数据结构中的堆(Heap)
Posted therhyme
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据结构中的堆(Heap)相关的知识,希望对你有一定的参考价值。
堆排序总结
这是排序,不是查找!!!查找去找二叉排序树等。
满二叉树一定是完全二叉树,但完全二叉树不一定是满二叉树。
构建顶堆:
a.构造初始堆
b.从最后一层非叶节点开始调整,一直到根节点
c.如果还不满足,重复b操作,直到构建出一个大顶堆或小顶堆。
构建大顶堆:每次调整都是从父节点、左孩子节点、右孩子节点三者中选择最大者跟父节点进行交换。
(重点)输出排序后的序列:一个大顶堆,获得最大值后,
1. 输出堆顶;
2. 将最后一个堆元素送入堆顶,堆被破坏;
3. 重新构建一个堆,此时,从堆顶开始调整,即将父节点和孩子结点最大值与父节点的值交换,一直调整到最后一层非叶结点;
4. 重复1,2,3操作,直到将堆中所有元素输出,则所有输出序列就是降序排列。
下面的内容来源:https://www.jianshu.com/p/6b526aa481b1
堆就是用数组实现的二叉树,所有它没有使用父指针或者子指针。
堆根据“堆属性”来排序,“堆属性”决定了树中节点的位置。
堆的常用方法:
- 构建优先队列
- 支持堆排序
- 快速找出一个集合中的最小值(或者最大值)
- 在朋友面前装逼
堆属性
堆分为两种:最大堆和最小堆,两者的差别在于节点的排序方式。
在最大堆中,父节点的值比每一个子节点的值都要大;
在最小堆中,父节点的值比每一个子节点的值都要小。
这就是所谓的“堆属性”,并且这个属性对堆中的每一个节点都成立。
例子:
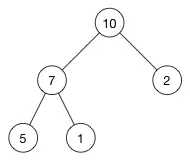
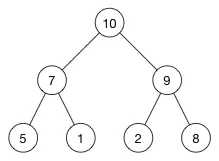
这是一个最大堆,因为每一个父节点的值都比其子节点要大。10 比 7 和 2 都大。7 比 5 和 1都大。
根据这一属性,那么最大堆总是将其中的最大值存放在树的根节点。而对于最小堆,根节点中的元素总是树中的最小值。
堆属性非常的有用,因为堆常常被当做优先队列使用,因为可以快速的访问到“最重要”(优先级高)的元素。
注意:堆的根节点中存放的是最大或者最小元素,但是其他节点的排序顺序是未知的。例如,在一个最大堆中,最大的那一个元素总是位于 index 0 的位置,但是最小的元素则未必是最后一个元素。--唯一能够保证的是最小的元素是一个叶节点,但是不确定是哪一个。
堆和普通树的区别
堆并不能取代二叉搜索树,它们之间有相似之处也有一些不同。我们来看一下两者的主要差别:
1. 节点的顺序。
在二叉搜索树中,左子节点必须比父节点小,右子节点必须必比父节点大。但是在堆中并非如此。
在最大堆中两个子节点都必须比父节点小,而在最小堆中,它们都必须比父节点大。
2. 内存占用。
普通树占用的内存空间比它们存储的数据要多。你必须为节点对象以及左/右子节点指针分配额外的内存。
堆仅仅使用一个数组来存储数据,且不使用指针。
3. 平衡。
二叉搜索树必须是“平衡”的情况下,其大部分操作的复杂度才能达到O(log n)。
你可以按任意顺序位置插入/删除数据,或者使用 AVL 树或者红黑树,但是在堆中实际上不需要整棵树都是有序的。我们只需要满足"堆属性"即可,所以在堆中平衡不是问题。因为堆中数据的组织方式可以保证O(log n) 的性能。
4. 搜索。
在二叉树中搜索会很快,但是在堆中搜索会很慢,堆根本不是用来搜索的。在堆中搜索不是第一优先级,因为使用堆的目的是将最大(或者最小)的节点放在最前面,从而快速的进行相关插入、删除操作。
来自数组的树
用数组来实现树相关的数据结构也许看起来有点古怪,但是它在时间和空间山都是很高效的。
我们准备将上面的例子中的树这样存储:
[ 10, 7, 2, 5, 1 ]
就这多!我们除了一个简单的数组以外,不需要任何额外的空间。
如果我们不允许使用指针,那么我们怎么知道哪一个节点是父节点,哪一个节点是它的子节点呢?问得好!节点在数组中的位置index 和它的父节点以及子节点的索引之间有一个映射关系。
(重点)如果 i 是节点的索引,那么下面的公式就给出了它的父节点和子节点在数组中的位置:
parent(i) = floor((i - 1)/2)
left(i) = 2i + 1
right(i) = 2i + 2
注意 right(i) 就是简单的 left(i) + 1。左右节点总是处于相邻的位置。
我们将写公式放到前面的例子中验证一下。
| Node | Array index (i) | Parent index | Left child | Right child |
|---|---|---|---|---|
| 10 | 0 | -1 | 1 | 2 |
| 7 | 1 | 0 | 3 | 4 |
| 2 | 2 | 0 | 5 | 6 |
| 5 | 3 | 1 | 7 | 8 |
| 1 | 4 | 1 | 9 | 10 |
注意:根节点
(10)没有父节点,因为-1不是一个有效的数组索引。同样,节点(2),(5)和(1)没有子节点,因为这些索引已经超过了数组的大小,所以我们在使用这些索引值的时候需要保证是有效的索引值。
复习一下,在最大堆中,父节点的值总是要大于(或者等于)其子节点的值。这意味下面的公式对数组中任意一个索引 i都成立:
array[parent(i)] >= array[i]
可以用上面的例子来验证一下这个堆属性。
如你所见,这些公式允许我们不使用指针就可以找到任何一个节点的父节点或者子节点。事情比简单的去掉指针要复杂,但这就是时间换空间:我们节约了空间,但是要进行更多计算。幸好这些计算很快并且只需要O(1)的时间。
理解数组索引和节点位置之间的关系非常重要。这里有一个更大的堆,它有15个节点被分成了4层:
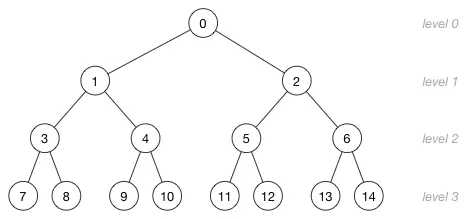
图片中的数字不是节点的值,而是存储这个节点的数组索引!这里是数组索引和树的层级之间的关系:
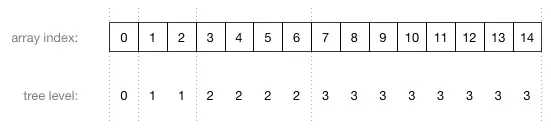
由上图可以看到,数组中父节点总是在子节点的前面。
注意这个方案有一些限制。你可以在普通二叉树中按照下面的方式组织数据,但是在堆中不可以:
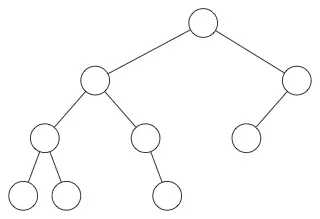
在堆中,在当前层级所有的节点都已经填满之前不允许开是下一层的填充(即完全二叉树),所以堆总是有这样的形状:
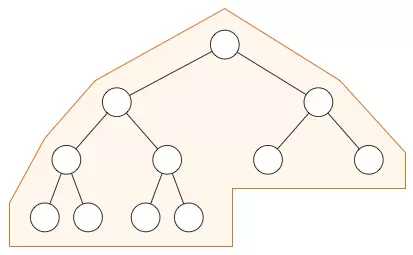
注意:你可以使用普通树来模拟堆,但是那对空间是极大的浪费。
小测验,假设我们有这样一个数组:
[ 10, 14, 25, 33, 81, 82, 99 ]
这是一个有效的堆吗?答案是 yes !一个从低到高有序排列的数组是以有效的最小堆,我们可以将这个堆画出来:
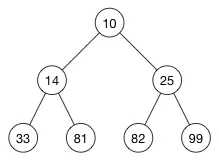
堆属性适用于每一个节点,因为父节点总是比它的孩子节点小。(你也可以验证一下:一个从高到低有序排列的数组是一个有效的最大堆)
注意:并不是每一个最小堆都是一个有序数组!要将堆转换成有序数组,需要使用堆排序。
更多数学公式
如果你好奇,这里有更多的公式描述了堆的一些确定属性。你不需要知道这些,但它们有时会派上用场。 可以直接跳过此部分!
树的高度是指从树的根节点到最低的叶节点所需要的步数,或者更正式的定义:高度是指节点之间的边的最大值。
一个高度为 h 的堆有 h+1 层(和之前学过的数据结构书上定义的高度有点不一样)。
下面这个堆的高度是3,所以它有4层:
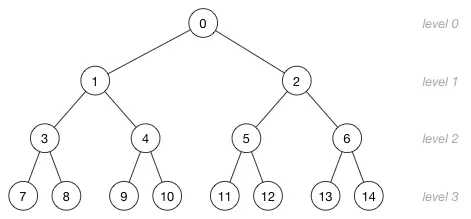
如果一个堆有 n 个节点,那么它的高度是 h = floor(log2(n))。这是因为我们总是要将这一层完全填满以后才会填充新的一层。上面的例子有 15 个节点,所以它的高度是 floor(log2(15)) = floor(3.91) = 3。
如果最下面的一层已经填满,那么那一层包含 2^h 个节点。树中这一层以上所有的节点数目为 2^h - 1。同样是上面这个例子,最下面的一层有8个节点,实际上就是 2^3 = 8。前面的三层一共包含7的节点,即:2^3 - 1 = 8 - 1 = 7。
所以整个堆中的节点数目为:* 2^(h+1) - 1*。上面的例子中,2^4 - 1 = 16 - 1 = 15
叶节点总是位于数组的 floor(n/2) 和 n-1 之间。
可以用堆做什么?
(重点)有两个原始操作用于保证插入或删除节点以后堆是一个有效的最大堆或者最小堆:
shiftUp(): 如果一个节点比它的父节点大(最大堆)或者小(最小堆),那么需要将它同父节点交换位置。这样是这个节点在数组的位置上升。shiftDown(): 如果一个节点比它的子节点小(最大堆)或者大(最小堆),那么需要将它向下移动。这个操作也称作“堆化(heapify)”。
shiftUp 或者 shiftDown 是一个递归的过程,所以它的时间复杂度是 O(log n)。
基于这两个原始操作还有一些其他的操作:
insert(value): 在堆的尾部添加一个新的元素,然后使用shiftUp来修复对。remove(): 移除并返回最大值(最大堆)或者最小值(最小堆)。为了将这个节点删除后的空位填补上,需要将最后一个元素移到根节点的位置,然后使用shiftDown方法来修复堆。removeAtIndex(index): 和remove()一样,差别在于可以移除堆中任意节点,而不仅仅是根节点。当它与子节点比较位置不时无序时使用shiftDown(),如果与父节点比较发现无序则使用shiftUp()。replace(index, value):将一个更小的值(最小堆)或者更大的值(最大堆)赋值给一个节点。由于这个操作破坏了堆属性,所以需要使用shiftUp()来修复堆属性。
上面所有的操作的时间复杂度都是 O(log n),因为 shiftUp 和 shiftDown 都很费时。还有少数一些操作需要更多的时间:
search(value):堆不是为快速搜索而建立的,但是replace()和removeAtIndex()操作需要找到节点在数组中的index,所以你需要先找到这个index。时间复杂度:O(n)。buildHeap(array):通过反复调用insert()方法将一个(无序)数组转换成一个堆。如果你足够聪明,你可以在 O(n) 时间内完成。- 堆排序:由于堆就是一个数组,我们可以使用它独特的属性将数组从低到高排序。时间复杂度:O(n lg n)。
堆还有一个 peek() 方法,不用删除节点就返回最大值(最大堆)或者最小值(最小堆)。时间复杂度 O(1) 。
注意:到目前为止,堆的常用操作还是使用
insert()插入一个新的元素,和通过remove()输出根节点。两者的时间复杂度都是O(log n)。其其他的操作是用于支持更高级的应用,比如说建立一个优先队列。
插入(重点)
我们通过一个插入例子来看看插入操作的细节。我们将数字 16 插入到这个堆中:
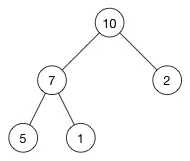
堆的数组是: [ 10, 7, 2, 5, 1 ]
第一股是将新的元素插入到数组的尾部。数组变成:
[ 10, 7, 2, 5, 1, 16 ]
相应的树变成了:
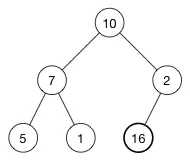
16 被添加最后一行的第一个空位。
不行的是,现在堆属性不满足,因为 2 在 16 的上面,我们需要将大的数字在上面(这是一个最大堆)
为了恢复堆属性,我们需要交换 16 和 2。
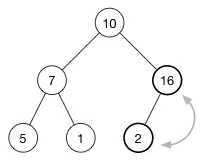
现在还没有完成,因为 10 也比 16 小。我们继续交换我们的插入元素和它的父节点,直到它的父节点比它大或者我们到达树的顶部。这就是所谓的 shift-up,每一次插入操作后都需要进行。它将一个太大或者太小的数字“浮起”到树的顶部。
最后我们得到的堆:
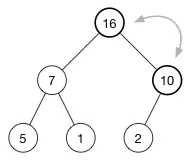
现在每一个父节点都比它的子节点大。
删除根节点(重点)
我们将这个树中的 (10) 删除:
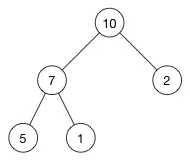
现在顶部有一个空的节点,怎么处理?
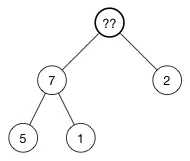
(重点) 当插入节点的时候,我们将新的值返给数组的尾部。现在我们来做相反的事情:我们取出数组中的最后一个元素,将它放到树的顶部,然后再修复堆属性。
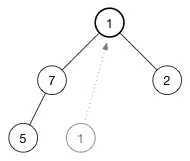
(1)。为了保持最大堆的堆属性,我们需要树的顶部是最大的数据。现在有两个数字可用于交换 7 和 2。我们选择这两者中的较大者称为最大值放在树的顶部,所以交换 7 和 1,现在树变成了: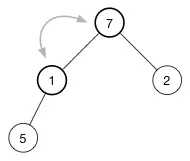
继续调整堆直到该节点没有任何子节点或者它比两个子节点都要大为止。对于我们的堆,我们只需要再有一次交换就恢复了堆属性:
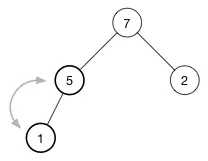
删除任意节点
绝大多数时候你需要删除的是堆的根节点,因为这就是堆的设计用途。
但是,删除任意节点也很有用。这是 remove() 的通用版本,它可能会使用到 shiftDown 和 shiftUp。
我们还是用前面的例子,删除 (7):
对应的数组是
[ 10, 7, 2, 5, 1 ]
你知道,移除一个元素会破坏最大堆或者最小堆属性。我们需要将删除的元素和最后一个元素交换:
[ 10, 1, 2, 5, 7 ]
最后一个元素就是我们需要返回的元素;然后调用 removeLast() 来将它删除。 (1) 比它的子节点小,所以需要 shiftDown() 来修复。
然而,shift down 不是我们要处理的唯一情况。也有可能我们需要 shift up。考虑一下从下面的堆中删除 (5) 会发生什么:
现在 (5) 和 (8) 交换了。因为 (8) 比它的父节点大,我们需要 shiftUp()。
以上是关于数据结构中的堆(Heap)的主要内容,如果未能解决你的问题,请参考以下文章