计算机发展史与进程
Posted ghylpb
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了计算机发展史与进程相关的知识,希望对你有一定的参考价值。
目录
1.操作系统发展史
1).穿孔卡片
? 一个机房一次只能使用一个卡片
? CPU使用率极低

2).联机批处理系统
? 支持多用户使用一个计算机机房。
3).脱机批处理系统
? 高速磁带提升了读取的速度,提高了CPU的利用率。
4).多道技术
单道:
(单核情况下)多个用户使用CPU时是串行的,一个一个执行,只有一个程序执行完成才能执行下一个程序 。
多道
(基于单核情况下):在程序A,就在内存中加载程序B,当程序A使用完CPU后B就开始使用CPU(也是只有一个CPU)。
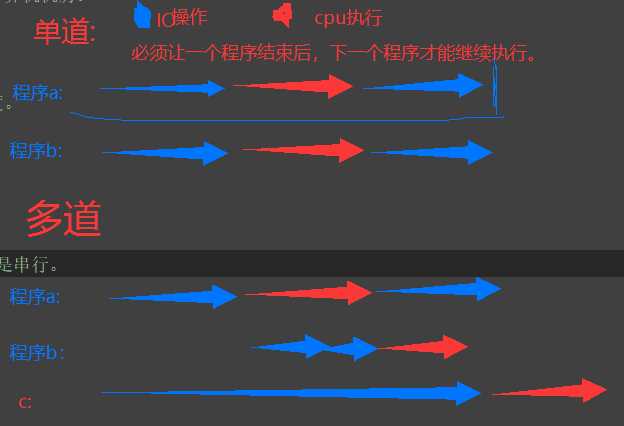
(1).空间上的复用
? 一个淳朴可以提供给多个用户去使用。
(2).时间上的复用(******)
? 切换+保存状态(切换时保存程序当前的执行状态)
? IO操作:input()、print()、time.sleep().
? 1).若CPU遇到IO操作,会立即切断当前执行的程序CPU的使用权
? 优点:CPU的利用率高
? 2).若一个程序使用CPU的时间过长(有设定的cup最常使用时间),立即将当前程序的CPU使用权断开,交给其他程序使用。
? 缺点:降低了程序的执行率。
并发与并行:
? 并发:看起来像同时在运行。(相当于多个程序来回切换)
? 并行:真实的同时运行,在多核的情况下同时执行多个程序。
2.进程
程序与进程
? 程序:一堆代码
? 进程:一堆代码运行的过程
进程调度:
? 1.先来先服务调度:
? a,b程序,若a程序先来,先占用CPU
? 缺点:程序a先使用,程序b必须一直等待
? 2.短作业优先调度:
? a,b程序,谁的时间短,优先调度谁使用
? 缺点:必须等待所有用时短的程序使用结束才能执行用时长的
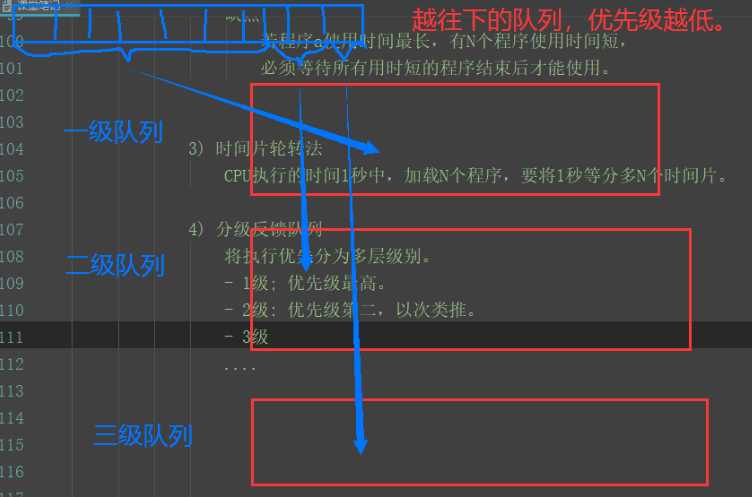
? 3.时间片轮转法
? CPU执行的时间1秒钟,加载n个程序,要将1秒等分成n个时间片(n份)
? 4.分级反馈队列
? 将执行优先分为多层级别
? ——1级:优先级最高
? ——2级:次之,以此类推
? ——3级
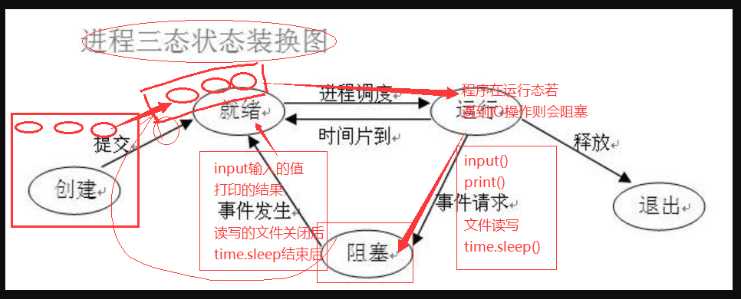
程序运行时的三个状态;
? 就绪态:所有程序创建时都会进入此状态,准备调度。
? 运行态:调度后的进程,进入运行态。
? 阻塞态:凡是遇到IO操作的进程,都会进入阻塞态。若IO结束,必须重新进入就绪态。
同步和异步:
? 指的是提交任务的方式。
? 同步: 若有两个任务需要提交,在提交第一个任务时任务时,必须等待该任务执行结束才能执行下一个任务。
? 异步:若有两个任务提交,第二个任务不需要等待,两个任务可以同时进行。
#同步演示程序:程序一直在运行,并未将CPU的运行权限交出去
import time
def test():
# IO操作
# time.sleep(3)
# 计算操作
num = 1
for line in range(1000000000000000000000000):
num += 1
if __name__ == '__main__':
test()
print('hello tank')阻塞与非阻塞:
? 阻塞:阻塞态,遇到IO定会阻塞
? 非阻塞: 就绪态、 运行态
? 面试题:同步异步,阻塞非阻塞是同一个概念吗?
? 等待不一定是阻塞,有可能某个任务占用CPU的时间过长, 所以他们不是同一个概念,不能混为一谈!
? 最大化提高CPU的使用率:尽可能减少不必要的IO操作
创建进程的两种方式
方式一:定义一个任务
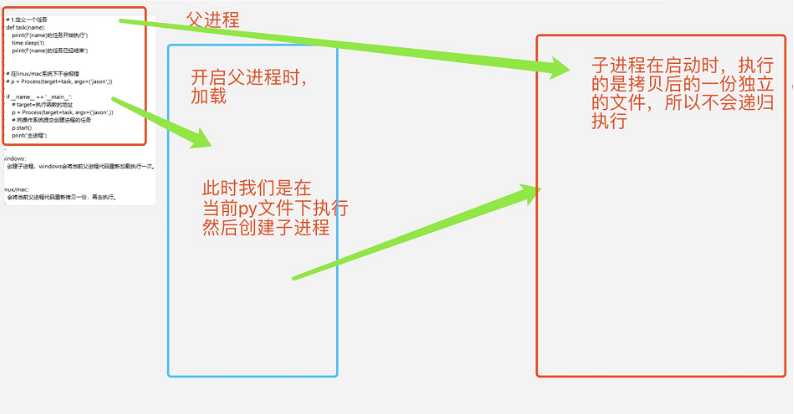
在Windows系统下易发生的错误,子进程创建时会调用父进程的程序,父进程执行时又调用子进程,这样一直下去,造成了递归(windows会把复制的代码当做导入文件)。这种问题只有在Windows系统里才会出现(Windows系统执行创建子进程的任务时,会将当前父进程代码重新加载执行一次),在Mac系统和Linux系统里面会将当前子进程代码重新拷贝一份,单独执行。
import time
from multiprocessing import Process
def task(name):
print(f'{name}的任务开始执行')
time.sleep(1)
print(f'{name}的任务已经结束')
#target=执行函数的地址,agrs里面填元组,且元素是task的函数的参数
p = Process(target=task,args=('jason',))
#向操作系统提交创建进程的任务
p.start()
print('主进程')将子进程写在main函数里面运行程序是就不会先运行父进程,而是从main函数开始运行(main函数里面是子进程),这样就不会出现递归的问题了。
import time
from multiprocessing import Process
def task(name):
print(f'{name}的任务开始执行')
time.sleep(1)
print(f'{name}的任务已经结束')
if __name__ == '__main__':
#target=执行函数的地址,agrs里面填元组,且元素是task的函数的参数
p = Process(target=task,args=('jason',))
#向操作系统提交创建进程的任务
p.start()
print('主进程')方式二:自定义一个类,并继承Process
这里主进程和子进程是并行运行的,他们之间互不影响,各自运行各自的。
from multiprocessing import Process
import time
class MyProcess(Process):
def run(self):
print('任务开始执行')
time.sleep(1)
print('任务已经结束')
if __name__ == '__main__':
p = MyProcess()
p.start()
print('主进程')
主进程
任务开始执行
任务已经结束join方法
作用:告诉操作系统,让子进程结束后,父进程在结束。
from multiprocessing import Process
import time
class MyProcess(Process):
def run(self):
print('任务开始执行')
time.sleep(1)
print('任务已经结束')
if __name__ == '__main__':
p = MyProcess()
p.start()#告诉操作系统,开启子进程
p.join()#告诉操作系统,等子进程结束后,父进程再结束
print('主进程')
任务开始执行
任务已经结束
主进程当开启多个子进程时要用多个join
import time
from multiprocessing import Process
def task(name,n):
print(f'{name}的任务开始执行')
time.sleep(n)
print(f'{name}的任务已经结束')
if __name__ == '__main__':
#target=执行函数的地址,agrs里面填元组,且元素是task的函数的参数
p1 = Process(target=task,args=('jason',1))
p2 = Process(target=task, args=('xiaoming',2))
p3 = Process(target=task, args=('xiaohua',3))
#向操作系统提交创建进程的任务
p1.start()
p2.start()
p3.start()
p1.join()
p2.join()
p3.join()
print('主进程')
jason的任务开始执行
xiaoming的任务开始执行
xiaohua的任务开始执行
jason的任务已经结束
xiaoming的任务已经结束
xiaohua的任务已经结束
主进程进程间的数据是相互隔离的,子进程和主进程会产生各自的名称空间,在执行的时候互不影响。
x = 100
def func():
print('执行func函数。。。')
global x
x = 200
print(f'子程序x:{x}')
if __name__ == '__main__':
p = Process(target=func)
p.start()
print(f'主程序x{x}')
主程序x100
执行func函数。。。
子程序x:200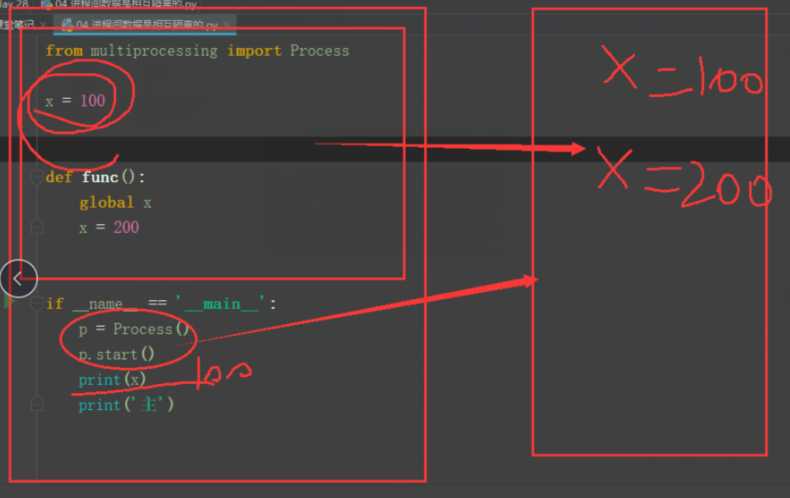
关于进程号
进程号是进程在执行时,操作系统给随机分配的一窜数字,这串数字是有限的,如果操作系统用尽了所有的进程号则系统将不能再有新的进程运行。
courent_process().pid:获取子进程号
os.getpid():获取主进程pid号
os.getppid():获取主进程的父进程(p for parent)
cmd中查看进程号:tasklist|findstr 进程号
进程号回收的两种条件:
1.join,可以回收子进程与主进程。
2.主进程正常结束,子进程与主进程也会被回收。
检查子进程是否存活的方法
子进程.is_alive() 返回的是bool值True or False
终止子进程的方法
子进程.terminate() 让操作系统强行终止子进程
from multiprocessing import Process
import time
from multiprocessing import current_process
def task(name):
print(f'{name} start...', current_process().pid)
time.sleep(1)
print(f'{name} over..', current_process().pid)
if __name__ == '__main__':
p = Process(target=task, args=('jason', ))
p.start() # 告诉操作系统,开启子进程
# 判断子进程是否存活
print(p.is_alive())
# 直接告诉操作系统,终止 子进程
#p.terminate()
time.sleep(0.1)#此处让子进程暂停0.1秒是因为子进程与主进程是并行执行的,而打印操作是在主进程中进行的,如果不暂停的话有可能,主进程执行到最后一步时,子进程还没执行到强制终止的指令,这样就无法得到正确的打印接过了
# 判断子进程是否存活
print(p.is_alive())
p.join() # 告诉操作系统,等子进程结束后,父进程再结束。
True
True
jason start... 8988
jason over.. 8988
加入终止子进程程序后
from multiprocessing import Process
import time
from multiprocessing import current_process
def task(name):
print(f'{name} start...', current_process().pid)
time.sleep(1)
print(f'{name} over..', current_process().pid)
if __name__ == '__main__':
p = Process(target=task, args=('jason', ))
p.start() # 告诉操作系统,开启子进程
# 判断子进程是否存活
print(p.is_alive())
# 直接告诉操作系统,终止 子进程
p.terminate()
time.sleep(0.1)#此处让子进程暂停0.1秒是因为子进程与主进程是并行执行的,而打印操作是在主进程中进行的,如果不暂停的话有可能,主进程执行到最后一步时,子进程还没执行到强制终止的指令,这样就无法得到正确的打印接过了
# 判断子进程是否存活
print(p.is_alive())
p.join() # 告诉操作系统,等子进程结束后,父进程再结束。
True
False僵尸进程与孤儿进程(了解):
? 僵尸进程:子进程已经结束,但pid号还存在未销毁,
? 缺点:占用pid号,占用资源。
? 孤儿进程:指的是子进程还在执行但父进程意外结束。
? 操作系统提供一个福利院,帮忙回收没有父进程的子进程,这就是守护进程。
守护进程
指主进程结束后,该主进程产生的所有子进程也跟着结束并回收。
from multiprocessing import Process
import time
from multiprocessing import current_process
def task(name):
print(f'{name} start...', current_process().pid)
time.sleep(1)
print(f'{name} over..', current_process().pid)
if __name__ == '__main__':
p = Process(target=task, args=('jason', ))
p.daemon = True# True代表该进程是守护进程
p.start() # 告诉操作系统,开启子进程
# 判断子进程是否存活
print(p.is_alive())
# 直接告诉操作系统,终止 子进程
p.terminate()
time.sleep(0.1)#此处让子进程暂停0.1秒是因为子进程与主进程是并行执行的,而打印操作是在主进程中进行的,如果不暂停的话有可能,主进程执行到最后一步时,子进程还没执行到强制终止的指令,这样就无法得到正确的打印接过了
# 判断子进程是否存活
print(p.is_alive())
p.join() # 告诉操作系统,等子进程结束后,父进程再结束。
?
以上是关于计算机发展史与进程的主要内容,如果未能解决你的问题,请参考以下文章