BloomFilter在Hbase中的实现与应用
Posted andyhe
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了BloomFilter在Hbase中的实现与应用相关的知识,希望对你有一定的参考价值。
在HFILE文件中的存储
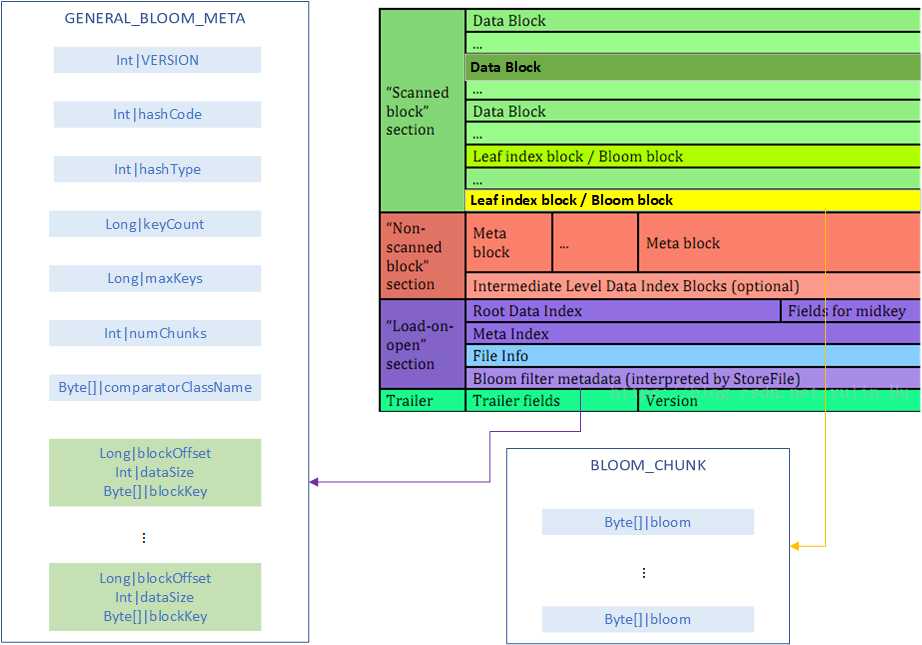
BloomFilterChunk
/** Bytes (B) in the array. This actually has to fit into an int. */
protected long byteSize;
/** Number of hash functions */
protected int hashCount;
/** Hash type */
protected final int hashType;
/** Hash Function */
protected final Hash hash;
/** Keys currently in the bloom */
protected int keyCount;
/** Max Keys expected for the bloom */
protected int maxKeys;
/** Bloom bits */
protected ByteBuffer bloom;
/** The type of bloom */
protected BloomType bloomType;
public void allocBloom() {
if (this.bloom != null) {
throw new IllegalArgumentException("can only create bloom once.");
}
this.bloom = ByteBuffer.allocate((int)this.byteSize);
assert this.bloom.hasArray();
}
public void add(Cell cell) {
/*
* For faster hashing, use combinatorial generation
* http://www.eecs.harvard.edu/~kirsch/pubs/bbbf/esa06.pdf
*/
int hash1;
int hash2;
HashKey<Cell> hashKey;
if (this.bloomType == BloomType.ROW) {
hashKey = new RowBloomHashKey(cell);
hash1 = this.hash.hash(hashKey, 0);
hash2 = this.hash.hash(hashKey, hash1);
} else {
hashKey = new RowColBloomHashKey(cell);
hash1 = this.hash.hash(hashKey, 0);
hash2 = this.hash.hash(hashKey, hash1);
}
setHashLoc(hash1, hash2);
}
private void setHashLoc(int hash1, int hash2) {
for (int i = 0; i < this.hashCount; i++) {
long hashLoc = Math.abs((hash1 + i * hash2) % (this.byteSize * 8));
set(hashLoc);
}
++this.keyCount;
}
void set(long pos) {
int bytePos = (int)(pos / 8);
int bitPos = (int)(pos % 8);
byte curByte = bloom.get(bytePos);
curByte |= BloomFilterUtil.bitvals[bitPos];
bloom.put(bytePos, curByte);
}
static boolean get(int pos, ByteBuffer bloomBuf, int bloomOffset) {
int bytePos = pos >> 3; //pos / 8
int bitPos = pos & 0x7; //pos % 8
// TODO access this via Util API which can do Unsafe access if possible(?)
byte curByte = bloomBuf.get(bloomOffset + bytePos);
curByte &= BloomFilterUtil.bitvals[bitPos];
return (curByte != 0);
}
- 使用
ByteBuffer实际存储bit数组,因此get和set过程都需要进行相应的转换,计算byte[]的index再计算byte内bit的index。 - 由于hash函数个数是不定地,该类中使用一个hash函数通过不同的
seed计算出hash1和hash2然后根据定义的hash函数的个数,按照公式hash1+i*hash2循环计算出n个hash值。
flush过程写入到HFILE
flush的过程中会为各个Cell设置布隆过滤器,再HFileclose的时候统一把Bloom Block和Bloom Meta 持久化到HFile中,调用时序图如下:
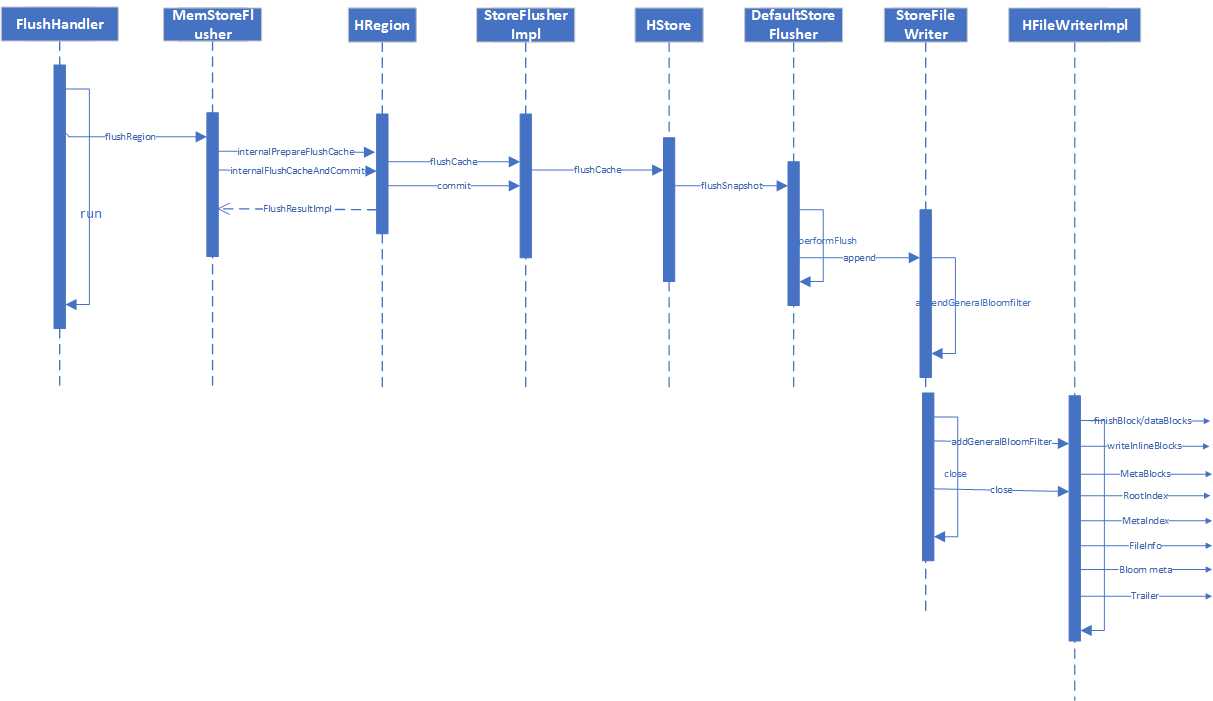
StoreFileWriter:
@Override
public void append(final Cell cell) throws IOException {
appendGeneralBloomfilter(cell);
appendDeleteFamilyBloomFilter(cell);
writer.append(cell);
trackTimestamps(cell);
}
public void close() throws IOException {
boolean hasGeneralBloom = this.closeGeneralBloomFilter();
boolean hasDeleteFamilyBloom = this.closeDeleteFamilyBloomFilter();
writer.close();
// Log final Bloom filter statistics. This needs to be done after close()
// because compound Bloom filters might be finalized as part of closing.
if (LOG.isTraceEnabled()) {
LOG.trace((hasGeneralBloom ? "" : "NO ") + "General Bloom and " +
(hasDeleteFamilyBloom ? "" : "NO ") + "DeleteFamily" + " was added to HFile " +
getPath());
}
}HFileWriterImpl:
private void addBloomFilter(final BloomFilterWriter bfw,
final BlockType blockType) {
if (bfw.getKeyCount() <= 0)
return;
if (blockType != BlockType.GENERAL_BLOOM_META &&
blockType != BlockType.DELETE_FAMILY_BLOOM_META) {
throw new RuntimeException("Block Type: " + blockType.toString() +
"is not supported");
}
additionalLoadOnOpenData.add(new BlockWritable() {
@Override
public BlockType getBlockType() {
return blockType;
}
@Override
public void writeToBlock(DataOutput out) throws IOException {
bfw.getMetaWriter().write(out);
Writable dataWriter = bfw.getDataWriter();
if (dataWriter != null)
dataWriter.write(out);
}
});
}
get过程应用BF进行scanner过滤
get的时候会根据bloom filter类型对HFile进行过滤。调用时序图如下:
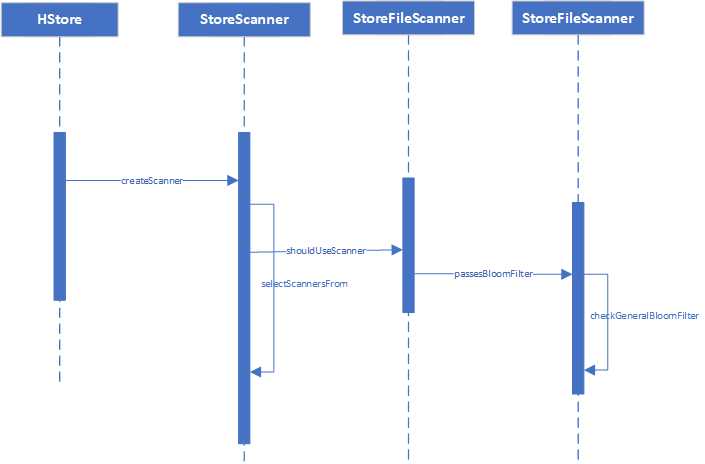
StoreFileReader.checkGeneralBloomFilter
// Whether the primary Bloom key is greater than the last Bloom key
// from the file info. For row-column Bloom filters this is not yet
// a sufficient condition to return false.
boolean keyIsAfterLast = (lastBloomKey != null);
// hbase:meta does not have blooms. So we need not have special interpretation
// of the hbase:meta cells. We can safely use Bytes.BYTES_RAWCOMPARATOR for ROW Bloom
if (keyIsAfterLast) {
if (bloomFilterType == BloomType.ROW) {
keyIsAfterLast = (Bytes.BYTES_RAWCOMPARATOR.compare(key, lastBloomKey) > 0);
} else {
keyIsAfterLast = (CellComparator.getInstance().compare(kvKey, lastBloomKeyOnlyKV)) > 0;
}
}
if (bloomFilterType == BloomType.ROWCOL) {
// Since a Row Delete is essentially a DeleteFamily applied to all
// columns, a file might be skipped if using row+col Bloom filter.
// In order to ensure this file is included an additional check is
// required looking only for a row bloom.
Cell rowBloomKey = PrivateCellUtil.createFirstOnRow(kvKey);
// hbase:meta does not have blooms. So we need not have special interpretation
// of the hbase:meta cells. We can safely use Bytes.BYTES_RAWCOMPARATOR for ROW Bloom
if (keyIsAfterLast
&& (CellComparator.getInstance().compare(rowBloomKey, lastBloomKeyOnlyKV)) > 0) {
exists = false;
} else {
exists =
bloomFilter.contains(kvKey, bloom, BloomType.ROWCOL) ||
bloomFilter.contains(rowBloomKey, bloom, BloomType.ROWCOL);
}
} else {
exists = !keyIsAfterLast
&& bloomFilter.contains(key, 0, key.length, bloom);
}备注
version:2.1.7
以上是关于BloomFilter在Hbase中的实现与应用的主要内容,如果未能解决你的问题,请参考以下文章