巡风扫描器工作流程
Posted liangxiyang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了巡风扫描器工作流程相关的知识,希望对你有一定的参考价值。
这两周学习了巡风扫描器的搭建,也在学长的带领下看了各部分的下源代码,为了加深记忆,梳理一下巡风大体的工作流程,主要通过web端的页面分析,错误的地方还请大佬们多多指正。
先整体看一下巡风的扫描流程:配置页面进行配置->到统计页面查看记录总数、IP总数、以及漏斗分析->到搜索页面输入搜索条件->选中一个或多个搜索结果,右上角新增任务->输入任务名称,选择插件->点击任务名称,即可查看任务详情
0x01:配置页面
登录之后,点击配置页面,默认是爬虫引擎配置,还有一种是扫描引擎配置,后端是通过get请求的参数区分,在配置页面,可以自定义扫描方式、线程数、超时时间、资产列表等。更改配置后,后端通过UpdateConfig这个视图函数更新配置,
 UpdateConfig
UpdateConfig
下面让看下每一项配置的作用:
资产探测周期配置:

每天固定的时间点扫描,进行资产探测收集。
网络资产探测列表配置
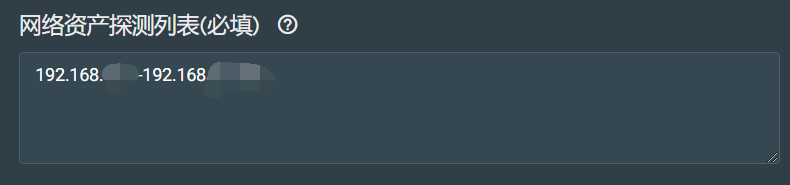
在这个地方,可以设置需要探测的内网的地址段,可以设置成图中格式,也可以设置成cidr(https://www.cnblogs.com/liangxiyang/p/11628000.html)地址格式,另外,探测列表一旦更改,则会立即触发扫描,进行资产收集。
启用MASSCAN和端口探测列表配置:
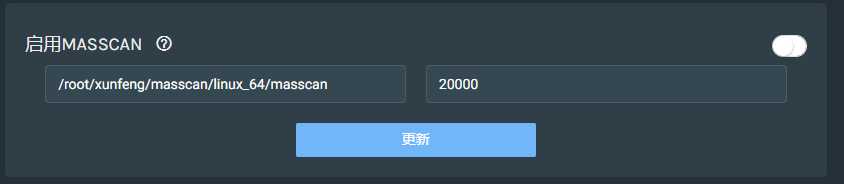
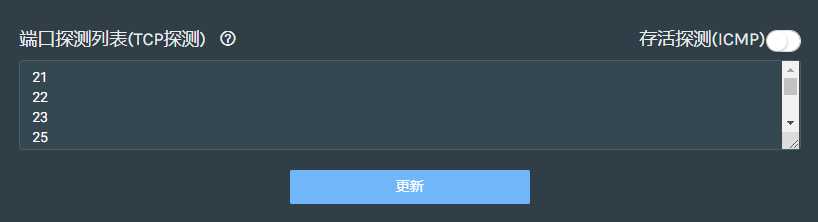
这两个配置都是用来探测端口的,默认是ICMP方式,只对存活的IP地址进行指定端口的探测,MASSCAN方式探测1-65535的端口,第一个方框内为路径地址,第二个方框内为发包速率。
服务类型识别配置:
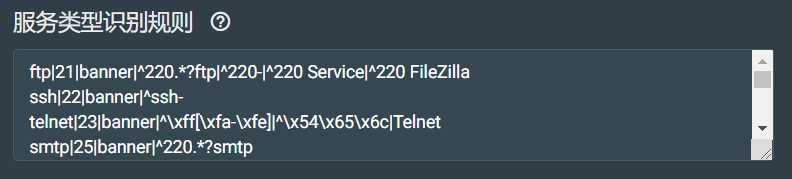
用于识别开放端口上所运营的服务。
cms识别规则配置:
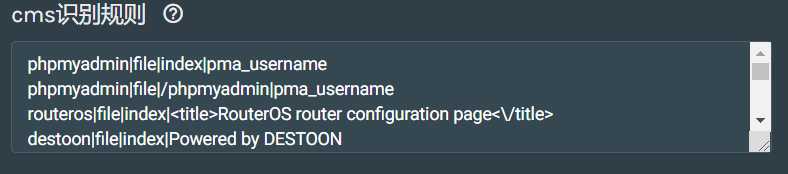
CMS英文全称是:Content Management System 中文名称是: 网站内容管理系统 (CMS最擅长的就是建设网站,最流行的CMS有:国外的:Wordpress,Drupal,Joomla,这是国外最流行的3大CMS。国内则是DedeCMS和帝国,phpCMS等)。CMS识别原理就是得到一些CMS的一些固有特征,通过得到这个特征来判断CMS的类别。 比如使用MD5识别和正则表达式识别的方式,就是用特定的文件路径访问网站,获得这个文件的MD5或者用正则表达式匹配某个关键词,如果匹配成功就说明这个是这个CMS。 所以,这个识别的成功率是根据我们的字典来的。
代码语言识别规则配置:
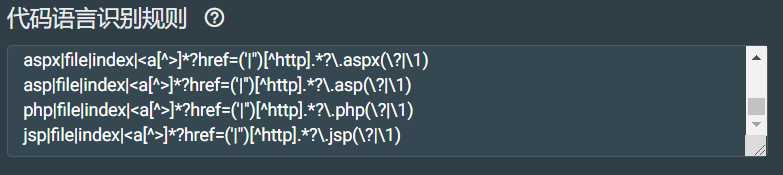
用于识别web网站的开发语言,通过响应头、文件等
组件容器识别配置:
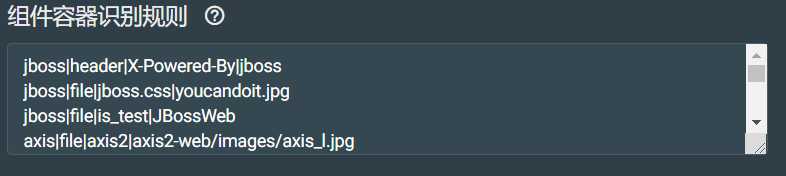
用于识别web的容器、中间件等组件。对容器、中间件等不了解,网上搜了一下:容器作为操作系统和应用程序之间的桥梁,给处于其中的应用程序组件提供一个环境,使应用程序直接跟容器中的环境变量交互,不必关注其它系统问题。
0x02:统计页面
配置页面完成后,立即开始进行资产探测、可以在统计页面看到资产探测结果:
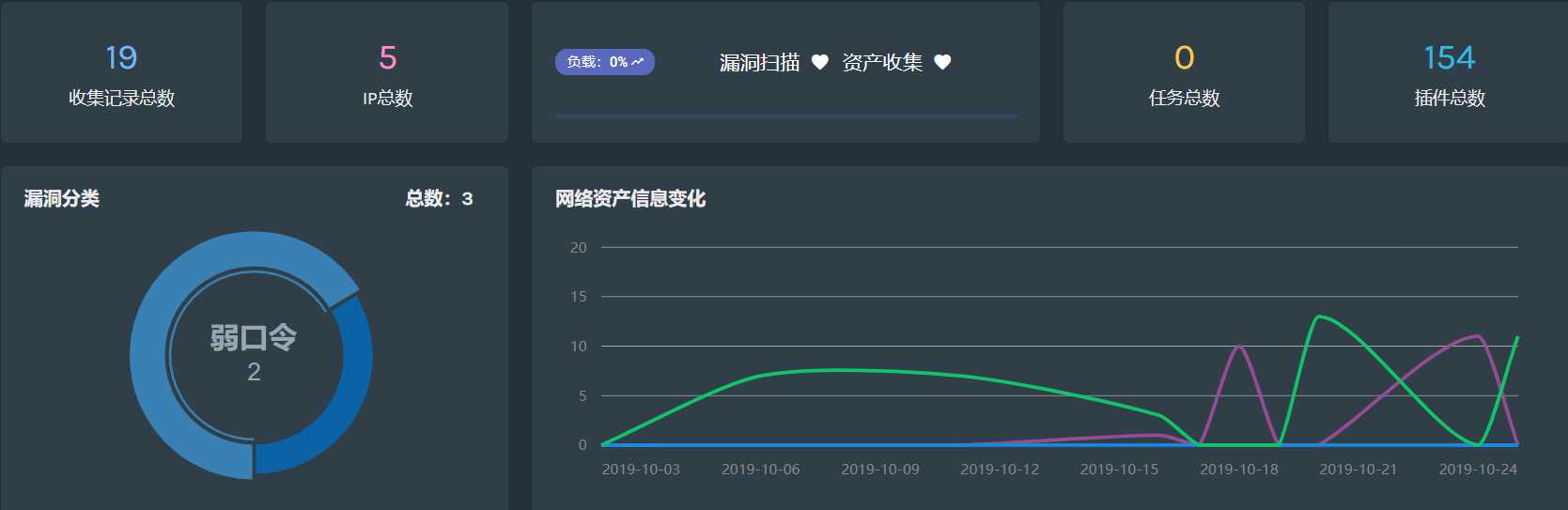
0x03:搜索页面
资产探测完成后,就可以根据搜索规则,搜索需要的端口,ip等。
比如:查看所有开放25端口的IP,在搜索框输入port:25。 查看指定IP、IP段等

0x04:任务页面
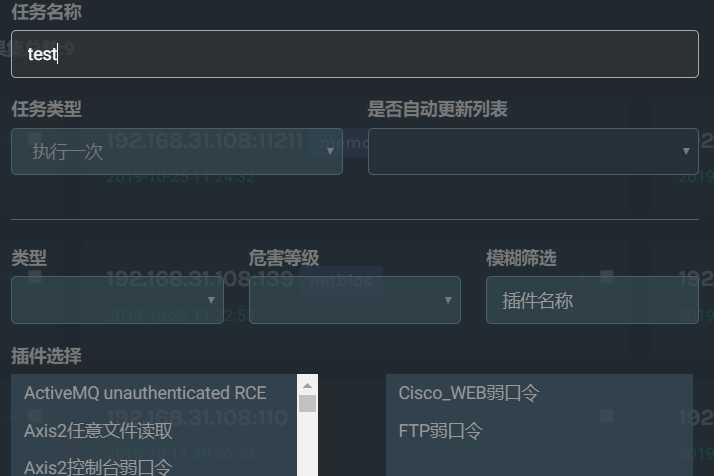
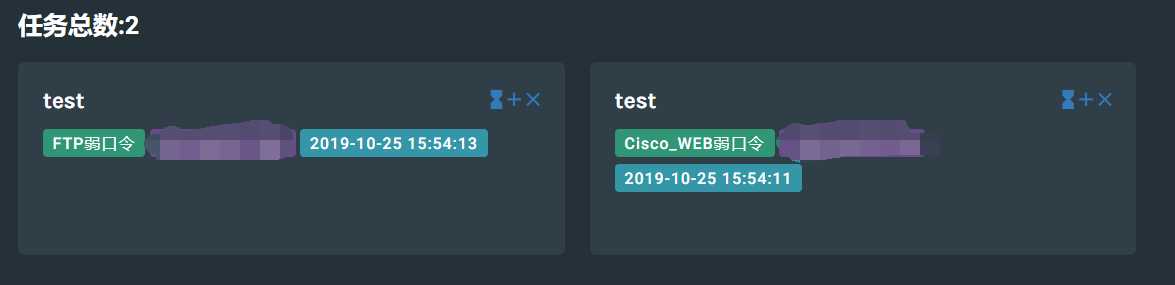
搜索出结果后,可以选中其中的一个或多个(作为目标),然后新增任务,选择插件类型,根据选择的插件数量创建任务,后端就会进行任务扫面扫描,点击任务名称,即可查看该任务的详情。
***************不积跬步无以至千里***************
以上是关于巡风扫描器工作流程的主要内容,如果未能解决你的问题,请参考以下文章