周报3
Posted imfulina
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了周报3相关的知识,希望对你有一定的参考价值。
1.《T:Modeling Indivdualization in a Bayesian Networks Implementation od Konwledge Tracing》(贝叶斯网络中知识追踪的个性化建模)
1.本文目标:说明学生先验知识的数据越来,应该能够实现更好的拟合模型和更准确地学生数据预测。
知识追踪模型:假设所有学生共享相同的初始先验知识,不允许每个学生的先验信息被合并。
本文模型:对知识追踪模型的一种修改,通过允许指定多个先验知识参数来增加其通用性,并让贝叶斯网络确定学生在信息未知的情况下属于哪个先验参数值。
2.The Prior Per Student model(PPS模型)
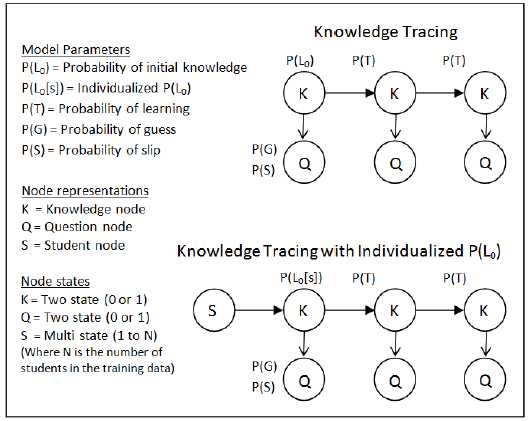
PPS模型只关注先验知识参数的个性化,与KT模型的区别在于能够为每个学生表示不同的先验知识参数,KT模型是每个学生先验模型的一个特例。通过添加一个学生节点,来实现个性化先值。
3.实验
学习速率、猜测和滑动参数的初始值被随机设置为0.0.到0.9之间。每个问题的数据集,出来回答最后一个问题,被用来训练参数,采用EM算法学习参数后,预测学生的表现。学生答对最后一道题的概率被计算出来并保存下来,以便与实际的答案进行比较。
个性化初始值的设定方法,本文主要关注两个方面:(a)个性化初始值的如何设置 (b) 个性化初始值的设置是否固定或在EM参数学习过程中可调。
(1)个性化初始值设置为随机值:在EM参数学习过程中可调,如其它参数一样
(2)根据学生的第一次回答来设置个性化初始值:学生正确的回答了第一个问题,个性化初始值被设为1减去一个特别的猜测值(guess),如果错误回答第一个问题,则被设为一个特别的滑动值(slip)。之所以使用特别的slip值和guess,是因为这些值必须在学习参数之前使用。本文使用特别的猜测值0.15和滑动值0.1。其他非个性化的参数值被设置为第一次回答的平均值,在个性化参数固定的前提下,非个性化参数允许被调整。这种方法被称为“cold start heuristic"
(3)基于全局正确率设置个性化初始值:假设学生在一个问题集与下一个问题集存在相关性,或者从一个技能到下一项技能之间存在相关性。这种假设最接近模型的策略,该模型假设每个学生都有一个先验值,这个值在所有技能上都是相同的。计算学生完成所有问题集(除了预测的问题集)的正确百分比。若学生只完成了被预测的问题,则他的个性化初始值是其他学生的个性化初始值得平均值。个性化初始值是固定的,非个性化初始值是可调整的。
结果
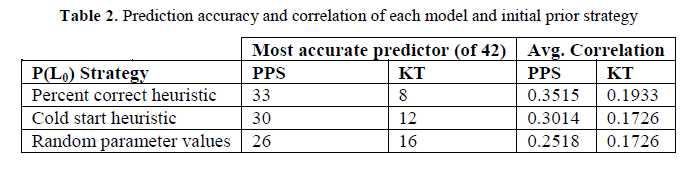
计算最后一个问题的真实回答和预测回答之间的相关性(Correlation)。结果显示PPS模型更优于KT模型。Percent correct heuristic策略在42个问题集中,有33个问题集优于KT模型。
4.分析回答序列
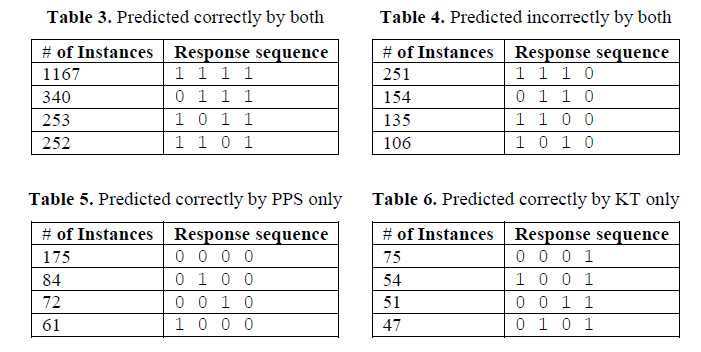
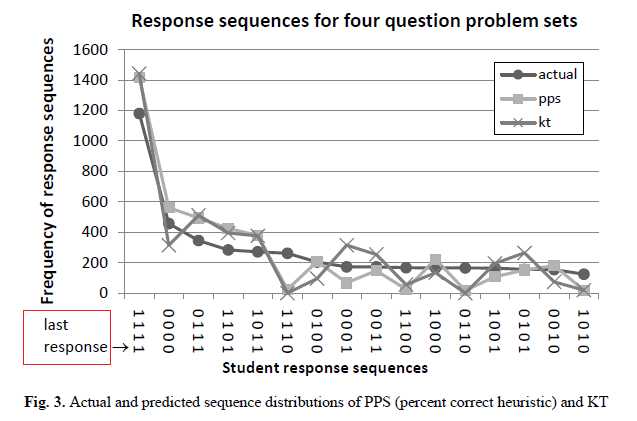
检视模型在哪种情况下可以正确预测或错误预测。查看序列,并统计多少次模型预测最后一个问题的回答是正确或错误的。分析了在11个问题集,4448个学生回答序列。表3和表4显示两个模型都预测最后一个问题回答正确或错误的回答序列(这里只列出了出现次数多的序列),表5和表6显示只有一个模型预测最后一个问题回答正确的回答序列。结果显示PPS模型优于KT模型的预测。
5.未来工作
作者希望这篇论文是一个开始,尝试更好地个性化,从而在智能辅导系统,个性化学生的学习经验。
作者想知道在什么情况下使用PPS是没有好处的。当然,如果在现实中所有的学生在每个技能上都有相同的先验,那么在建立一个个性化的先验时就没有效用了。另一方面,如果学生对某项技能的先验知识差异很大,这似乎是事实,那么个性化的先验知识将通过捕捉该参数的变化,导致更好的拟合模型。
每个学生都需要一个单独的参数吗?或者可以通过将单独的参数分组到集群中,来实现相同或更好的性能吗?有着相对较高的性能的cold start heuristic模型表明,根据学生对给定技能的第一反应,将他们分为两个先验参数的其中一个,这样是有效的。虽然这种启发式方法有效,但我们怀疑有更好的表示方法,并且在学习之前允许集群的值,而不是像我们那样临时设置。Ritter等人最近的[8]研究表明,聚类相似的技能可以极大地减少在拟合数百种技能时需要学习的参数数量,同时仍然保持对数据的高度拟合。也许可以采用类似的方法来寻找学生群并学习他们的参数,而不是为每个学生学习个性化的参数。
本文的工作集中在知识追踪的四个参数中的一个。希望看到,通过明确地模拟学生有不同的学习率这一事实,能否实现更高水平的预测准确性。学生收到的问题和辅导反馈可以根据他的学习速度进行调整。学生的学习率也可以报告给老师,让他们更准确或更迅速地了解他们的班级的学生。猜测和滑动个性化也是可能的,直接与Baker‘s的上下文猜测和滑动方法相比较,将是未来工作的一个方面。
已经证明,选择每个学生的先验表示,而不是知识追踪的每个技能的先验表示,对于拟合我们的数据集是有益的;然而,更好的模型可能是将学生的属性与技能的属性相结合的模型。如何设计恰当处理这两种信息交互的模型是该领域的一个开放研究问题。本文相信,为了扩展个性化的利益系统的新用户,多个问题集必须被连接在一个贝叶斯网络,利用多个问题集的证据来帮助跟踪单个学生知识和更充分地获得收益百分比建议的正确的启发式。
2.《Addressing Two Problems in Deep Knowledge Tracing via Prediction-Consistent Regularization》(借助正则项解决深度知识追踪的两个问题)
本文作者发现DKT模型两个问题:1.输入序列存在重构问题;2.预测结果的波动性
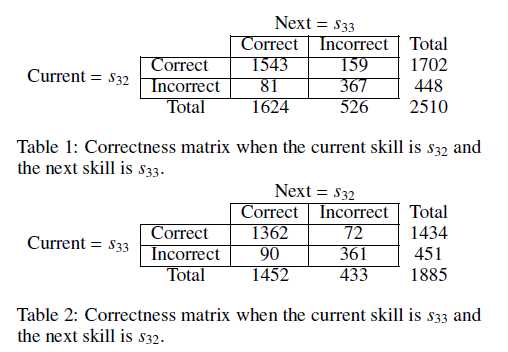
(1)对于问题1,存在着当学生可以很好回答知识点k的问题,但模型预测学生掌握知识点k的概率忽高忽低的现象。作者认为出现这种情况是由于,在DKT模型采用的损失函数中并没有考虑到时间t时刻的输入值,只是考虑了t时刻的输出值和t+1时刻的输入值。由于这个问题,会出现这样的现象:当序列(S32,0)(S33,0)频繁出现时,模型将会认为当问题S32回答正确/错误时, S33也将会回答正确/错误。作者通过实验证明问题S32和S33之间没有前后相关性,实验如下所示。
针对上述问题,本文的解决方法是作者在损失函数中引入正则项,并在正则项中引入了时间t时刻的输入值,正则项r如下:
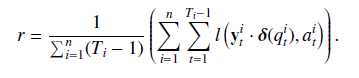
(2)对于问题2,模型预测的知识状态随时间波动且不一致,这是实际的,因为预期中学生对知识掌握状态,应该随着时间逐渐趋于稳定。
本文认为可能是由于RNN的隐层表示问题,隐含层表示了潜在的学生知识掌握程度,RNN的隐含层ht依赖于前一隐含层输出,但是很难说清隐含层的每个状态是如何影响模型的预测。所以作则直接对输出结果进行正则约束(L1,L2正则),使预测结果能够平滑输出,正则项w如下所示;
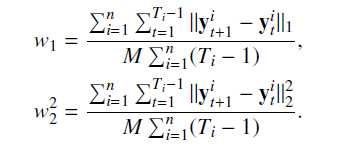
论文的代码已经在GitHub上找到,并能在本地运行。
3.《NPA: Neural News Recommendation with Personalized Attention》(借助个性化注意力机制进行新闻推荐)
新闻推荐是在线新闻平台的一项重要任务。面对互联网上每天产生的海量新闻,新闻推荐帮助用户发现感兴趣的新闻,并减轻信息过载。
在浏览新闻时,不同的用户通常有着不同的兴趣,并且对于同一篇新闻,不同的用户往往会关注其不同方面。然而已有的新闻推荐方法往往无法建模不同用户对同一新闻的兴趣差异。
在新闻推荐场景中有两个常见的观察结果:
1.并非所有用户点击的新闻都能反映用户的偏好;同样的新闻对不同的用户应该有着不同的信息量,以便对不同的用户进行建模。
2.新闻标题中的不同词汇通常具有不同的学习新闻表征的信息量;同时,新闻标题中的相同词语也可能具有不同的信息量,以反映用户的不同偏好。
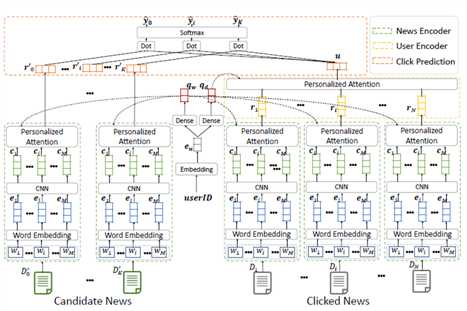
本论文提出了一种 neural news recommendation with personalized attention(NPA) 模型,可在新闻推荐任务中应用个性化注意力机制来建模用户对于不同词汇和新闻的不同兴趣。该模型的核心是新闻表示、用户表示和点击预估:
1. News Encoder:基于新闻标题进行学习。新闻标题中的每个词语先被映射为词向量,然后使用 CNN 来学习词语的上下文表示,最后通过单词级的注意力机制选取重要的词语,构建新闻标题的表示。
2. User Encoder:从用户单击新闻的中了解用户的偏好,该模块使用新闻级的个性化注意力机制。
3. Click Predictor:用于预测用户对每个候选新闻的点击得分。
模型:
实验
实验数据来自MSN新闻,随机抽取10000名用户在一个月内使用MSN的数据作为数据集。下图是本模型是与其他推荐模型的对比结果。
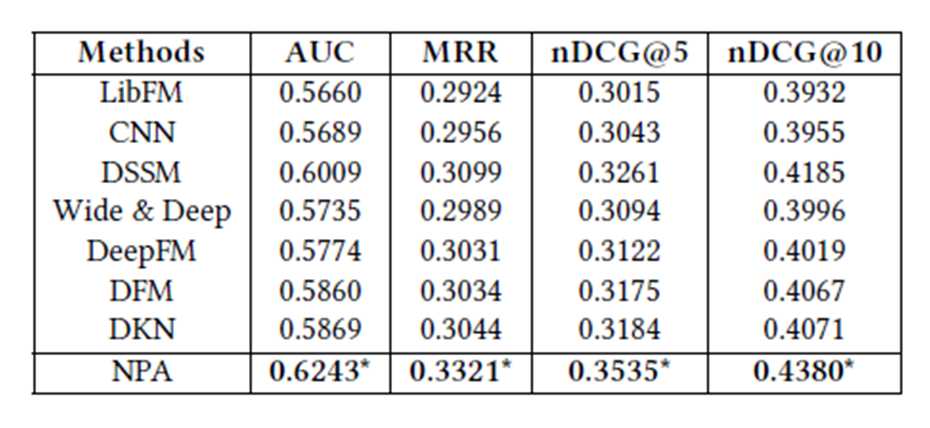
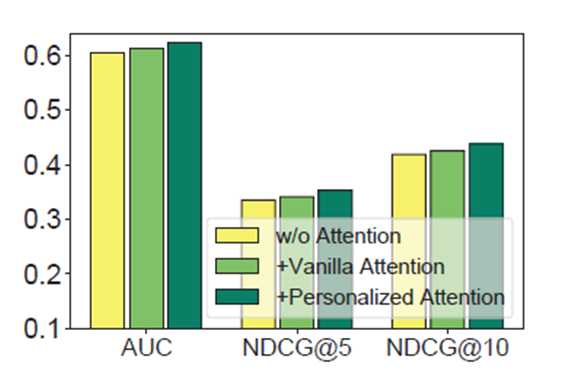
下图结果显示了使用Personalized Atterntion比不使用Atterntion和Vanilla Attention的推荐效果要好。
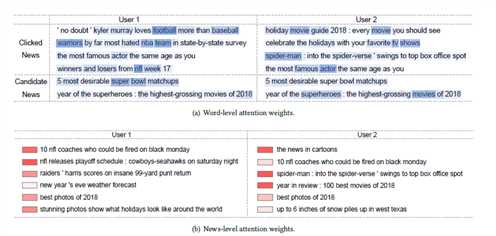
下图显示了新闻标题中的不同单词对不同用户的信息量不同,不同的新闻对不同的用户的信息量也不同。
启发:知识追踪能否借助Attention来提高预测效果。
以上是关于周报3的主要内容,如果未能解决你的问题,请参考以下文章