带你玩转Python爬虫(胆小者勿进)千万别做坏事·······
Posted 阿玥的小东东
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了带你玩转Python爬虫(胆小者勿进)千万别做坏事·······相关的知识,希望对你有一定的参考价值。
这节课很危险,哈哈哈哈,逗你们玩的
目录

写在前面
今天给大家找了很多我之前学习爬虫时候的资料,虽然我现在不玩爬虫了(害怕),但是大家还是可以去查阅啥的哈,最后求大家给个关注,冲冲W粉,谢谢!!!!
1 了解robots.txt
1.1 基础理解
robots.txt是一个纯文本文件,在这个文件中网站管理者可以声明该网站中不想被robots访问的部分,或者指定搜索引擎只收录指定的内容,一般域名后加/robots.txt,就可以获取
当一个搜索机器人(有的叫搜索蜘蛛)访问一个站点时,它会首先检查该站点根目录下是否存在robots.txt,如果存在,搜索机器人就会按照该文件中的内容来确定访问的范围;如果该文件不存在,那么搜索机器人就沿着链接抓取
另外,robots.txt必须放置在一个站点的根目录下,而且文件名必须全部小写。robots.txt写作语法
首先,我们来看一个robots.txt范例:https://fanyi.youdao.com/robots.txt
访问以上具体地址,我们可以看到robots.txt的具体内容如下
User-agent: Mediapartners-Google
Disallow:
User-agent: *
Allow: /fufei
Allow: /rengong
Allow: /web2/index.html
Allow: /about.html
Allow: /fanyiapi
Allow: /openapi
Disallow: /app
Disallow: /?
以上文本表达的意思是允许所有的搜索机器人访问fanyi.youdao.com站点下的所有文件
具体语法分析:User-agent:后面为搜索机器人的名称,后面如果是*,则泛指所有的搜索机器人;Disallow:后面为不允许访问的文件目录
1.2 使用robots.txt
robots.txt自身是一个文本文件。它必须位于域名的根目录中并被命名为robots.txt。位于子目录中的 robots.txt 文件无效,因为漫游器只在域名的根目录中查找此文件。例如,http://www.example.com/robots.txt 是有效位置,http://www.example.com/mysite/robots.txt 则不是有效位置
2 Cookie
由于http/https协议特性是无状态特性,因此需要服务器在客户端写入cookie,可以让服务器知道此请求是在什么样的状态下发生
2.1 两种cookie处理方式
cookie简言之就是让服务器记录客户端的相关状态信息,有两种方式:
- 手动处理
通过抓包工具获取cookie值,然后将该值封装到headers中
headers=
'cookie':"...."
在发起请求时把cookie封装进去
- 自动处理
自动处理时,要明白cookie的值来自服务器端,在模拟登陆post后,服务器端创建并返回给客户端
主要是通过session会话对象来操作cookie,session作用:可以进行请求的发送;如果请求过程中产生了cookie会自动被存储或携带在该session对象中
创建session对象:session=requests.Session(),使用session对象进行模拟登陆post请求发送(cookie会被存储在session中)
发送session请求:session.post()在发送时session对象对要请求的页面对应get请求进行发送(携带了cookie)
3 常用爬虫方法
用python爬取数据解析原理:
- 标签定位
- 提取标签、标签属性中存储的数据值
3.1 bs4
3.1.1 基础介绍
bs4进行网页数据解析bs4解析原理:
- 通过实例化一个
BeautifulSoup对象,并且将页面源码数据加载到该对象中 - 通过调用
BeautifulSoup对象中相关的属性或者方法进行标签定位和数据提取
环境安装:
pip install bs4
pip install lxml
3.1.2 bs4使用
3.1.2.1 获取解析对象
如何实例化BeautifulSoup对象:
导包from bs4 import BeautifulSoup
对象的实例化,有两种,本地和远程:
- 将本地的
html文档中的数据加载到该对象中
page_text = response.text
soup=BeautifulSoup(page_text,'lxml')
3.1.2.2 使用bs4解析
使用bs4提供的用于数据解析的方法和属性:
-
soup.tagName:返回的是文档中第一次出现的tagName对应的标签,比如soup.a获取第一次出现的a标签信息 -
soup.find():
在使用find('tagName')效果是等同于soup.tagName;
进行属性定位,soup.find(‘div’,class_(或id或attr)='song'):示例就是定位带有class='song'的div标签,class_必须有下划线是为了规避python关键字
还可以是其他比如:soup.find(‘div’,id='song'):定位id是song的div标签soup.find(‘div’,attr='song'):定位attr是song的div标签 -
soup.find_all('tagName'):返回符合要求的所有标签(列表)
select用法:
select('某种选择器(id,class,标签..选择器)')返回的是一个列表
获取标签之间文本数据
可以使用text或string或get_text(),主要区别:
text或get_text()可以获取某一个标签中所有的文本内容string:只可以获取该标签下面直系的文本内容
获取标签中属性值:
- 使用
python获取字典方法获取,比如:soup.a['href']就是获取<a>中的href值
3.1.2 使用例子
import os
import requests
from bs4 import BeautifulSoup
headers=
'User-Agent':"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36"
url="https://www.test.com/chaxun/zuozhe/77.html"
def getPoems():
res= requests.get(url=url,headers=headers)
res.encoding='UTF-8'
page_text=res.text
#在首页解析出章节
soup = BeautifulSoup(page_text,'lxml')
shici_list = soup.select(".shici_list_main > h3 > a")
shici_name=[]
for li in shici_list:
data_url = "https://www.test.com"+li['href']
# print(li.string+"======="+data_url)
shici_name.append(li.string)
detail_res = requests.get(url=data_url,headers=headers)
detail_res.encoding='UTF-8'
detail_page_text=detail_res.text
detail_soup = BeautifulSoup(detail_page_text,'lxml')
detail_content = detail_soup.find("div",class_="item_content").text
# print(detail_content)
with open("./shici.txt",'a+',encoding= 'utf8') as file:
if shici_name.count(li.string)==1:
file.write(li.string)
file.write(detail_content+"\\n")
print(li.string+"下载完成!!!!")
if __name__=="__main__":
getPoems()
3.2 xpath
xpath解析:最常用且最便捷高效的一种解析方式
3.2.1 xpath基础介绍
xpath解析原理:
- 实例化一个
etree的对象,且需要将被解析的页面源码数据加载到该对象中 - 调用
etree对象中的xpath方法结合着xpath表达式实现标签的定位和内容的捕获
环境安装:
pip install lxml
3.2.2 xpath使用
3.2.2.1 获取相关对象
先实例化一个etree对象,先导包:from lxml import etree
- 将本地的
html文档中的源码数据加载到etree对象中
tree=etree.parse(filepath)
- 可以将从互联网上获取的源码数据加载到该对象中
page_text = response.text
tree=etree.HTML(page_text)
3.2.2.2 通过xpath解析
通过xpath表达式:tree.xpath(xpath表达式):xpath表达式:
/:表示的是从根节点开始定位,表示的是一个层级//:表示的是多个层级,可以表示从任意位置开始定位- 属性定位:
tag[@attrName='attrValue']
比如//div[@class='song']表示的是获取到任意位置class='song'的<div>标签 - 索引定位:
//div[@class='song']/p[3]表示的是任意位置class='song'的<div>标签下面的第三个<p>标签,注意:索引定位是从1开始的 - 取文本:
/text():获取的是标签中直系文本内容//text():标签中非直系的文本内容(所有的文本内容) - 取属性:
/@attrName:获取某个属性的值,比如://img/@src获取任意的img标签的src值
注意:xpath中也可以使用管道符|,如果第一个没有取到就去取管道符后面的,比如:xpath('//div/b/text() | //div/a/test()'),如果管道符左边生效就取左边,若右边生效就取右边注意:xpath中不能出现tbody标签
3.2.3 使用例子
import requests
from lxml import etree
import re
headers=
'User-Agent':"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36"
url="https://www.test.com/chaxun/zuozhe/77.html"
def getPoemsByXpath():
res= requests.get(url=url,headers=headers)
res.encoding='UTF-8'
page_text=res.text
#在首页解析出章节
tree = etree.HTML(page_text)
shici_list = tree.xpath("//div[@class='shici_list_main']")
shici_name_out=''
for shici in shici_list:
#此处使用相对路径
shici_name=shici.xpath("h3/a/text()")[0]
# print(shici_name)
shici_text_list=shici.xpath("div//text()")
# print(shici_text_list)
with open("./shicibyxpath.txt",'a+',encoding= 'utf8') as file:
if shici_name_out!=shici_name:
file.write(shici_name+"\\n")
for text in shici_text_list:
if "展开全文"==text or "收起"==text or re.match(r'^\\s*$',text)!=None or re.match(r'^\\n\\s*$',text)!=None:
continue
re_text=text.replace(' ','').replace('\\n','')
file.write(re_text+"\\n")
if shici_name_out!=shici_name:
print(shici_name+"下载完成!!!!")
shici_name_out=shici_name
if __name__=="__main__":
getPoemsByXpath()写在最后

不要去干坏事,因为爬虫程序采集到公民的姓名、身份证件号码、通信通讯联系方式、住址、账号密码、财产状况、行踪轨迹等个人信息,并将之用于非法途径的,则肯定构成非法获取公民个人信息的违法行为。也就是说你爬虫爬取信息没有问题,但不能涉及到个人的隐私问题,如果涉及了并且通过非法途径收益了,那肯定是违法行为。另外,还有下列三种情况,爬虫有可能违法,严重的甚至构成犯罪:爬虫程序规避网站经营者设置的反爬虫措施或者破解服务器防抓取措施,非法获取相关信息,情节严重的,有可能构成“非法获取计算机信息系统数据罪”。爬虫程序干扰被访问的网站或系统正常运营,后果严重的,触犯刑法,构成“破坏计算机信息系统罪”爬虫采集的信息属于公民个人信息的,有可能构成非法获取公民个人信息的违法行为,情节严重的,有可能构成“侵犯公民个人信息罪”
所以,学习Python爬虫是没问题的,但是心一定要正!!
Python所有方向的学习路线,你们要的知识体系在这,千万别做了无用功
Python所有方向的学习路线,今天分享给大家!(高清图文末获取)

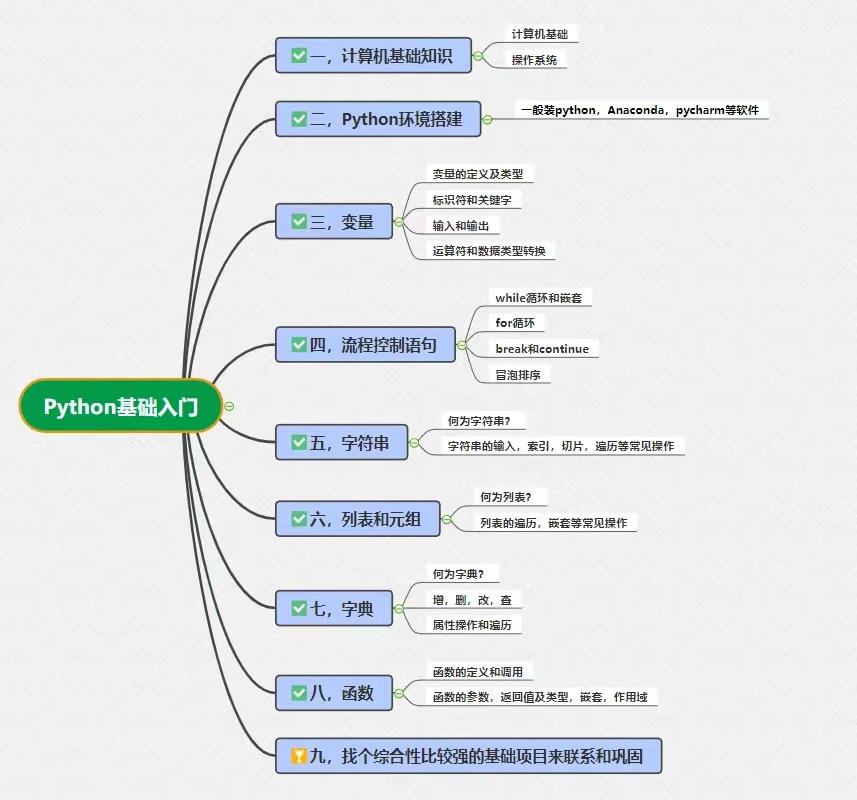
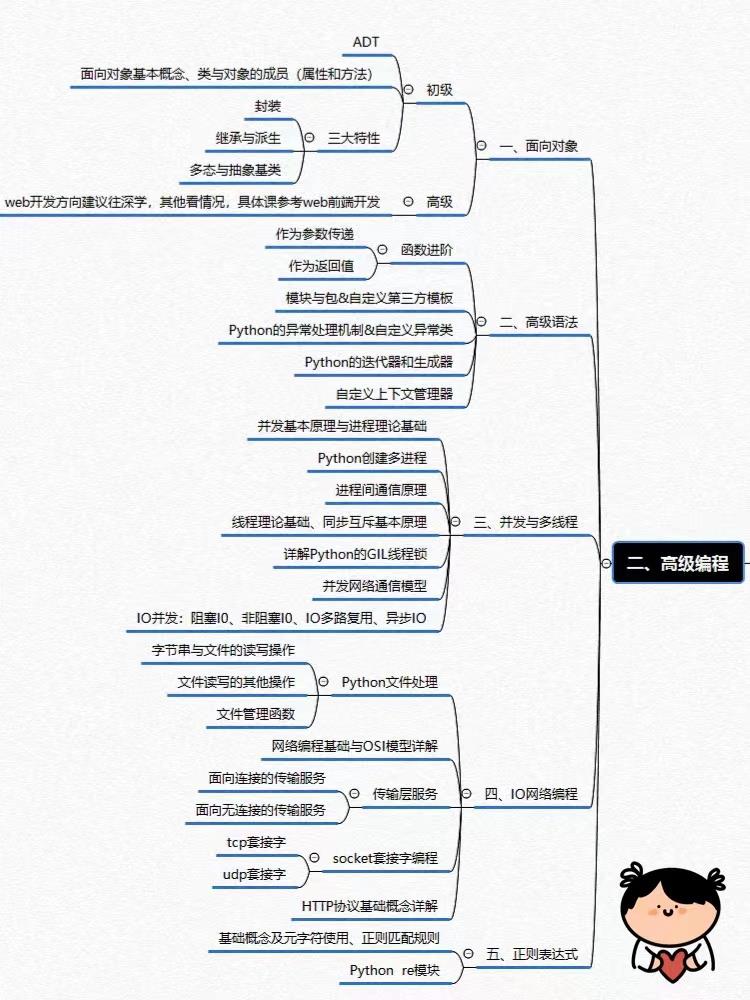
一、Python入门
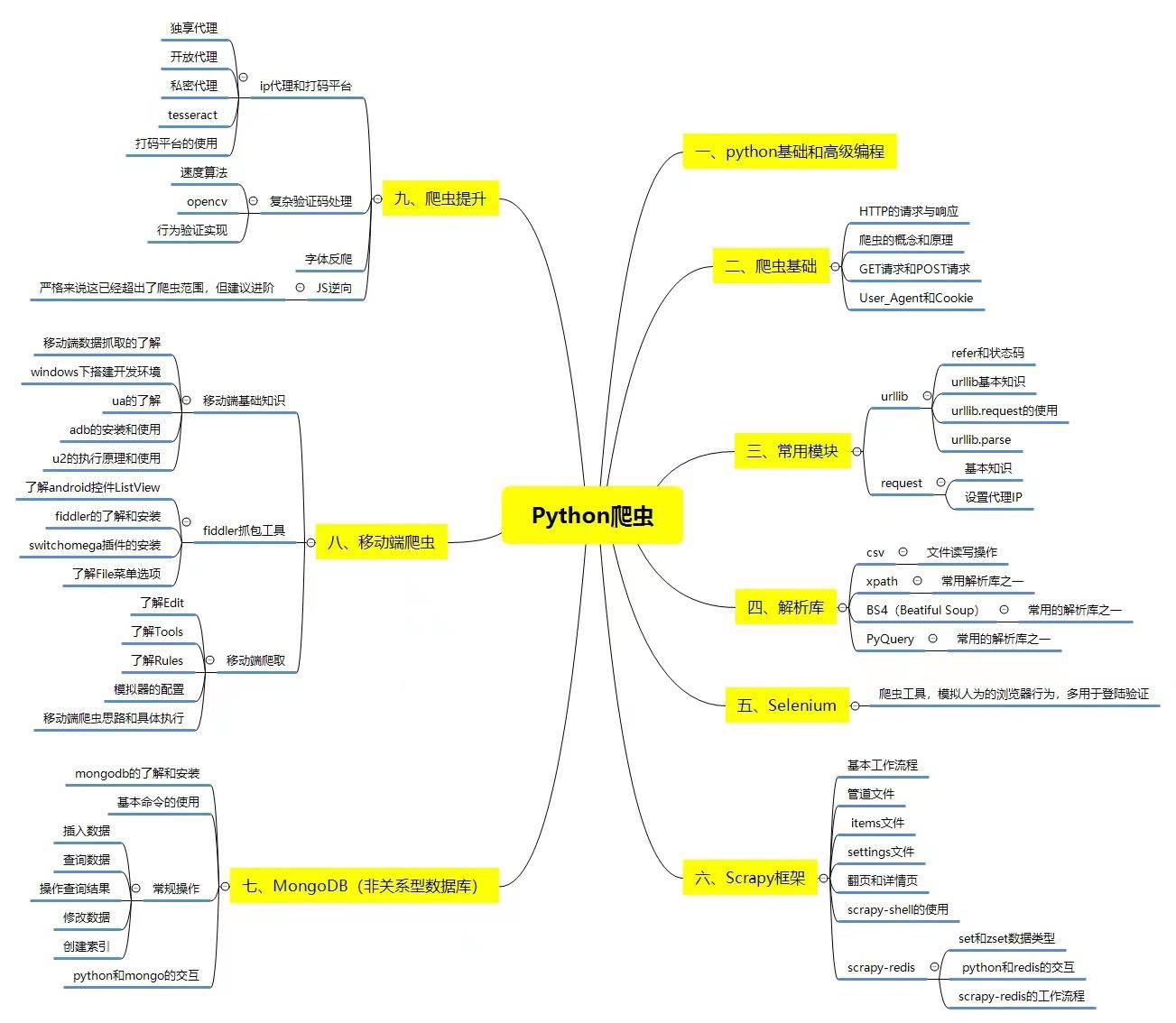
二、爬虫
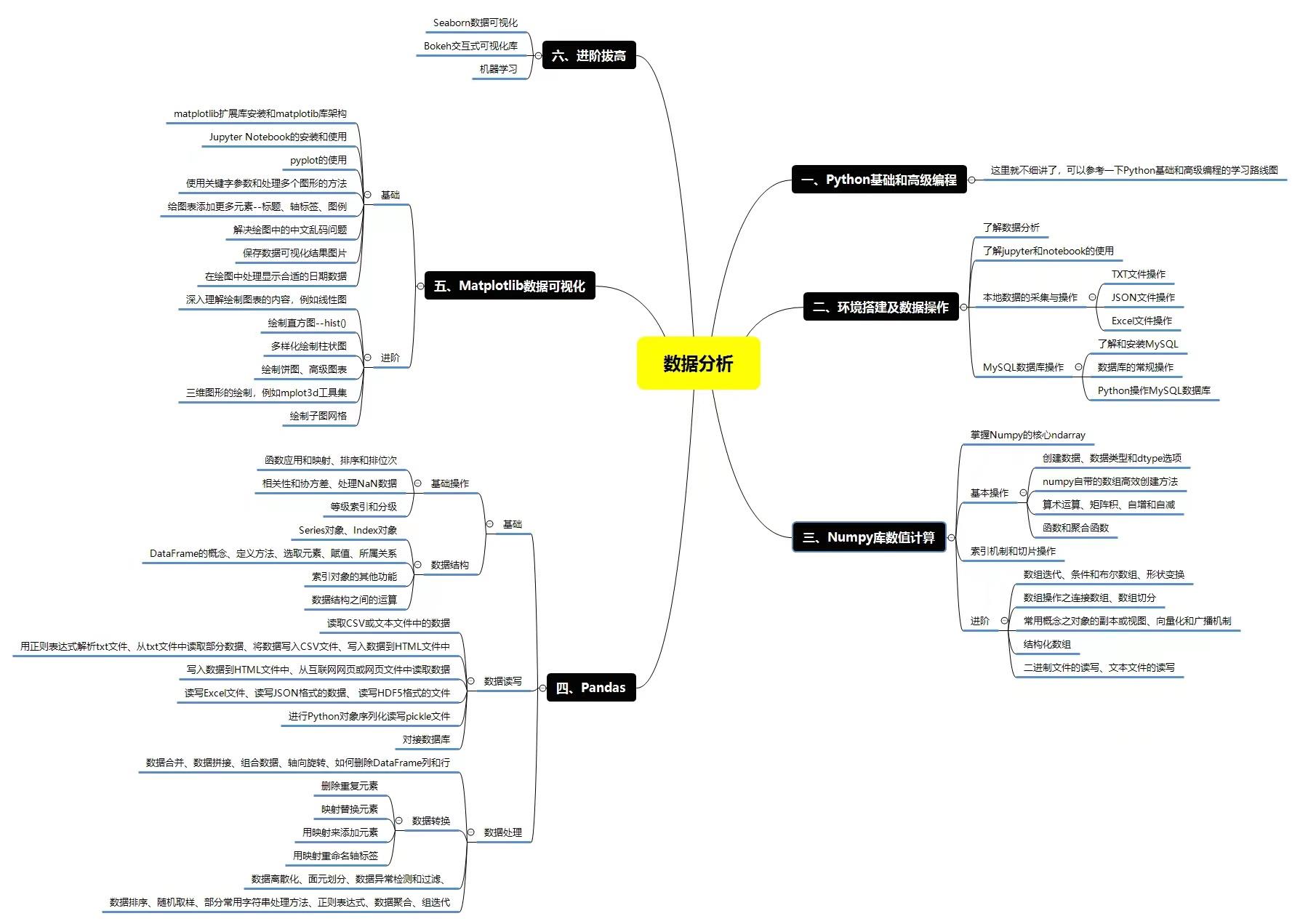
三、数据分析
四、自动化测试
五、机器学习
这份完整版的Python全套学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

以上是关于带你玩转Python爬虫(胆小者勿进)千万别做坏事·······的主要内容,如果未能解决你的问题,请参考以下文章