data. When not set, data is buffered until there is a sufficient amount to send out, thereby avoiding the frequent sending of small packets, which results in poor utilization of the network. This option is overridden by TCP_CORK; however, setting this option forces an explicit flush of pending output, even if TCP_CORK is currently set.
那么针对题主的问题,我们来分析一下。
启动TCP_NODELAY,就意味着禁用了Nagle算法,允许小包的发送。对于延时敏感型,同时数据传输量比较小的应用,开启TCP_NODELAY选项无疑是一个正确的选择。比如,对于SSH会话,用户在远程敲击键盘发出指令的速度相对于网络带宽能力来说,绝对不是在一个量级上的,所以数据传输非常少;而又要求用户的输入能够及时获得返回,有较低的延时。如果开启了Nagle算法,就很可能出现频繁的延时,导致用户体验极差。当然,你也可以选择在应用层进行buffer,比如使用java中的buffered stream,尽可能地将大包写入到内核的写缓存进行发送;vectored I/O(writev接口)也是个不错的选择。
对于关闭TCP_NODELAY,则是应用了Nagle算法。数据只有在写缓存中累积到一定量之后,才会被发送出去,这样明显提高了网络利用率(实际传输数据payload与协议头的比例大大提高)。但是这由不可避免地增加了延时;与TCP delayed ack这个特性结合,这个问题会更加显著,延时基本在40ms左右。当然这个问题只有在连续进行两次写操作的时候,才会暴露出来。
我们看一下摘自Wikipedia的Nagle算法的伪码实现:
if there is new data to send
if the window size >= MSS and available data is >= MSS
send complete MSS segment now
else
if there is unconfirmed data still in the pipe
enqueue data in the buffer until an acknowledge is received
else
send data immediately
end if
end if
end if
The user-level solution is to avoid write-write-read sequences on sockets. write-read-write-read is fine. write-write-write is fine. But write-write-read is a killer. So, if you can, buffer up your little writes to TCP and send them all at once. Using the standard UNIX I/O package and flushing write before each read usually works.
连续进行多次对小数据包的写操作,然后进行读操作,本身就不是一个好的网络编程模式;在应用层就应该进行优化。
对于既要求低延时,又有大量小数据传输,还同时想提高网络利用率的应用,大概只能用UDP自己在应用层来实现可靠性保证了。好像企鹅家就是这么干的。
以上是关于系统软件工程师面试2. 网络部分的主要内容,如果未能解决你的问题,请参考以下文章